 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATLANTIS at SemEval-2025 Task 3: Detecting Hallucinated Text Spans in Question Answering
Aug 07, 2025



This paper presents the contributions of the ATLANTIS team to SemEval-2025 Task 3, focusing on detecting hallucinated text spans in question answering systems. Large Language Models (LLMs) have significantly advanced Natural Language Generation (NLG) but remain susceptible to hallucinations, generating incorrect or misleading content. To address this, we explored methods both with and without external context, utilizing few-shot prompting with a LLM, token-level classification or LLM fine-tuned on synthetic data. Notably, our approaches achieved top rankings in Spanish and competitive placements in English and German. This work highlights the importance of integrating relevant context to mitigate hallucinations and demonstrate the potential of fine-tuned models and prompt engineering.
A question-answering system for aircraft pilots' documentation
Nov 26, 2020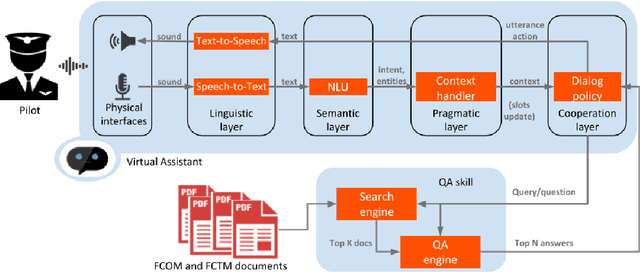

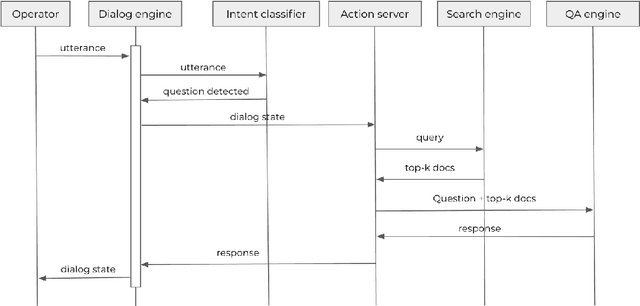
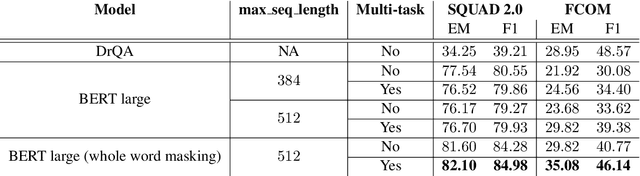
The aerospace industry relies on massive collections of complex and technical documents covering system descriptions, manuals or procedures. This paper presents a question answering (QA) system that would help aircraft pilots access information in this documentation by naturally interacting with the system and asking questions in natural language. After describing each module of the dialog system, we present a multi-task based approach for the QA module which enables performance improvement on a Flight Crew Operating Manual (FCOM) dataset. A method to combine scores from the retriever and the QA modules is also presented.
SYSTRAN Purely Neural MT Engines for WMT2017
Sep 12, 2017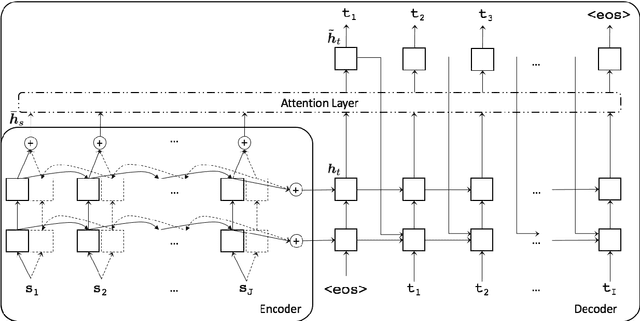

This paper describes SYSTRAN's systems submitted to the WMT 2017 shared news translation task for English-German, in both translation directions. Our systems are built using OpenNMT, an open-source neural machine translation system, implementing sequence-to-sequence models with LSTM encoder/decoders and attention. We experimented using monolingual data automatically back-translated. Our resulting models are further hyper-specialised with an adaptation technique that finely tunes models according to the evaluation test sentences.
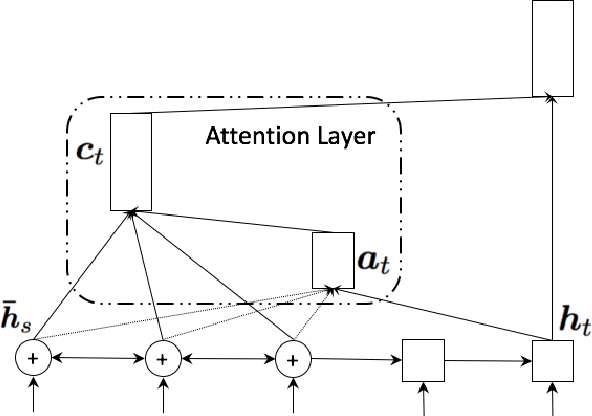
Domain Control for Neural Machine Translation
Sep 12, 2017

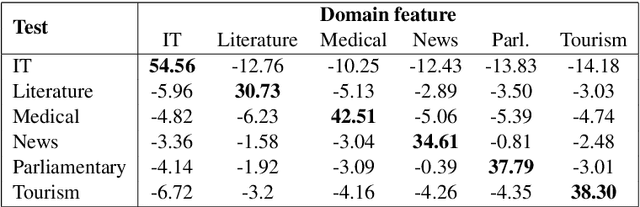
Machine translation systems are very sensitive to the domains they were trained on. Several domain adaptation techniques have been deeply studied. We propose a new technique for neural machine translation (NMT) that we call domain control which is performed at runtime using a unique neural network covering multiple domains. The presented approach shows quality improvements when compared to dedicated domains translating on any of the covered domains and even on out-of-domain data. In addition, model parameters do not need to be re-estimated for each domain, making this effective to real use cases. Evaluation is carried out on English-to-French translation for two different testing scenarios. We first consider the case where an end-user performs translations on a known domain. Secondly, we consider the scenario where the domain is not known and predicted at the sentence level before translating. Results show consistent accuracy improvements for both conditions.
SYSTRAN's Pure Neural Machine Translation Systems
Oct 18, 2016
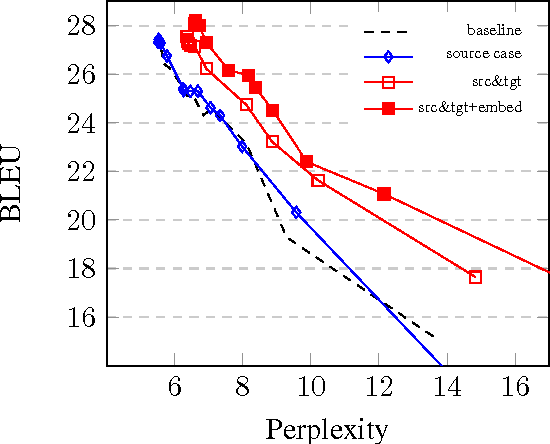
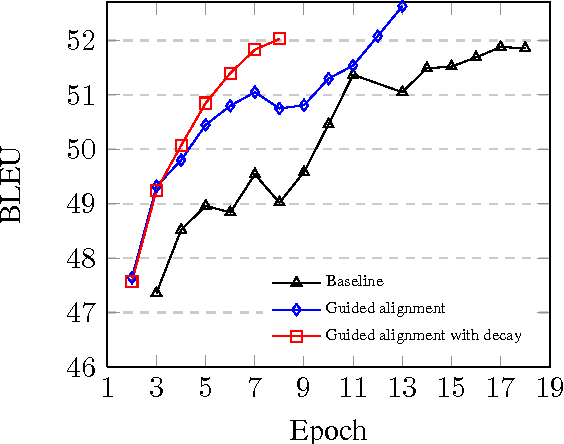
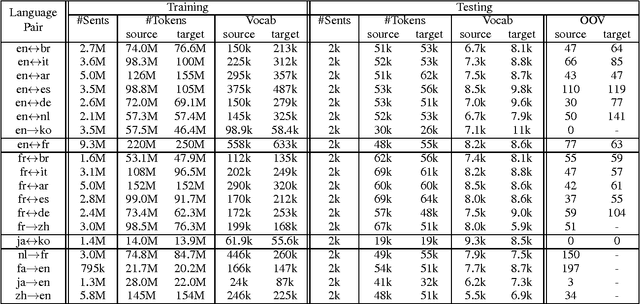
Since the first online demonstration of Neural Machine Translation (NMT) by LISA, NMT development has recently moved from laboratory to production systems as demonstrated by several entities announcing roll-out of NMT engines to replace their existing technologies. NMT systems have a large number of training configurations and the training process of such systems is usually very long, often a few weeks, so role of experimentation is critical and important to share. In this work, we present our approach to production-ready systems simultaneously with release of online demonstrators covering a large variety of languages (12 languages, for 32 language pairs). We explore different practical choices: an efficient and evolutive open-source framework; data preparation; network architecture; additional implemented features; tuning for production; etc. We discuss about evaluation methodology, present our first findings and we finally outline further work. Our ultimate goal is to share our expertise to build competitive production systems for "generic" translation. We aim at contributing to set up a collaborative framework to speed-up adoption of the technology, foster further research efforts and enable the delivery and adoption to/by industry of use-case specific engines integrated in real production workflows. Mastering of the technology would allow us to build translation engines suited for particular needs, outperforming current simplest/uniform systems.