 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerLin: A Discovery Engine for Photonic and Hybrid Quantum Machine Learning
Feb 11, 2026Identifying where quantum models may offer practical benefits in near term quantum machine learning (QML) requires moving beyond isolated algorithmic proposals toward systematic and empirical exploration across models, datasets, and hardware constraints. We introduce MerLin, an open source framework designed as a discovery engine for photonic and hybrid quantum machine learning. MerLin integrates optimized strong simulation of linear optical circuits into standard PyTorch and scikit learn workflows, enabling end to end differentiable training of quantum layers. MerLin is designed around systematic benchmarking and reproducibility. As an initial contribution, we reproduce eighteen state of the art photonic and hybrid QML works spanning kernel methods, reservoir computing, convolutional and recurrent architectures, generative models, and modern training paradigms. These reproductions are released as reusable, modular experiments that can be directly extended and adapted, establishing a shared experimental baseline consistent with empirical benchmarking methodologies widely adopted in modern artificial intelligence. By embedding photonic quantum models within established machine learning ecosystems, MerLin allows practitioners to leverage existing tooling for ablation studies, cross modality comparisons, and hybrid classical quantum workflows. The framework already implements hardware aware features, allowing tests on available quantum hardware while enabling exploration beyond its current capabilities, positioning MerLin as a future proof co design tool linking algorithms, benchmarks, and hardware.
OpenNMT: Neural Machine Translation Toolkit
May 28, 2018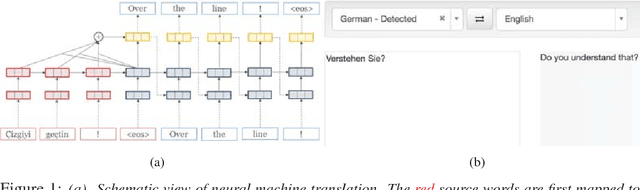

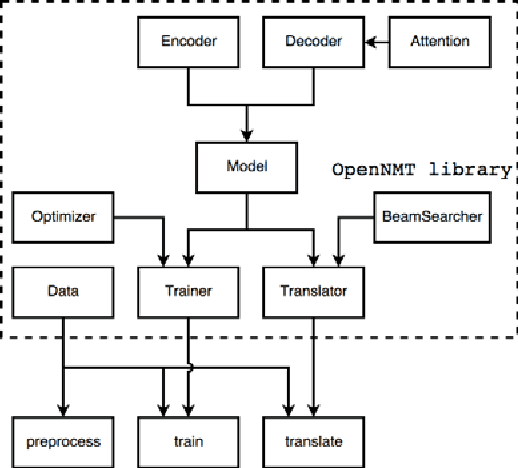

OpenNMT is an open-source toolkit for neural machine translation (NMT). The system prioritizes efficiency, modularity, and extensibility with the goal of supporting NMT research into model architectures, feature representations, and source modalities, while maintaining competitive performance and reasonable training requirements. The toolkit consists of modeling and translation support, as well as detailed pedagogical documentation about the underlying techniques. OpenNMT has been used in several production MT systems, modified for numerous research papers, and is implemented across several deep learning frameworks.
Boosting Neural Machine Translation
Oct 03, 2017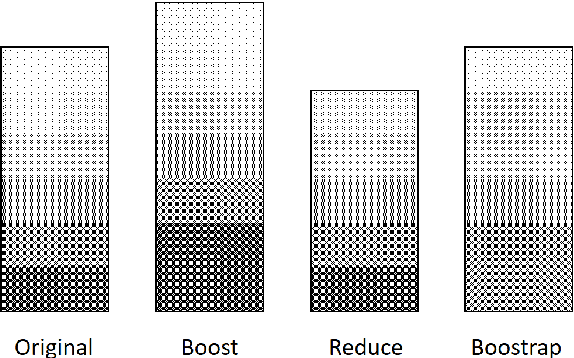
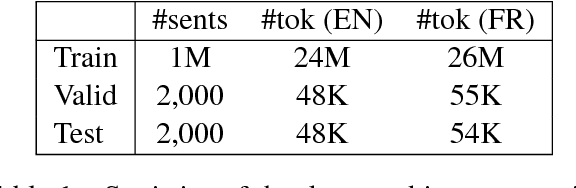
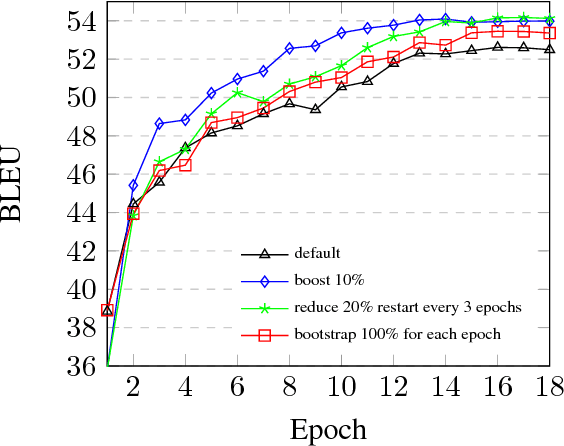
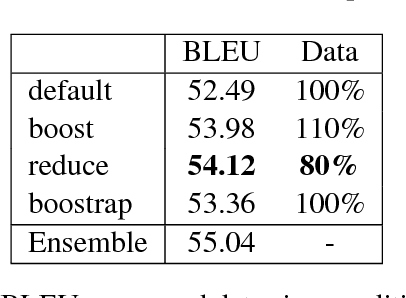
Training efficiency is one of the main problems for Neural Machine Translation (NMT). Deep networks need for very large data as well as many training iterations to achieve state-of-the-art performance. This results in very high computation cost, slowing down research and industrialisation. In this paper, we propose to alleviate this problem with several training methods based on data boosting and bootstrap with no modifications to the neural network. It imitates the learning process of humans, which typically spend more time when learning "difficult" concepts than easier ones. We experiment on an English-French translation task showing accuracy improvements of up to 1.63 BLEU while saving 20% of training time.
OpenNMT: Open-source Toolkit for Neural Machine Translation
Sep 12, 2017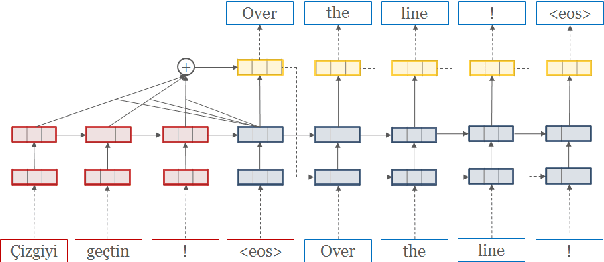

We introduce an open-source toolkit for neural machine translation (NMT) to support research into model architectures, feature representations, and source modalities, while maintaining competitive performance, modularity and reasonable training requirements.
SYSTRAN Purely Neural MT Engines for WMT2017
Sep 12, 2017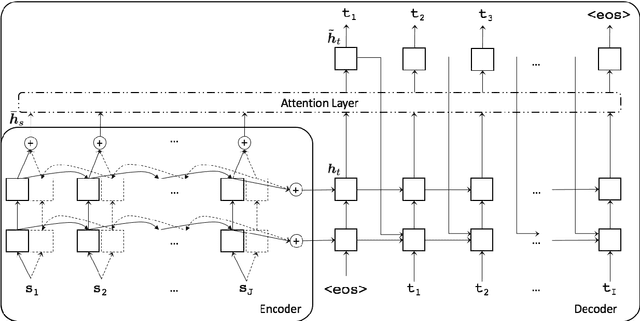
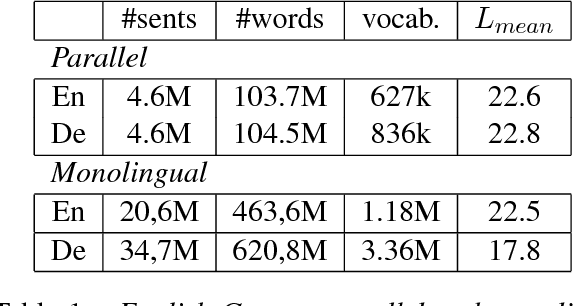
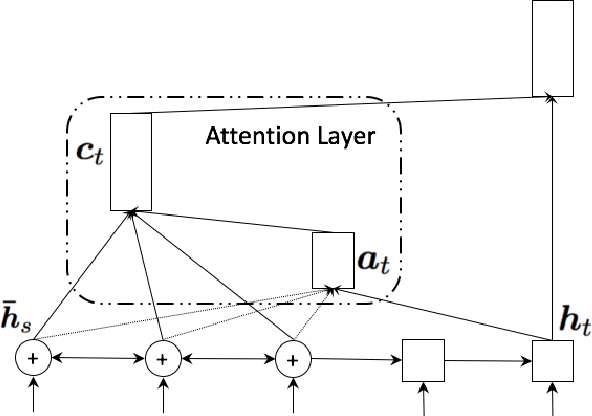

This paper describes SYSTRAN's systems submitted to the WMT 2017 shared news translation task for English-German, in both translation directions. Our systems are built using OpenNMT, an open-source neural machine translation system, implementing sequence-to-sequence models with LSTM encoder/decoders and attention. We experimented using monolingual data automatically back-translated. Our resulting models are further hyper-specialised with an adaptation technique that finely tunes models according to the evaluation test sentences.
Domain Control for Neural Machine Translation
Sep 12, 2017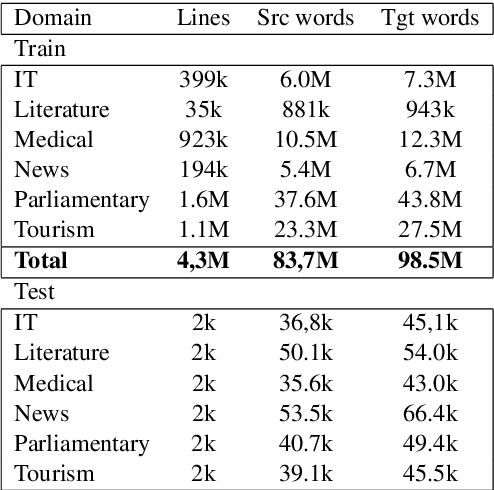
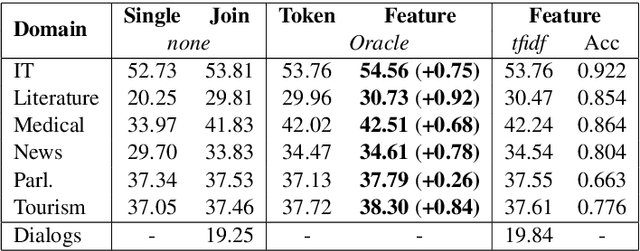

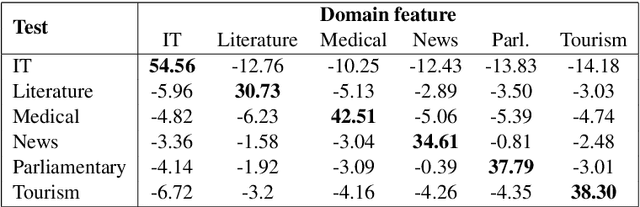
Machine translation systems are very sensitive to the domains they were trained on. Several domain adaptation techniques have been deeply studied. We propose a new technique for neural machine translation (NMT) that we call domain control which is performed at runtime using a unique neural network covering multiple domains. The presented approach shows quality improvements when compared to dedicated domains translating on any of the covered domains and even on out-of-domain data. In addition, model parameters do not need to be re-estimated for each domain, making this effective to real use cases. Evaluation is carried out on English-to-French translation for two different testing scenarios. We first consider the case where an end-user performs translations on a known domain. Secondly, we consider the scenario where the domain is not known and predicted at the sentence level before translating. Results show consistent accuracy improvements for both conditions.
OpenNMT: Open-Source Toolkit for Neural Machine Translation
Mar 06, 2017We describe an open-source toolkit for neural machine translation (NMT). The toolkit prioritizes efficiency, modularity, and extensibility with the goal of supporting NMT research into model architectures, feature representations, and source modalities, while maintaining competitive performance and reasonable training requirements. The toolkit consists of modeling and translation support, as well as detailed pedagogical documentation about the underlying techniques.
Domain specialization: a post-training domain adaptation for Neural Machine Translation
Dec 19, 2016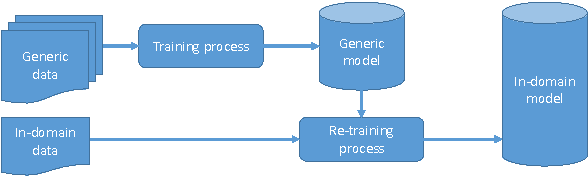
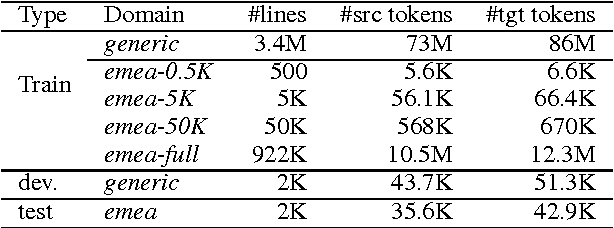

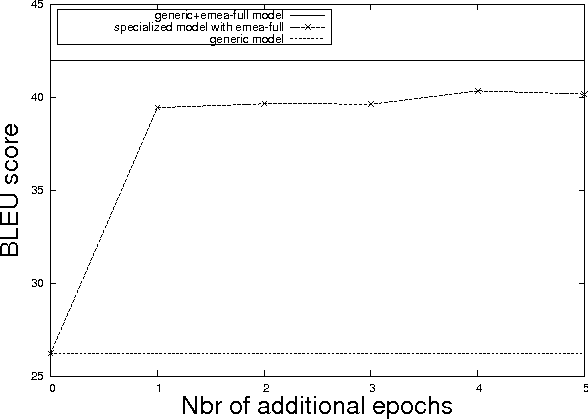
Domain adaptation is a key feature in Machine Translation. It generally encompasses terminology, domain and style adaptation, especially for human post-editing workflows in Computer Assisted Translation (CAT). With Neural Machine Translation (NMT), we introduce a new notion of domain adaptation that we call "specialization" and which is showing promising results both in the learning speed and in adaptation accuracy. In this paper, we propose to explore this approach under several perspectives.
Neural Machine Translation from Simplified Translations
Dec 19, 2016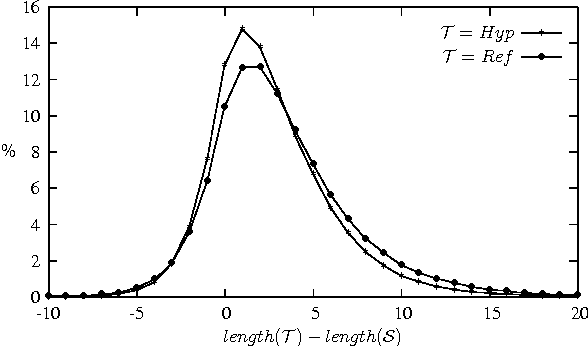

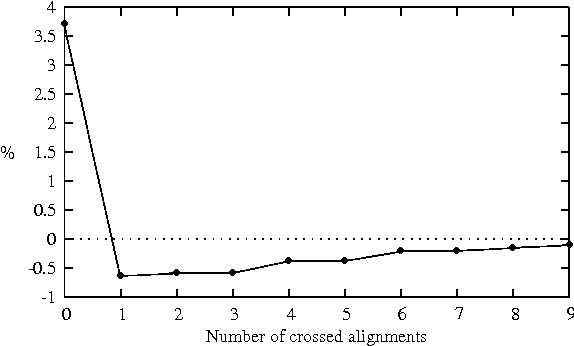

Text simplification aims at reducing the lexical, grammatical and structural complexity of a text while keeping the same meaning. In the context of machine translation, we introduce the idea of simplified translations in order to boost the learning ability of deep neural translation models. We conduct preliminary experiments showing that translation complexity is actually reduced in a translation of a source bi-text compared to the target reference of the bi-text while using a neural machine translation (NMT) system learned on the exact same bi-text. Based on knowledge distillation idea, we then train an NMT system using the simplified bi-text, and show that it outperforms the initial system that was built over the reference data set. Performance is further boosted when both reference and automatic translations are used to learn the network. We perform an elementary analysis of the translated corpus and report accuracy results of the proposed approach on English-to-French and English-to-German translation tasks.
SYSTRAN's Pure Neural Machine Translation Systems
Oct 18, 2016
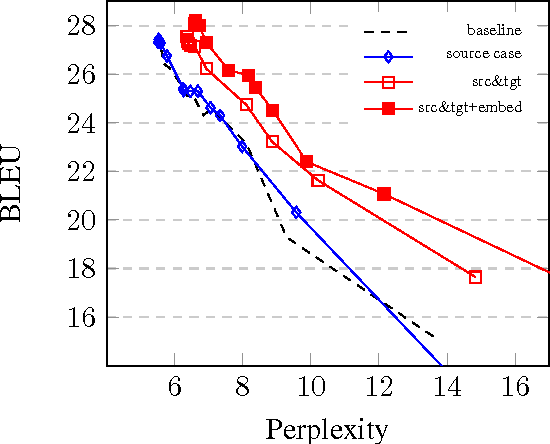
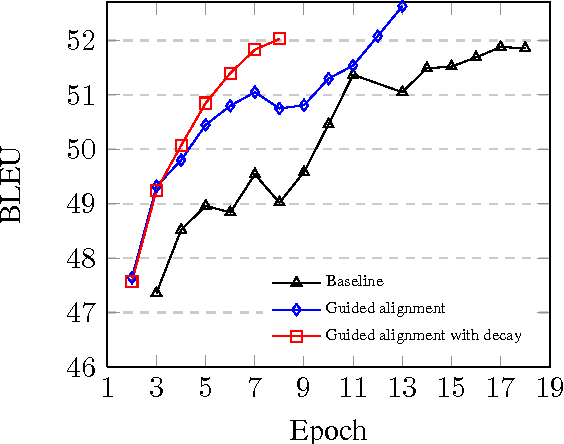
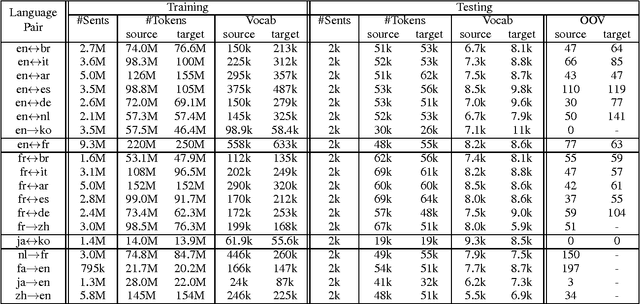
Since the first online demonstration of Neural Machine Translation (NMT) by LISA, NMT development has recently moved from laboratory to production systems as demonstrated by several entities announcing roll-out of NMT engines to replace their existing technologies. NMT systems have a large number of training configurations and the training process of such systems is usually very long, often a few weeks, so role of experimentation is critical and important to share. In this work, we present our approach to production-ready systems simultaneously with release of online demonstrators covering a large variety of languages (12 languages, for 32 language pairs). We explore different practical choices: an efficient and evolutive open-source framework; data preparation; network architecture; additional implemented features; tuning for production; etc. We discuss about evaluation methodology, present our first findings and we finally outline further work. Our ultimate goal is to share our expertise to build competitive production systems for "generic" translation. We aim at contributing to set up a collaborative framework to speed-up adoption of the technology, foster further research efforts and enable the delivery and adoption to/by industry of use-case specific engines integrated in real production workflows. Mastering of the technology would allow us to build translation engines suited for particular needs, outperforming current simplest/uniform systems.