 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2M-Zero: Zero-Pair Time-Aligned Video-to-Music Generation
Mar 11, 2026Generating music that temporally aligns with video events is challenging for existing text-to-music models, which lack fine-grained temporal control. We introduce V2M-Zero, a zero-pair video-to-music generation approach that outputs time-aligned music for video. Our method is motivated by a key observation: temporal synchronization requires matching when and how much change occurs, not what changes. While musical and visual events differ semantically, they exhibit shared temporal structure that can be captured independently within each modality. We capture this structure through event curves computed from intra-modal similarity using pretrained music and video encoders. By measuring temporal change within each modality independently, these curves provide comparable representations across modalities. This enables a simple training strategy: fine-tune a text-to-music model on music-event curves, then substitute video-event curves at inference without cross-modal training or paired data. Across OES-Pub, MovieGenBench-Music, and AIST++, V2M-Zero achieves substantial gains over paired-data baselines: 5-21% higher audio quality, 13-15% better semantic alignment, 21-52% improved temporal synchronization, and 28% higher beat alignment on dance videos. We find similar results via a large crowd-source subjective listening test. Overall, our results validate that temporal alignment through within-modality features, rather than paired cross-modal supervision, is effective for video-to-music generation. Results are available at https://genjib.github.io/v2m_zero/
A Generative-First Neural Audio Autoencoder
Feb 17, 2026Neural autoencoders underpin generative models. Practical, large-scale use of neural autoencoders for generative modeling necessitates fast encoding, low latent rates, and a single model across representations. Existing approaches are reconstruction-first: they incur high latent rates, slow encoding, and separate architectures for discrete vs. continuous latents and for different audio channel formats, hindering workflows from preprocessing to inference conditioning. We introduce a generative-first architecture for audio autoencoding that increases temporal downsampling from 2048x to 3360x and supports continuous and discrete representations and common audio channel formats in one model. By balancing compression, quality, and speed, it delivers 10x faster encoding, 1.6x lower rates, and eliminates channel-format-specific variants while maintaining competitive reconstruction quality. This enables applications previously constrained by processing costs: a 60-second mono signal compresses to 788 tokens, making generative modeling more tractable.
Stemphonic: All-at-once Flexible Multi-stem Music Generation
Feb 10, 2026Music stem generation, the task of producing musically-synchronized and isolated instrument audio clips, offers the potential of greater user control and better alignment with musician workflows compared to conventional text-to-music models. Existing stem generation approaches, however, either rely on fixed architectures that output a predefined set of stems in parallel, or generate only one stem at a time, resulting in slow inference despite flexibility in stem combination. We propose Stemphonic, a diffusion-/flow-based framework that overcomes this trade-off and generates a variable set of synchronized stems in one inference pass. During training, we treat each stem as a batch element, group synchronized stems in a batch, and apply a shared noise latent to each group. At inference-time, we use a shared initial noise latent and stem-specific text inputs to generate synchronized multi-stem outputs in one pass. We further expand our approach to enable one-pass conditional multi-stem generation and stem-wise activity controls to empower users to iteratively generate and orchestrate the temporal layering of a mix. We benchmark our results on multiple open-source stem evaluation sets and show that Stemphonic produces higher-quality outputs while accelerating the full mix generation process by 25 to 50%. Demos at: https://stemphonic-demo.vercel.app.
Rethinking Music Captioning with Music Metadata LLMs
Feb 03, 2026Music captioning, or the task of generating a natural language description of music, is useful for both music understanding and controllable music generation. Training captioning models, however, typically requires high-quality music caption data which is scarce compared to metadata (e.g., genre, mood, etc.). As a result, it is common to use large language models (LLMs) to synthesize captions from metadata to generate training data for captioning models, though this process imposes a fixed stylization and entangles factual information with natural language style. As a more direct approach, we propose metadata-based captioning. We train a metadata prediction model to infer detailed music metadata from audio and then convert it into expressive captions via pre-trained LLMs at inference time. Compared to a strong end-to-end baseline trained on LLM-generated captions derived from metadata, our method: (1) achieves comparable performance in less training time over end-to-end captioners, (2) offers flexibility to easily change stylization post-training, enabling output captions to be tailored to specific stylistic and quality requirements, and (3) can be prompted with audio and partial metadata to enable powerful metadata imputation or in-filling--a common task for organizing music data.
DRAGON: Distributional Rewards Optimize Diffusion Generative Models
Apr 21, 2025We present Distributional RewArds for Generative OptimizatioN (DRAGON), a versatile framework for fine-tuning media generation models towards a desired outcome. Compared with traditional reinforcement learning with human feedback (RLHF) or pairwise preference approaches such as direct preference optimization (DPO), DRAGON is more flexible. It can optimize reward functions that evaluate either individual examples or distributions of them, making it compatible with a broad spectrum of instance-wise, instance-to-distribution, and distribution-to-distribution rewards. Leveraging this versatility, we construct novel reward functions by selecting an encoder and a set of reference examples to create an exemplar distribution. When cross-modality encoders such as CLAP are used, the reference examples may be of a different modality (e.g., text versus audio). Then, DRAGON gathers online and on-policy generations, scores them to construct a positive demonstration set and a negative set, and leverages the contrast between the two sets to maximize the reward. For evaluation, we fine-tune an audio-domain text-to-music diffusion model with 20 different reward functions, including a custom music aesthetics model, CLAP score, Vendi diversity, and Frechet audio distance (FAD). We further compare instance-wise (per-song) and full-dataset FAD settings while ablating multiple FAD encoders and reference sets. Over all 20 target rewards, DRAGON achieves an 81.45% average win rate. Moreover, reward functions based on exemplar sets indeed enhance generations and are comparable to model-based rewards. With an appropriate exemplar set, DRAGON achieves a 60.95% human-voted music quality win rate without training on human preference annotations. As such, DRAGON exhibits a new approach to designing and optimizing reward functions for improving human-perceived quality. Sound examples at https://ml-dragon.github.io/web.
Presto! Distilling Steps and Layers for Accelerating Music Generation
Oct 07, 2024



Despite advances in diffusion-based text-to-music (TTM) methods, efficient, high-quality generation remains a challenge. We introduce Presto!, an approach to inference acceleration for score-based diffusion transformers via reducing both sampling steps and cost per step. To reduce steps, we develop a new score-based distribution matching distillation (DMD) method for the EDM-family of diffusion models, the first GAN-based distillation method for TTM. To reduce the cost per step, we develop a simple, but powerful improvement to a recent layer distillation method that improves learning via better preserving hidden state variance. Finally, we combine our step and layer distillation methods together for a dual-faceted approach. We evaluate our step and layer distillation methods independently and show each yield best-in-class performance. Our combined distillation method can generate high-quality outputs with improved diversity, accelerating our base model by 10-18x (230/435ms latency for 32 second mono/stereo 44.1kHz, 15x faster than comparable SOTA) -- the fastest high-quality TTM to our knowledge. Sound examples can be found at https://presto-music.github.io/web/.
MusicHiFi: Fast High-Fidelity Stereo Vocoding
Mar 20, 2024



Diffusion-based audio and music generation models commonly generate music by constructing an image representation of audio (e.g., a mel-spectrogram) and then converting it to audio using a phase reconstruction model or vocoder. Typical vocoders, however, produce monophonic audio at lower resolutions (e.g., 16-24 kHz), which limits their effectiveness. We propose MusicHiFi -- an efficient high-fidelity stereophonic vocoder. Our method employs a cascade of three generative adversarial networks (GANs) that convert low-resolution mel-spectrograms to audio, upsamples to high-resolution audio via bandwidth expansion, and upmixes to stereophonic audio. Compared to previous work, we propose 1) a unified GAN-based generator and discriminator architecture and training procedure for each stage of our cascade, 2) a new fast, near downsampling-compatible bandwidth extension module, and 3) a new fast downmix-compatible mono-to-stereo upmixer that ensures the preservation of monophonic content in the output. We evaluate our approach using both objective and subjective listening tests and find our approach yields comparable or better audio quality, better spatialization control, and significantly faster inference speed compared to past work. Sound examples are at https://MusicHiFi.github.io/web/.
Scaling Up Adaptive Filter Optimizers
Mar 01, 2024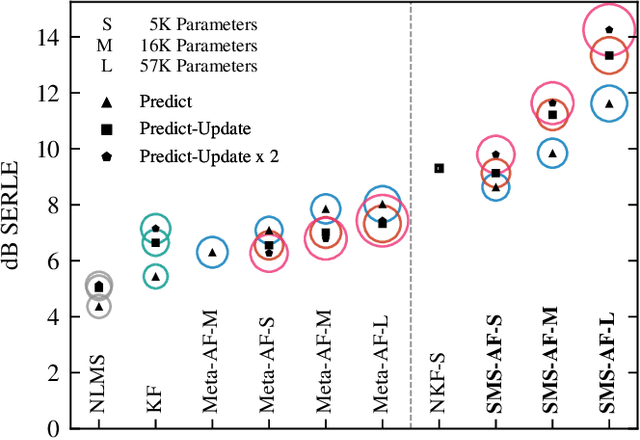
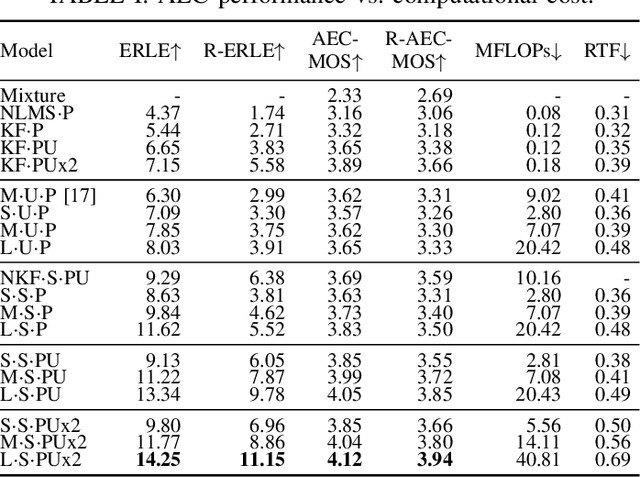
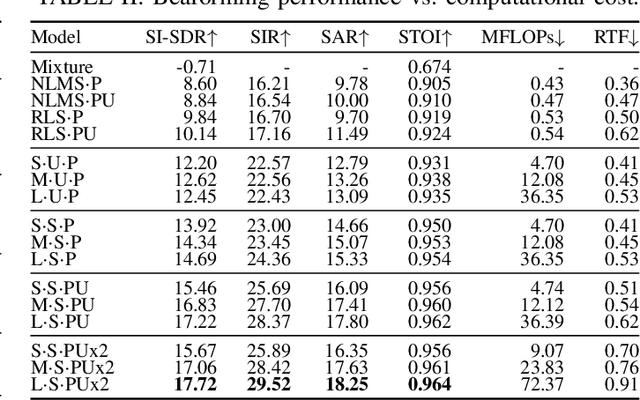
We introduce a new online adaptive filtering method called supervised multi-step adaptive filters (SMS-AF). Our method uses neural networks to control or optimize linear multi-delay or multi-channel frequency-domain filters and can flexibly scale-up performance at the cost of increased compute -- a property rarely addressed in the AF literature, but critical for many applications. To do so, we extend recent work with a set of improvements including feature pruning, a supervised loss, and multiple optimization steps per time-frame. These improvements work in a cohesive manner to unlock scaling. Furthermore, we show how our method relates to Kalman filtering and meta-adaptive filtering, making it seamlessly applicable to a diverse set of AF tasks. We evaluate our method on acoustic echo cancellation (AEC) and multi-channel speech enhancement tasks and compare against several baselines on standard synthetic and real-world datasets. Results show our method performance scales with inference cost and model capacity, yields multi-dB performance gains for both tasks, and is real-time capable on a single CPU core.
DITTO: Diffusion Inference-Time T-Optimization for Music Generation
Jan 22, 2024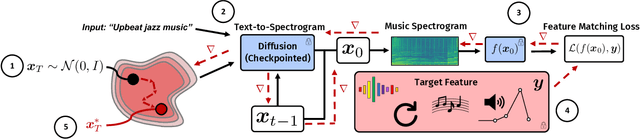
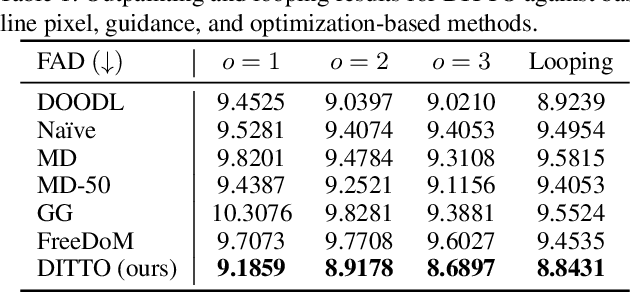
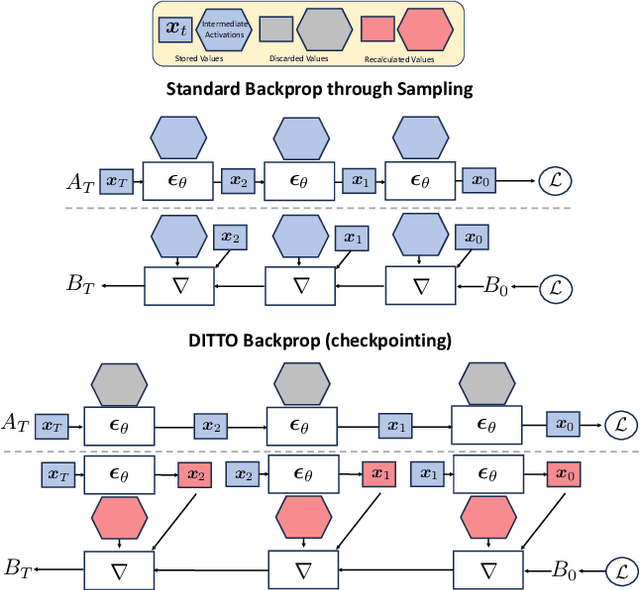
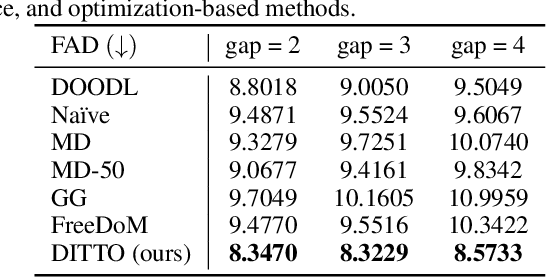
We propose Diffusion Inference-Time T-Optimization (DITTO), a general-purpose frame-work for controlling pre-trained text-to-music diffusion models at inference-time via optimizing initial noise latents. Our method can be used to optimize through any differentiable feature matching loss to achieve a target (stylized) output and leverages gradient checkpointing for memory efficiency. We demonstrate a surprisingly wide-range of applications for music generation including inpainting, outpainting, and looping as well as intensity, melody, and musical structure control - all without ever fine-tuning the underlying model. When we compare our approach against related training, guidance, and optimization-based methods, we find DITTO achieves state-of-the-art performance on nearly all tasks, including outperforming comparable approaches on controllability, audio quality, and computational efficiency, thus opening the door for high-quality, flexible, training-free control of diffusion models. Sound examples can be found at https://DITTO-Music.github.io/web/.
Music ControlNet: Multiple Time-varying Controls for Music Generation
Nov 13, 2023



Text-to-music generation models are now capable of generating high-quality music audio in broad styles. However, text control is primarily suitable for the manipulation of global musical attributes like genre, mood, and tempo, and is less suitable for precise control over time-varying attributes such as the positions of beats in time or the changing dynamics of the music. We propose Music ControlNet, a diffusion-based music generation model that offers multiple precise, time-varying controls over generated audio. To imbue text-to-music models with time-varying control, we propose an approach analogous to pixel-wise control of the image-domain ControlNet method. Specifically, we extract controls from training audio yielding paired data, and fine-tune a diffusion-based conditional generative model over audio spectrograms given melody, dynamics, and rhythm controls. While the image-domain Uni-ControlNet method already allows generation with any subset of controls, we devise a new strategy to allow creators to input controls that are only partially specified in time. We evaluate both on controls extracted from audio and controls we expect creators to provide, demonstrating that we can generate realistic music that corresponds to control inputs in both settings. While few comparable music generation models exist, we benchmark against MusicGen, a recent model that accepts text and melody input, and show that our model generates music that is 49% more faithful to input melodies despite having 35x fewer parameters, training on 11x less data, and enabling two additional forms of time-varying control. Sound examples can be found at https://MusicControlNet.github.io/web/.