 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Dreaming: A Global Workspace Approach to World Model-Based Reinforcement Learning
Feb 28, 2025Humans leverage rich internal models of the world to reason about the future, imagine counterfactuals, and adapt flexibly to new situations. In Reinforcement Learning (RL), world models aim to capture how the environment evolves in response to the agent's actions, facilitating planning and generalization. However, typical world models directly operate on the environment variables (e.g. pixels, physical attributes), which can make their training slow and cumbersome; instead, it may be advantageous to rely on high-level latent dimensions that capture relevant multimodal variables. Global Workspace (GW) Theory offers a cognitive framework for multimodal integration and information broadcasting in the brain, and recent studies have begun to introduce efficient deep learning implementations of GW. Here, we evaluate the capabilities of an RL system combining GW with a world model. We compare our GW-Dreamer with various versions of the standard PPO and the original Dreamer algorithms. We show that performing the dreaming process (i.e., mental simulation) inside the GW latent space allows for training with fewer environment steps. As an additional emergent property, the resulting model (but not its comparison baselines) displays strong robustness to the absence of one of its observation modalities (images or simulation attributes). We conclude that the combination of GW with World Models holds great potential for improving decision-making in RL agents.
Zero-shot cross-modal transfer of Reinforcement Learning policies through a Global Workspace
Mar 07, 2024



Humans perceive the world through multiple senses, enabling them to create a comprehensive representation of their surroundings and to generalize information across domains. For instance, when a textual description of a scene is given, humans can mentally visualize it. In fields like robotics and Reinforcement Learning (RL), agents can also access information about the environment through multiple sensors; yet redundancy and complementarity between sensors is difficult to exploit as a source of robustness (e.g. against sensor failure) or generalization (e.g. transfer across domains). Prior research demonstrated that a robust and flexible multimodal representation can be efficiently constructed based on the cognitive science notion of a 'Global Workspace': a unique representation trained to combine information across modalities, and to broadcast its signal back to each modality. Here, we explore whether such a brain-inspired multimodal representation could be advantageous for RL agents. First, we train a 'Global Workspace' to exploit information collected about the environment via two input modalities (a visual input, or an attribute vector representing the state of the agent and/or its environment). Then, we train a RL agent policy using this frozen Global Workspace. In two distinct environments and tasks, our results reveal the model's ability to perform zero-shot cross-modal transfer between input modalities, i.e. to apply to image inputs a policy previously trained on attribute vectors (and vice-versa), without additional training or fine-tuning. Variants and ablations of the full Global Workspace (including a CLIP-like multimodal representation trained via contrastive learning) did not display the same generalization abilities.
Semi-supervised Multimodal Representation Learning through a Global Workspace
Jun 27, 2023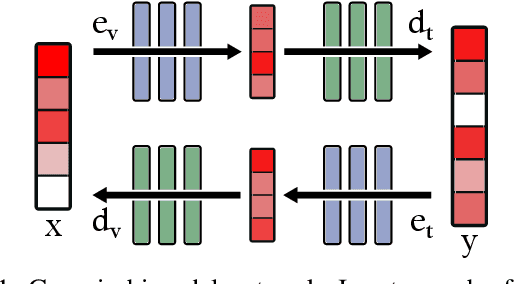

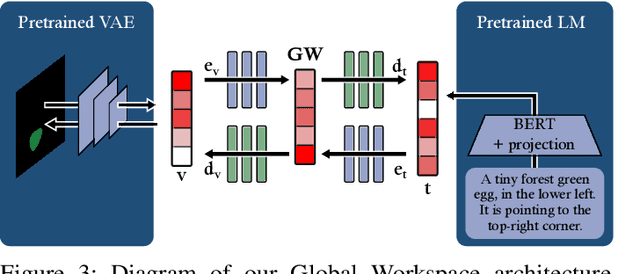

Recent deep learning models can efficiently combine inputs from different modalities (e.g., images and text) and learn to align their latent representations, or to translate signals from one domain to another (as in image captioning, or text-to-image generation). However, current approaches mainly rely on brute-force supervised training over large multimodal datasets. In contrast, humans (and other animals) can learn useful multimodal representations from only sparse experience with matched cross-modal data. Here we evaluate the capabilities of a neural network architecture inspired by the cognitive notion of a "Global Workspace": a shared representation for two (or more) input modalities. Each modality is processed by a specialized system (pretrained on unimodal data, and subsequently frozen). The corresponding latent representations are then encoded to and decoded from a single shared workspace. Importantly, this architecture is amenable to self-supervised training via cycle-consistency: encoding-decoding sequences should approximate the identity function. For various pairings of vision-language modalities and across two datasets of varying complexity, we show that such an architecture can be trained to align and translate between two modalities with very little need for matched data (from 4 to 7 times less than a fully supervised approach). The global workspace representation can be used advantageously for downstream classification tasks and for robust transfer learning. Ablation studies reveal that both the shared workspace and the self-supervised cycle-consistency training are critical to the system's performance.