 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMSS-Net: Audio Manipulation on User-Specified Sources with Textual Queries
Paper and Code



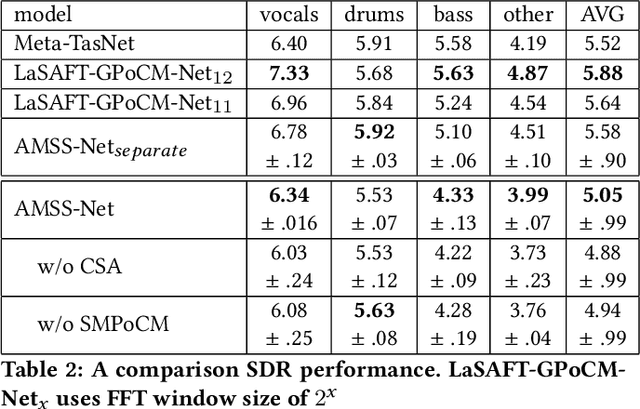
This paper proposes a neural network that performs audio transformations to user-specified sources (e.g., vocals) of a given audio track according to a given description while preserving other sources not mentioned in the description. Audio Manipulation on a Specific Source (AMSS) is challenging because a sound object (i.e., a waveform sample or frequency bin) is `transparent'; it usually carries information from multiple sources, in contrast to a pixel in an image. To address this challenging problem, we propose AMSS-Net, which extracts latent sources and selectively manipulates them while preserving irrelevant sources. We also propose an evaluation benchmark for several AMSS tasks, and we show that AMSS-Net outperforms baselines on several AMSS tasks via objective metrics and empirical verification.