 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
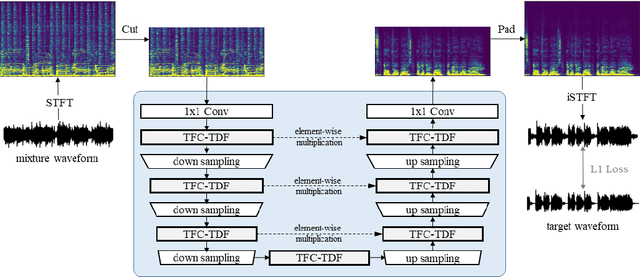
Add to EdgeSound Demixing Challenge 2023 Music Demixing Track Technical Report: TFC-TDF-UNet v3
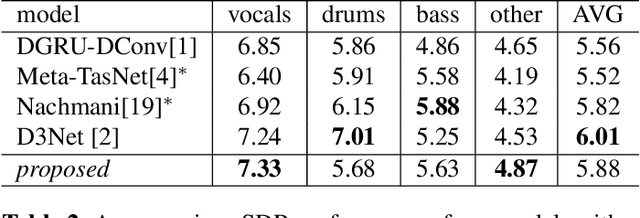
Jun 26, 2023In this report, we present our award-winning solutions for the Music Demixing Track of Sound Demixing Challenge 2023. First, we propose TFC-TDF-UNet v3, a time-efficient music source separation model that achieves state-of-the-art results on the MUSDB benchmark. We then give full details regarding our solutions for each Leaderboard, including a loss masking approach for noise-robust training. Code for reproducing model training and final submissions is available at github.com/kuielab/sdx23.
Learning source-aware representations of music in a discrete latent space
Nov 26, 2021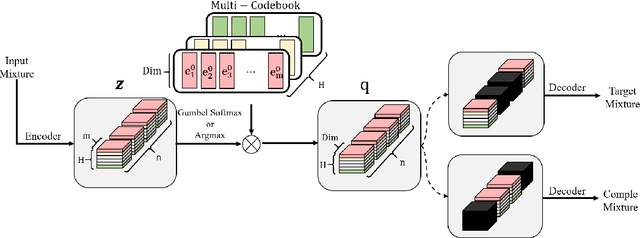
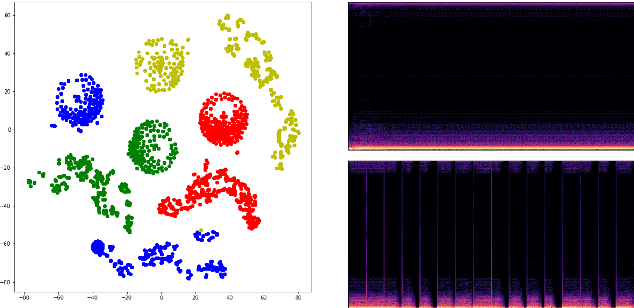
In recent years, neural network based methods have been proposed as a method that cangenerate representations from music, but they are not human readable and hardly analyzable oreditable by a human. To address this issue, we propose a novel method to learn source-awarelatent representations of music through Vector-Quantized Variational Auto-Encoder(VQ-VAE).We train our VQ-VAE to encode an input mixture into a tensor of integers in a discrete latentspace, and design them to have a decomposed structure which allows humans to manipulatethe latent vector in a source-aware manner. This paper also shows that we can generate basslines by estimating latent vectors in a discrete space.
LightSAFT: Lightweight Latent Source Aware Frequency Transform for Source Separation
Nov 24, 2021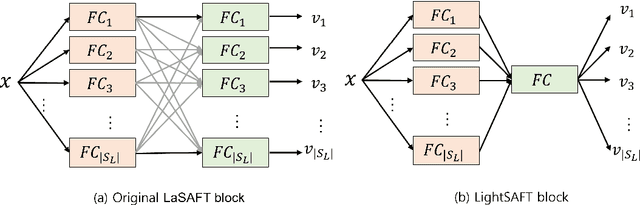

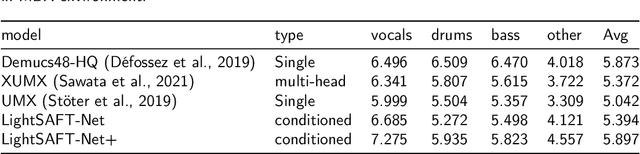
Conditioned source separations have attracted significant attention because of their flexibility, applicability and extensionality. Their performance was usually inferior to the existing approaches, such as the single source separation model. However, a recently proposed method called LaSAFT-Net has shown that conditioned models can show comparable performance against existing single-source separation models. This paper presents LightSAFT-Net, a lightweight version of LaSAFT-Net. As a baseline, it provided a sufficient SDR performance for comparison during the Music Demixing Challenge at ISMIR 2021. This paper also enhances the existing LightSAFT-Net by replacing the LightSAFT blocks in the encoder with TFC-TDF blocks. Our enhanced LightSAFT-Net outperforms the previous one with fewer parameters.
KUIELab-MDX-Net: A Two-Stream Neural Network for Music Demixing
Nov 24, 2021
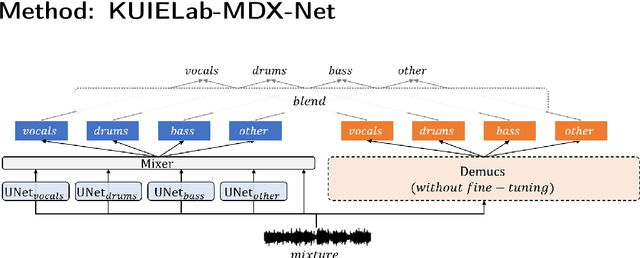
Recently, many methods based on deep learning have been proposed for music source separation. Some state-of-the-art methods have shown that stacking many layers with many skip connections improve the SDR performance. Although such a deep and complex architecture shows outstanding performance, it usually requires numerous computing resources and time for training and evaluation. This paper proposes a two-stream neural network for music demixing, called KUIELab-MDX-Net, which shows a good balance of performance and required resources. The proposed model has a time-frequency branch and a time-domain branch, where each branch separates stems, respectively. It blends results from two streams to generate the final estimation. KUIELab-MDX-Net took second place on leaderboard A and third place on leaderboard B in the Music Demixing Challenge at ISMIR 2021. This paper also summarizes experimental results on another benchmark, MUSDB18. Our source code is available online.
AMSS-Net: Audio Manipulation on User-Specified Sources with Textual Queries
Apr 28, 2021


This paper proposes a neural network that performs audio transformations to user-specified sources (e.g., vocals) of a given audio track according to a given description while preserving other sources not mentioned in the description. Audio Manipulation on a Specific Source (AMSS) is challenging because a sound object (i.e., a waveform sample or frequency bin) is `transparent'; it usually carries information from multiple sources, in contrast to a pixel in an image. To address this challenging problem, we propose AMSS-Net, which extracts latent sources and selectively manipulates them while preserving irrelevant sources. We also propose an evaluation benchmark for several AMSS tasks, and we show that AMSS-Net outperforms baselines on several AMSS tasks via objective metrics and empirical verification.
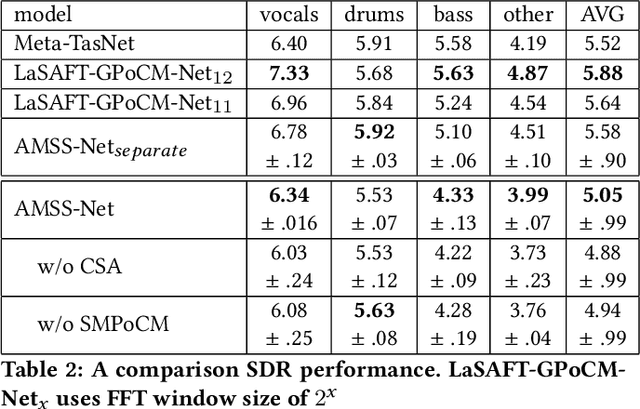
LaSAFT: Latent Source Attentive Frequency Transformation for Conditioned Source Separation
Oct 22, 2020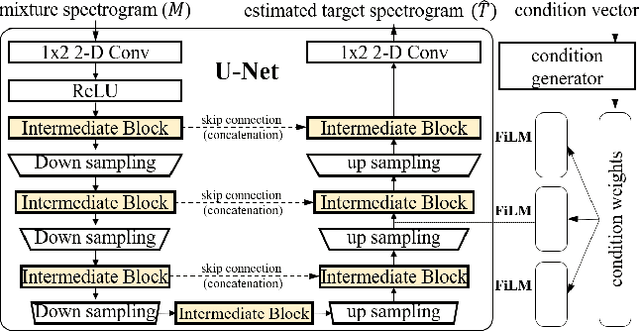
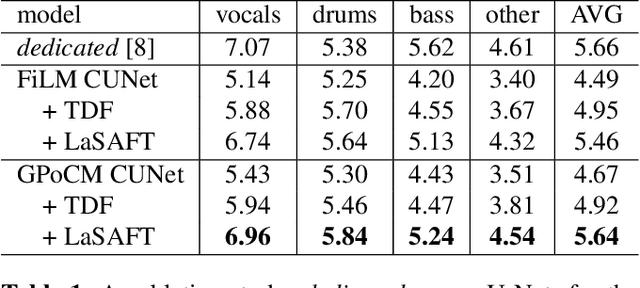
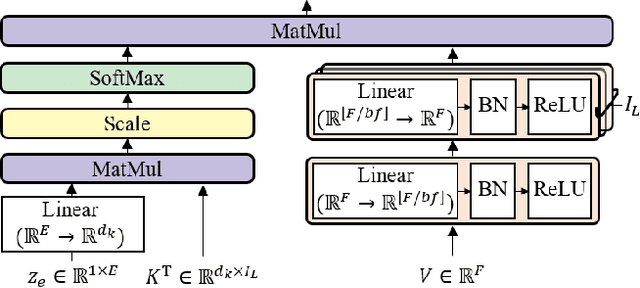
Recent deep-learning approaches have shown that Frequency Transformation (FT) blocks can significantly improve spectrogram-based single-source separation models by capturing frequency patterns. The goal of this paper is to extend the FT block to fit the multi-source task. We propose the Latent Source Attentive Frequency Transformation (LaSAFT) block to capture source-dependent frequency patterns. We also propose the Gated Point-wise Convolutional Modulation (GPoCM), an extension of Feature-wise Linear Modulation (FiLM), to modulate internal features. By employing these two novel methods, we extend the Conditioned-U-Net (CUNet) for multi-source separation, and the experimental results indicate that our LaSAFT and GPoCM can improve the CUNet's performance, achieving state-of-the-art SDR performance on several MUSDB18 source separation tasks.
Investigating Deep Neural Transformations for Spectrogram-based Musical Source Separation
Dec 09, 2019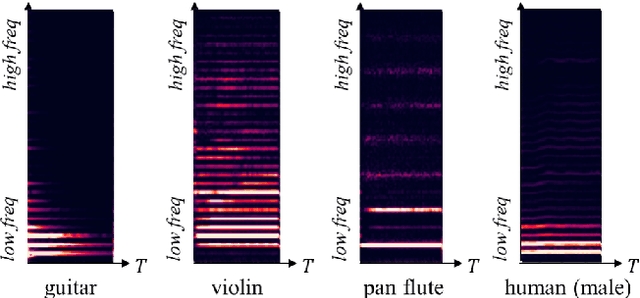
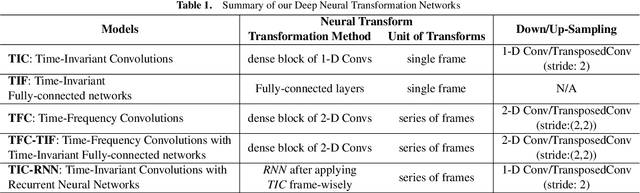
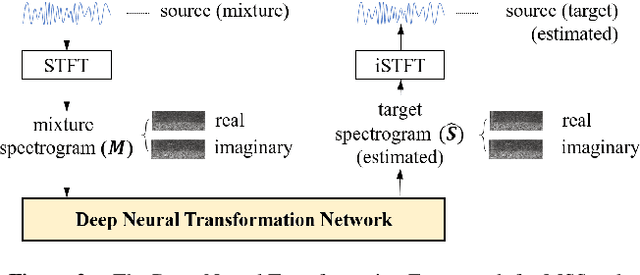

Musical Source Separation (MSS) is a signal processing task that tries to separate the mixed musical signal into each acoustic sound source, such as singing voice or drums. Recently many machine learning-based methods have been proposed for the MSS task, but there were no existing works that evaluate and directly compare various types of networks. In this paper, we aim to design a variety of neural transformation methods, including time-invariant methods, time-frequency methods, and mixtures of two different transformations. Our experiments provide abundant material for future works by comparing several transformation methods. We train our models on raw complex-valued STFT outputs and achieve state-of-the-art SDR performance on the MUSDB singing voice separation task by a large margin of 1.0 dB.