 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Neural Machine Translation
Oct 03, 2017
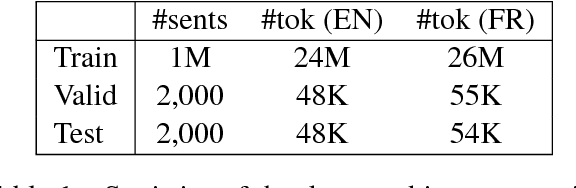
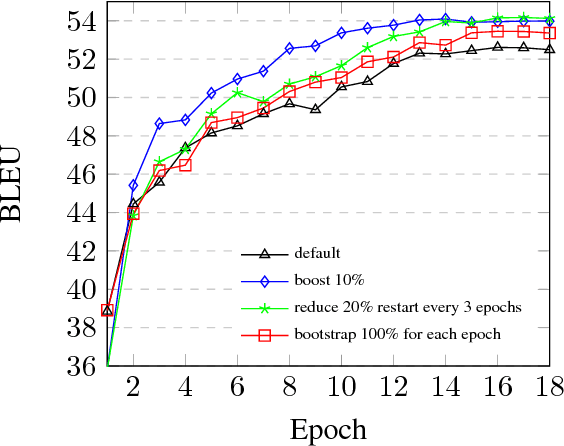
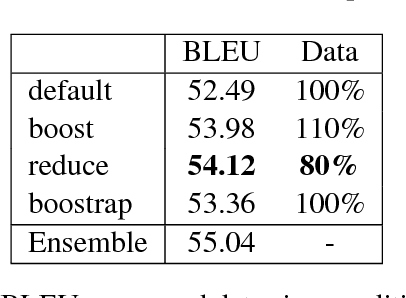
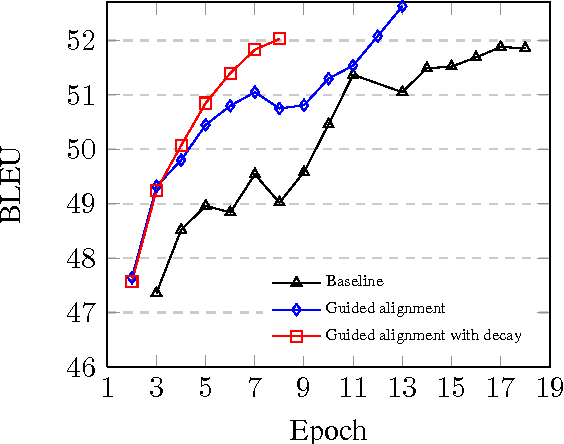
Training efficiency is one of the main problems for Neural Machine Translation (NMT). Deep networks need for very large data as well as many training iterations to achieve state-of-the-art performance. This results in very high computation cost, slowing down research and industrialisation. In this paper, we propose to alleviate this problem with several training methods based on data boosting and bootstrap with no modifications to the neural network. It imitates the learning process of humans, which typically spend more time when learning "difficult" concepts than easier ones. We experiment on an English-French translation task showing accuracy improvements of up to 1.63 BLEU while saving 20% of training time.
SYSTRAN Purely Neural MT Engines for WMT2017
Sep 12, 2017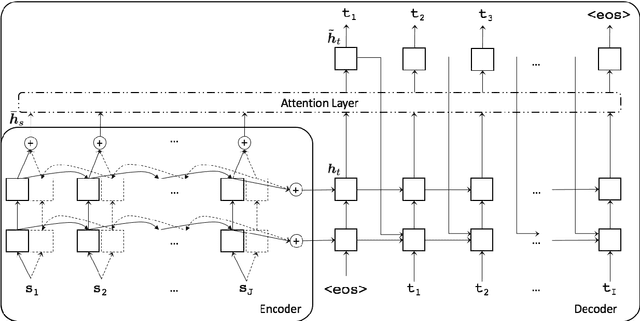
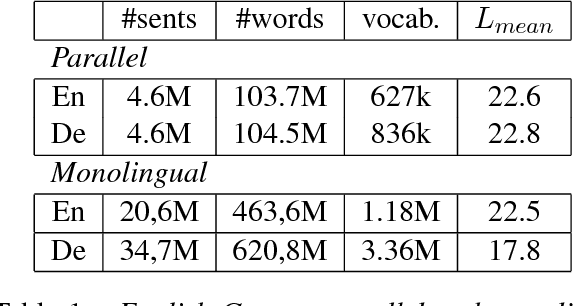
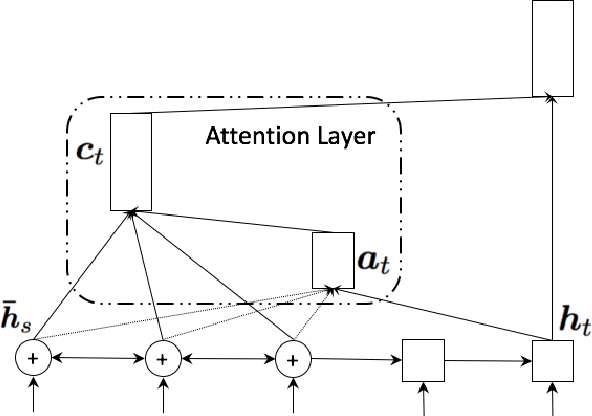

This paper describes SYSTRAN's systems submitted to the WMT 2017 shared news translation task for English-German, in both translation directions. Our systems are built using OpenNMT, an open-source neural machine translation system, implementing sequence-to-sequence models with LSTM encoder/decoders and attention. We experimented using monolingual data automatically back-translated. Our resulting models are further hyper-specialised with an adaptation technique that finely tunes models according to the evaluation test sentences.
SYSTRAN's Pure Neural Machine Translation Systems
Oct 18, 2016
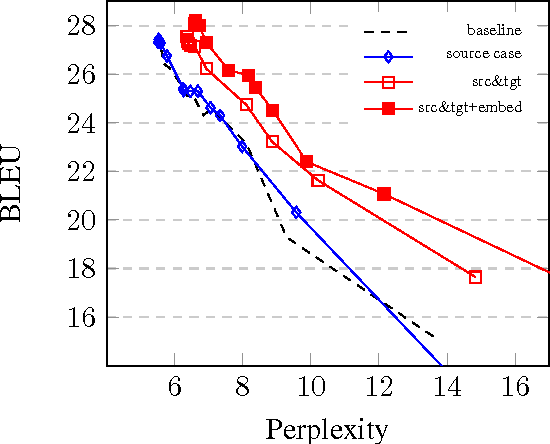
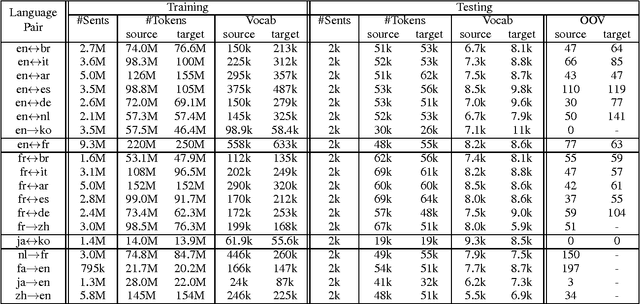
Since the first online demonstration of Neural Machine Translation (NMT) by LISA, NMT development has recently moved from laboratory to production systems as demonstrated by several entities announcing roll-out of NMT engines to replace their existing technologies. NMT systems have a large number of training configurations and the training process of such systems is usually very long, often a few weeks, so role of experimentation is critical and important to share. In this work, we present our approach to production-ready systems simultaneously with release of online demonstrators covering a large variety of languages (12 languages, for 32 language pairs). We explore different practical choices: an efficient and evolutive open-source framework; data preparation; network architecture; additional implemented features; tuning for production; etc. We discuss about evaluation methodology, present our first findings and we finally outline further work. Our ultimate goal is to share our expertise to build competitive production systems for "generic" translation. We aim at contributing to set up a collaborative framework to speed-up adoption of the technology, foster further research efforts and enable the delivery and adoption to/by industry of use-case specific engines integrated in real production workflows. Mastering of the technology would allow us to build translation engines suited for particular needs, outperforming current simplest/uniform systems.
Large-scale Multi-label Text Classification - Revisiting Neural Networks
May 15, 2014

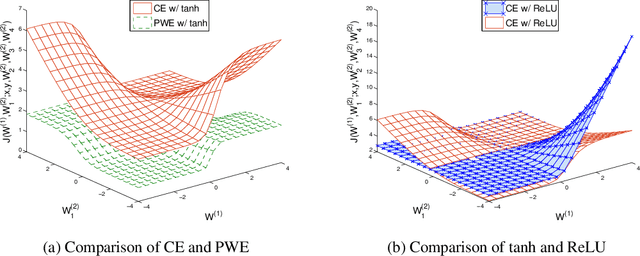
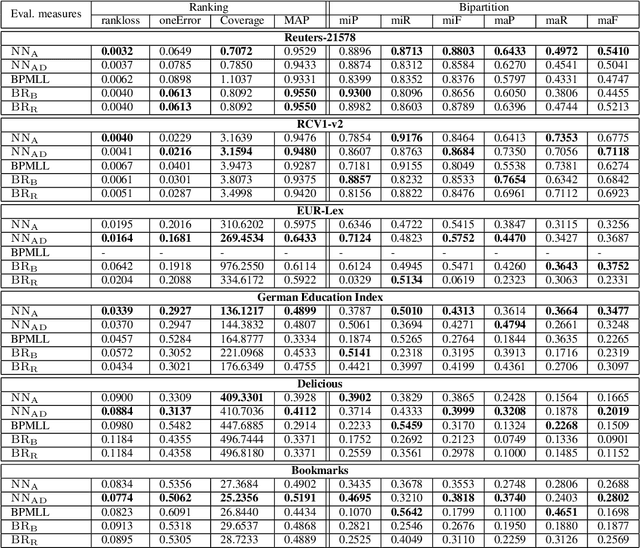
Neural networks have recently been proposed for multi-label classification because they are able to capture and model label dependencies in the output layer. In this work, we investigate limitations of BP-MLL, a neural network (NN) architecture that aims at minimizing pairwise ranking error. Instead, we propose to use a comparably simple NN approach with recently proposed learning techniques for large-scale multi-label text classification tasks. In particular, we show that BP-MLL's ranking loss minimization can be efficiently and effectively replaced with the commonly used cross entropy error function, and demonstrate that several advances in neural network training that have been developed in the realm of deep learning can be effectively employed in this setting. Our experimental results show that simple NN models equipped with advanced techniques such as rectified linear units, dropout, and AdaGrad perform as well as or even outperform state-of-the-art approaches on six large-scale textual datasets with diverse characteristics.