 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning source-aware representations of music in a discrete latent space
Nov 26, 2021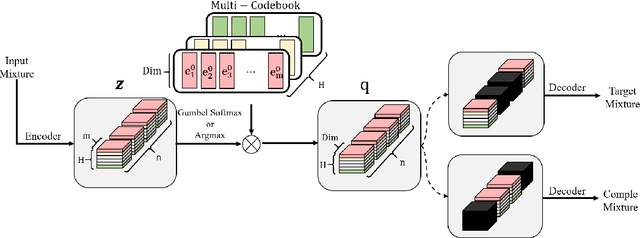
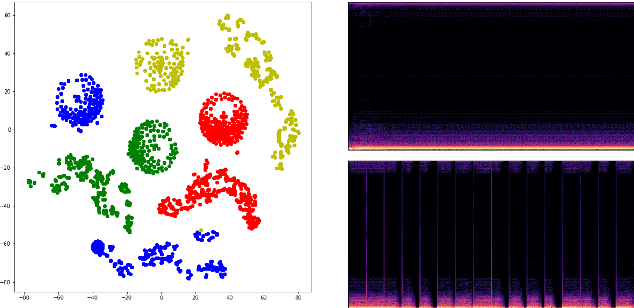
In recent years, neural network based methods have been proposed as a method that cangenerate representations from music, but they are not human readable and hardly analyzable oreditable by a human. To address this issue, we propose a novel method to learn source-awarelatent representations of music through Vector-Quantized Variational Auto-Encoder(VQ-VAE).We train our VQ-VAE to encode an input mixture into a tensor of integers in a discrete latentspace, and design them to have a decomposed structure which allows humans to manipulatethe latent vector in a source-aware manner. This paper also shows that we can generate basslines by estimating latent vectors in a discrete space.
LightSAFT: Lightweight Latent Source Aware Frequency Transform for Source Separation
Nov 24, 2021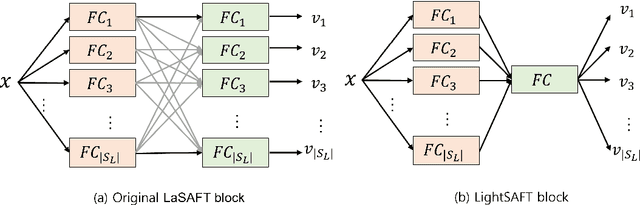

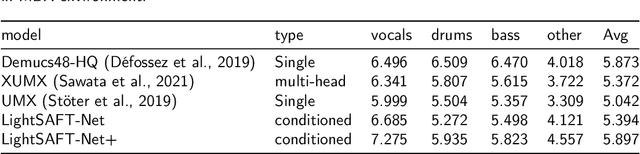
Conditioned source separations have attracted significant attention because of their flexibility, applicability and extensionality. Their performance was usually inferior to the existing approaches, such as the single source separation model. However, a recently proposed method called LaSAFT-Net has shown that conditioned models can show comparable performance against existing single-source separation models. This paper presents LightSAFT-Net, a lightweight version of LaSAFT-Net. As a baseline, it provided a sufficient SDR performance for comparison during the Music Demixing Challenge at ISMIR 2021. This paper also enhances the existing LightSAFT-Net by replacing the LightSAFT blocks in the encoder with TFC-TDF blocks. Our enhanced LightSAFT-Net outperforms the previous one with fewer parameters.