 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctionChat-Bench: Comprehensive Evaluation of Language Models' Generative Capabilities in Korean Tool-use Dialogs
Nov 21, 2024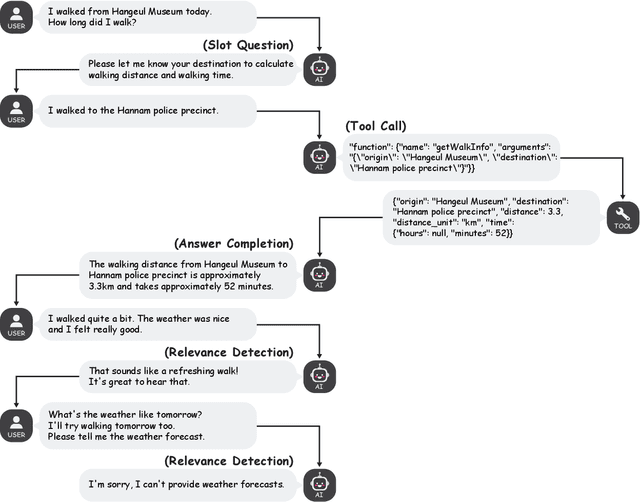
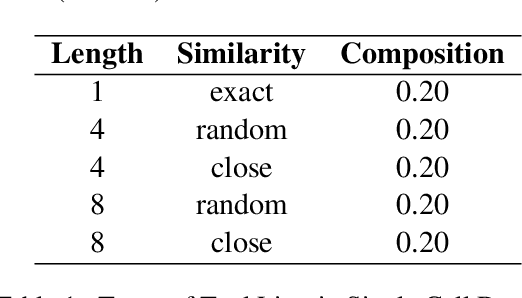
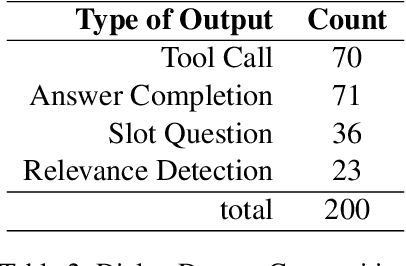

This study investigates language models' generative capabilities in tool-use dialogs. We categorize the models' outputs in tool-use dialogs into four distinct types: Tool Call, Answer Completion, Slot Question, and Relevance Detection, which serve as aspects for evaluation. We introduce FunctionChat-Bench, comprising 700 evaluation items and automated assessment programs. Using this benchmark, we evaluate several language models that support function calling. Our findings indicate that while language models may exhibit high accuracy in single-turn Tool Call scenarios, this does not necessarily translate to superior generative performance in multi-turn environments. We argue that the capabilities required for function calling extend beyond generating tool call messages; they must also effectively generate conversational messages that engage the user.
Reference and Document Aware Semantic Evaluation Methods for Korean Language Summarization
Apr 29, 2020
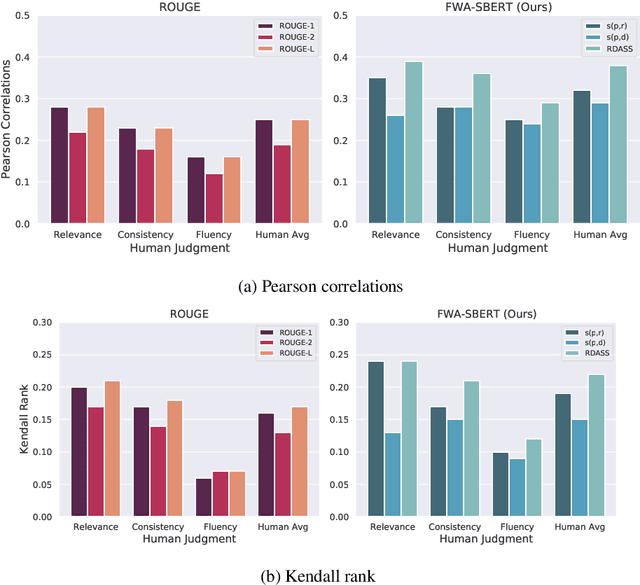

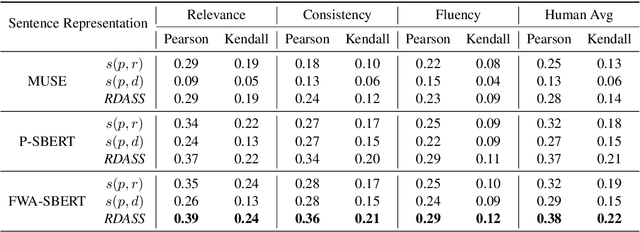
Text summarization refers to the process that generates a shorter form of text from the source document preserving salient information. Recently, many models for text summarization have been proposed. Most of those models were evaluated using recall-oriented understudy for gisting evaluation (ROUGE) scores. However, as ROUGE scores are computed based on n-gram overlap, they do not reflect semantic meaning correspondences between generated and reference summaries. Because Korean is an agglutinative language that combines various morphemes into a word that express several meanings, ROUGE is not suitable for Korean summarization. In this paper, we propose evaluation metrics that reflect semantic meanings of a reference summary and the original document, Reference and Document Aware Semantic Score (RDASS). We then propose a method for improving the correlation of the metrics with human judgment. Evaluation results show that the correlation with human judgment is significantly higher for our evaluation metrics than for ROUGE scores.