 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot cross-modal transfer of Reinforcement Learning policies through a Global Workspace
Mar 07, 2024



Humans perceive the world through multiple senses, enabling them to create a comprehensive representation of their surroundings and to generalize information across domains. For instance, when a textual description of a scene is given, humans can mentally visualize it. In fields like robotics and Reinforcement Learning (RL), agents can also access information about the environment through multiple sensors; yet redundancy and complementarity between sensors is difficult to exploit as a source of robustness (e.g. against sensor failure) or generalization (e.g. transfer across domains). Prior research demonstrated that a robust and flexible multimodal representation can be efficiently constructed based on the cognitive science notion of a 'Global Workspace': a unique representation trained to combine information across modalities, and to broadcast its signal back to each modality. Here, we explore whether such a brain-inspired multimodal representation could be advantageous for RL agents. First, we train a 'Global Workspace' to exploit information collected about the environment via two input modalities (a visual input, or an attribute vector representing the state of the agent and/or its environment). Then, we train a RL agent policy using this frozen Global Workspace. In two distinct environments and tasks, our results reveal the model's ability to perform zero-shot cross-modal transfer between input modalities, i.e. to apply to image inputs a policy previously trained on attribute vectors (and vice-versa), without additional training or fine-tuning. Variants and ablations of the full Global Workspace (including a CLIP-like multimodal representation trained via contrastive learning) did not display the same generalization abilities.
A question-answering system for aircraft pilots' documentation
Nov 26, 2020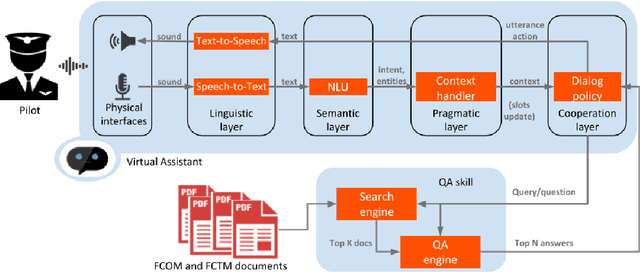

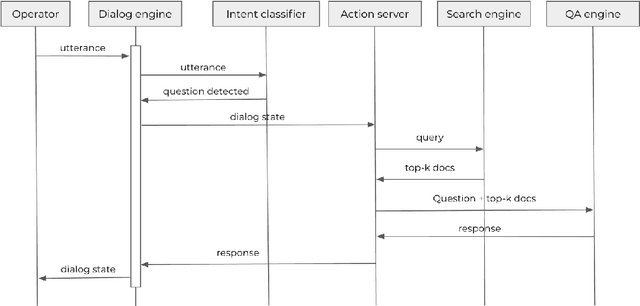
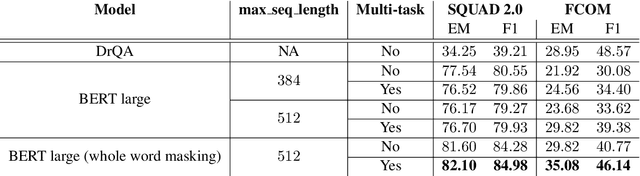
The aerospace industry relies on massive collections of complex and technical documents covering system descriptions, manuals or procedures. This paper presents a question answering (QA) system that would help aircraft pilots access information in this documentation by naturally interacting with the system and asking questions in natural language. After describing each module of the dialog system, we present a multi-task based approach for the QA module which enables performance improvement on a Flight Crew Operating Manual (FCOM) dataset. A method to combine scores from the retriever and the QA modules is also presented.