 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKanana: Compute-efficient Bilingual Language Models
Feb 26, 2025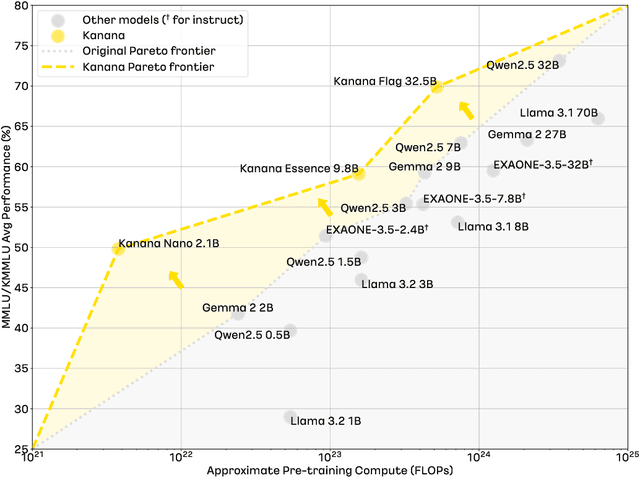



We introduce Kanana, a series of bilingual language models that demonstrate exceeding performance in Korean and competitive performance in English. The computational cost of Kanana is significantly lower than that of state-of-the-art models of similar size. The report details the techniques employed during pre-training to achieve compute-efficient yet competitive models, including high quality data filtering, staged pre-training, depth up-scaling, and pruning and distillation. Furthermore, the report outlines the methodologies utilized during the post-training of the Kanana models, encompassing supervised fine-tuning and preference optimization, aimed at enhancing their capability for seamless interaction with users. Lastly, the report elaborates on plausible approaches used for language model adaptation to specific scenarios, such as embedding, retrieval augmented generation, and function calling. The Kanana model series spans from 2.1B to 32.5B parameters with 2.1B models (base, instruct, embedding) publicly released to promote research on Korean language models.
FunctionChat-Bench: Comprehensive Evaluation of Language Models' Generative Capabilities in Korean Tool-use Dialogs
Nov 21, 2024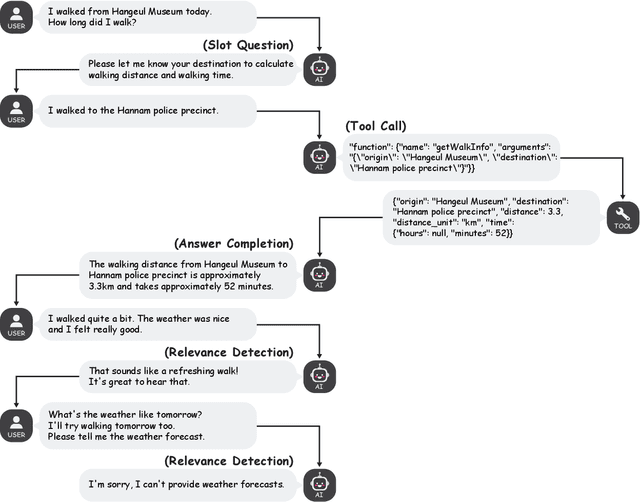
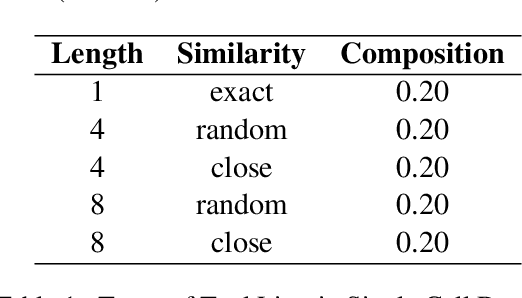
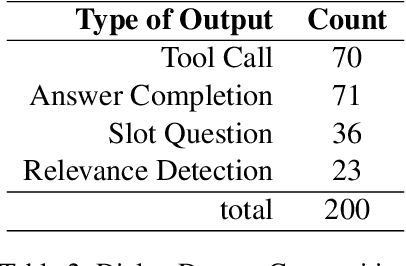

This study investigates language models' generative capabilities in tool-use dialogs. We categorize the models' outputs in tool-use dialogs into four distinct types: Tool Call, Answer Completion, Slot Question, and Relevance Detection, which serve as aspects for evaluation. We introduce FunctionChat-Bench, comprising 700 evaluation items and automated assessment programs. Using this benchmark, we evaluate several language models that support function calling. Our findings indicate that while language models may exhibit high accuracy in single-turn Tool Call scenarios, this does not necessarily translate to superior generative performance in multi-turn environments. We argue that the capabilities required for function calling extend beyond generating tool call messages; they must also effectively generate conversational messages that engage the user.