 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Distortion Effects in Music Using Deep Neural Networks
Feb 03, 2022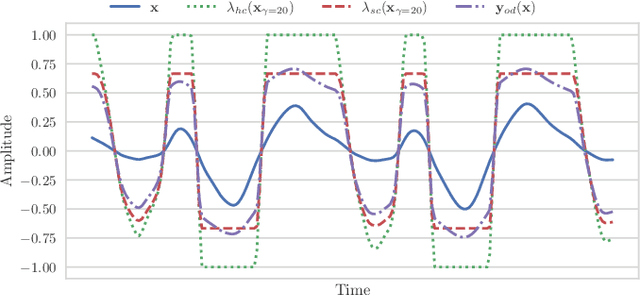
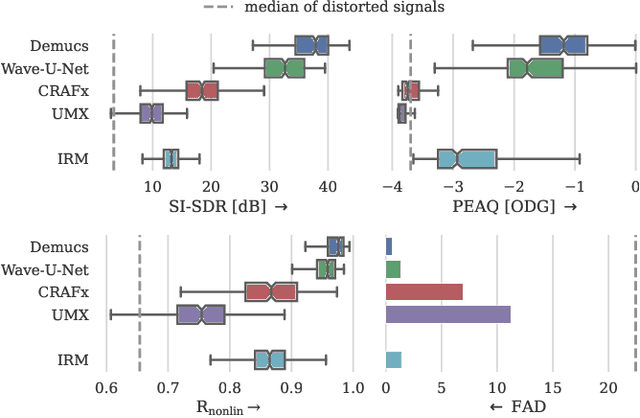
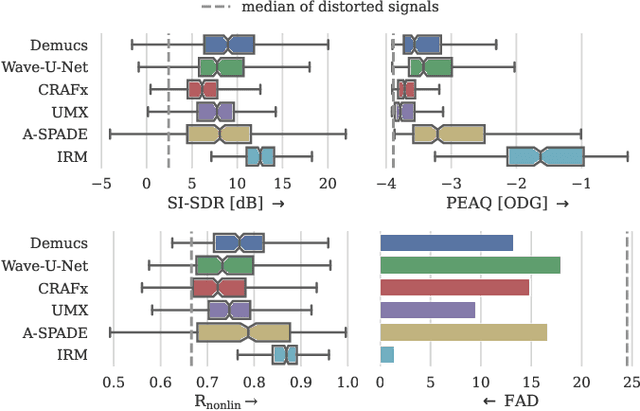
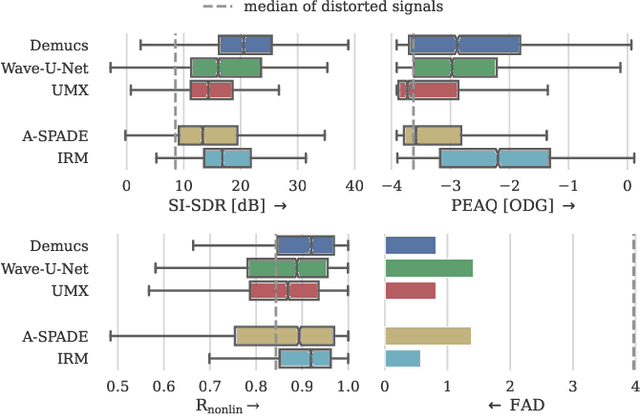
Audio effects are an essential element in the context of music production, and therefore, modeling analog audio effects has been extensively researched for decades using system-identification methods, circuit simulation, and recently, deep learning. However, only few works tackled the reconstruction of signals that were processed using an audio effect unit. Given the recent advances in music source separation and automatic mixing, the removal of audio effects could facilitate an automatic remixing system. This paper focuses on removing distortion and clipping applied to guitar tracks for music production while presenting a comparative investigation of different deep neural network (DNN) architectures on this task. We achieve exceptionally good results in distortion removal using DNNs for effects that superimpose the clean signal to the distorted signal, while the task is more challenging if the clean signal is not superimposed. Nevertheless, in the latter case, the neural models under evaluation surpass one state-of-the-art declipping system in terms of source-to-distortion ratio, leading to better quality and faster inference.
Automatic DJ Transitions with Differentiable Audio Effects and Generative Adversarial Networks
Oct 13, 2021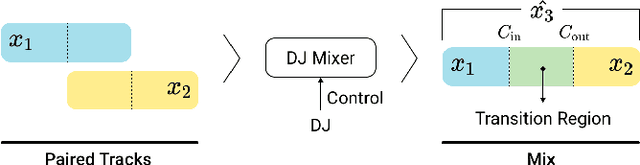
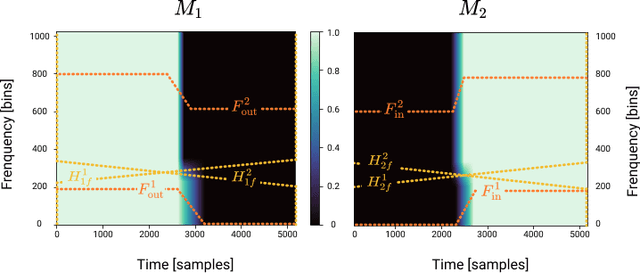
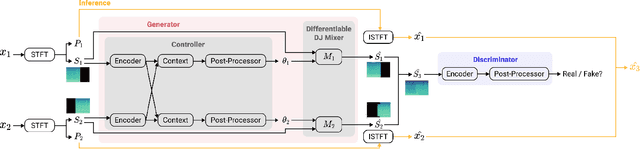

A central task of a Disc Jockey (DJ) is to create a mixset of mu-sic with seamless transitions between adjacent tracks. In this paper, we explore a data-driven approach that uses a generative adversarial network to create the song transition by learning from real-world DJ mixes. In particular, the generator of the model uses two differentiable digital signal processing components, an equalizer (EQ) and a fader, to mix two tracks selected by a data generation pipeline. The generator has to set the parameters of the EQs and fader in such away that the resulting mix resembles real mixes created by humanDJ, as judged by the discriminator counterpart. Result of a listening test shows that the model can achieve competitive results compared with a number of baselines.
Differentiable Signal Processing With Black-Box Audio Effects
May 11, 2021



We present a data-driven approach to automate audio signal processing by incorporating stateful third-party, audio effects as layers within a deep neural network. We then train a deep encoder to analyze input audio and control effect parameters to perform the desired signal manipulation, requiring only input-target paired audio data as supervision. To train our network with non-differentiable black-box effects layers, we use a fast, parallel stochastic gradient approximation scheme within a standard auto differentiation graph, yielding efficient end-to-end backpropagation. We demonstrate the power of our approach with three separate automatic audio production applications: tube amplifier emulation, automatic removal of breaths and pops from voice recordings, and automatic music mastering. We validate our results with a subjective listening test, showing our approach not only can enable new automatic audio effects tasks, but can yield results comparable to a specialized, state-of-the-art commercial solution for music mastering.
AMSS-Net: Audio Manipulation on User-Specified Sources with Textual Queries
Apr 28, 2021


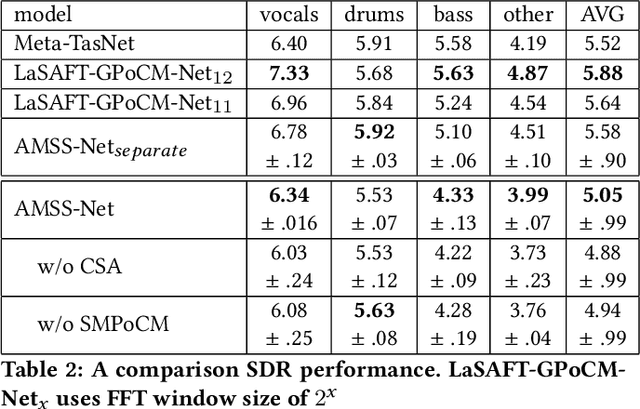
This paper proposes a neural network that performs audio transformations to user-specified sources (e.g., vocals) of a given audio track according to a given description while preserving other sources not mentioned in the description. Audio Manipulation on a Specific Source (AMSS) is challenging because a sound object (i.e., a waveform sample or frequency bin) is `transparent'; it usually carries information from multiple sources, in contrast to a pixel in an image. To address this challenging problem, we propose AMSS-Net, which extracts latent sources and selectively manipulates them while preserving irrelevant sources. We also propose an evaluation benchmark for several AMSS tasks, and we show that AMSS-Net outperforms baselines on several AMSS tasks via objective metrics and empirical verification.
Modeling plate and spring reverberation using a DSP-informed deep neural network
Oct 22, 2019



Plate and spring reverberators are electromechanical systems first used and researched as means to substitute real room reverberation. Nowadays they are often used in music production for aesthetic reasons due to their particular sonic characteristics. The modeling of these audio processors and their perceptual qualities is difficult since they use mechanical elements together with analog electronics resulting in an extremely complex response. Based on digital reverberators that use sparse FIR filters, we propose a signal processing-informed deep learning architecture for the modeling of artificial reverberators. We explore the capabilities of deep neural networks to learn such highly nonlinear electromechanical responses and we perform modeling of plate and spring reverberators. In order to measure the performance of the model, we conduct a perceptual evaluation experiment and we also analyze how the given task is accomplished and what the model is actually learning.