 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight-R1: Curriculum SFT, DPO and RL for Long COT from Scratch and Beyond
Mar 13, 2025This paper presents our work on the Light-R1 series, with models, data, and code all released. We first focus on training long COT models from scratch, specifically starting from models initially lacking long COT capabilities. Using a curriculum training recipe consisting of two-stage SFT and semi-on-policy DPO, we train our model Light-R1-32B from Qwen2.5-32B-Instruct, resulting in superior math performance compared to DeepSeek-R1-Distill-Qwen-32B. Despite being trained exclusively on math data, Light-R1-32B shows strong generalization across other domains. In the subsequent phase of this work, we highlight the significant benefit of the 3k dataset constructed for the second SFT stage on enhancing other models. By fine-tuning DeepSeek-R1-Distilled models using this dataset, we obtain new SOTA models in 7B and 14B, while the 32B model, Light-R1-32B-DS performed comparably to QwQ-32B and DeepSeek-R1. Furthermore, we extend our work by applying reinforcement learning, specifically GRPO, on long-COT models to further improve reasoning performance. We successfully train our final Light-R1-14B-DS with RL, achieving SOTA performance among 14B parameter models in math. With AIME24 & 25 scores of 74.0 and 60.2 respectively, Light-R1-14B-DS surpasses even many 32B models and DeepSeek-R1-Distill-Llama-70B. Its RL training also exhibits well expected behavior, showing simultaneous increase in response length and reward score. The Light-R1 series of work validates training long-COT models from scratch, showcases the art in SFT data and releases SOTA models from RL.
SYSTRAN Purely Neural MT Engines for WMT2017
Sep 12, 2017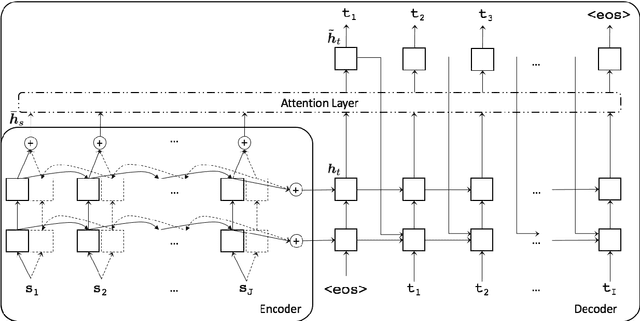
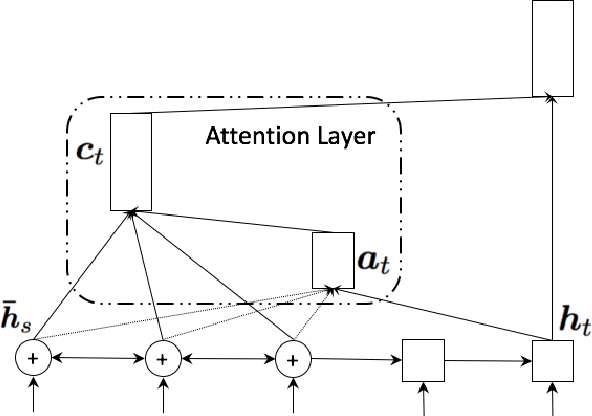

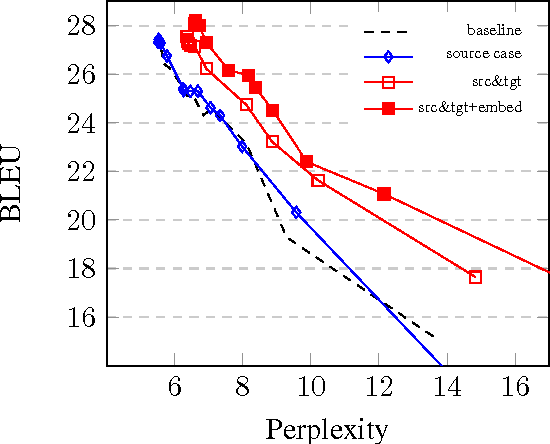
This paper describes SYSTRAN's systems submitted to the WMT 2017 shared news translation task for English-German, in both translation directions. Our systems are built using OpenNMT, an open-source neural machine translation system, implementing sequence-to-sequence models with LSTM encoder/decoders and attention. We experimented using monolingual data automatically back-translated. Our resulting models are further hyper-specialised with an adaptation technique that finely tunes models according to the evaluation test sentences.
SYSTRAN's Pure Neural Machine Translation Systems
Oct 18, 2016
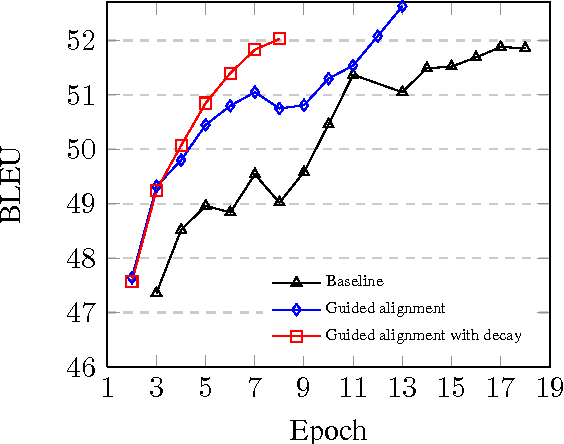
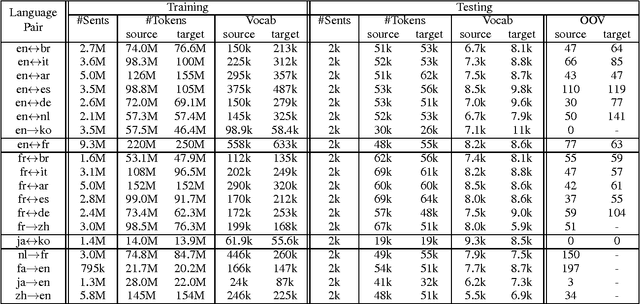
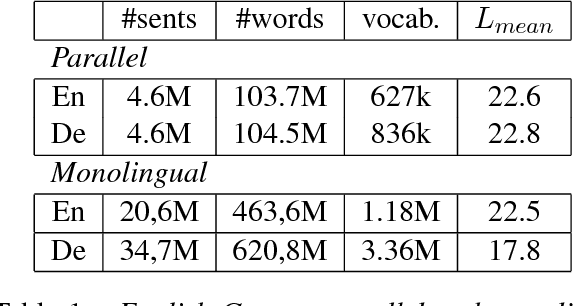
Since the first online demonstration of Neural Machine Translation (NMT) by LISA, NMT development has recently moved from laboratory to production systems as demonstrated by several entities announcing roll-out of NMT engines to replace their existing technologies. NMT systems have a large number of training configurations and the training process of such systems is usually very long, often a few weeks, so role of experimentation is critical and important to share. In this work, we present our approach to production-ready systems simultaneously with release of online demonstrators covering a large variety of languages (12 languages, for 32 language pairs). We explore different practical choices: an efficient and evolutive open-source framework; data preparation; network architecture; additional implemented features; tuning for production; etc. We discuss about evaluation methodology, present our first findings and we finally outline further work. Our ultimate goal is to share our expertise to build competitive production systems for "generic" translation. We aim at contributing to set up a collaborative framework to speed-up adoption of the technology, foster further research efforts and enable the delivery and adoption to/by industry of use-case specific engines integrated in real production workflows. Mastering of the technology would allow us to build translation engines suited for particular needs, outperforming current simplest/uniform systems.