Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning source-aware representations of music in a discrete latent space
Paper and Code
Nov 26, 2021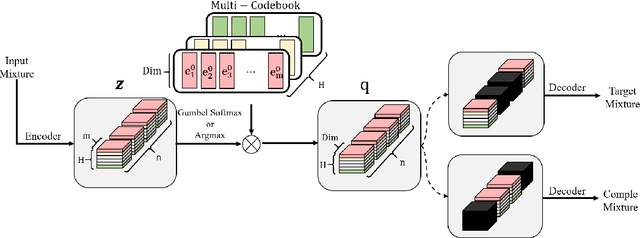
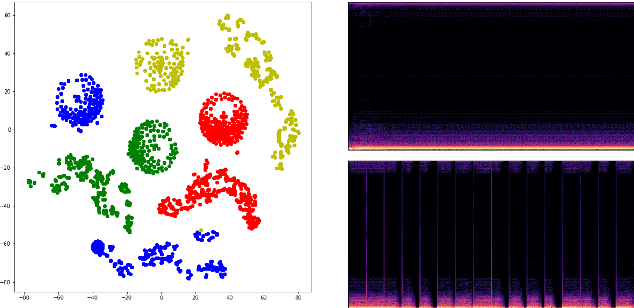
In recent years, neural network based methods have been proposed as a method that cangenerate representations from music, but they are not human readable and hardly analyzable oreditable by a human. To address this issue, we propose a novel method to learn source-awarelatent representations of music through Vector-Quantized Variational Auto-Encoder(VQ-VAE).We train our VQ-VAE to encode an input mixture into a tensor of integers in a discrete latentspace, and design them to have a decomposed structure which allows humans to manipulatethe latent vector in a source-aware manner. This paper also shows that we can generate basslines by estimating latent vectors in a discrete space.
* MDX Workshop @ ISMIR 2021, 7 pages, 2 figure
View paper on