Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Neural Machine Translation
Paper and Code
Oct 03, 2017
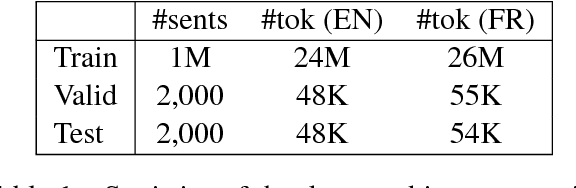
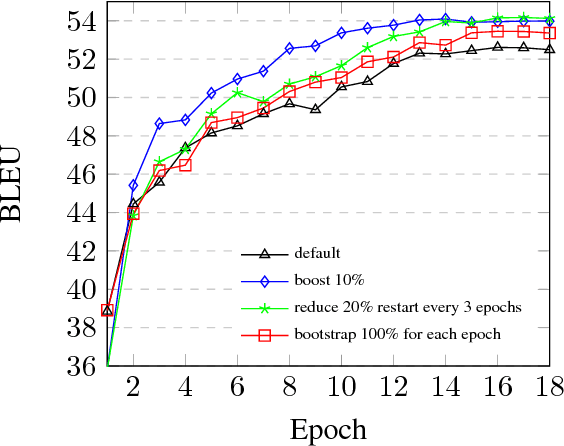
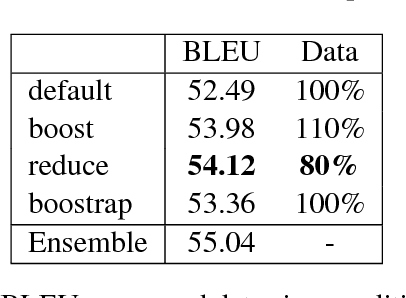
Training efficiency is one of the main problems for Neural Machine Translation (NMT). Deep networks need for very large data as well as many training iterations to achieve state-of-the-art performance. This results in very high computation cost, slowing down research and industrialisation. In this paper, we propose to alleviate this problem with several training methods based on data boosting and bootstrap with no modifications to the neural network. It imitates the learning process of humans, which typically spend more time when learning "difficult" concepts than easier ones. We experiment on an English-French translation task showing accuracy improvements of up to 1.63 BLEU while saving 20% of training time.
* published in IJCNLP 2017
View paper on