 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStemphonic: All-at-once Flexible Multi-stem Music Generation
Feb 10, 2026Music stem generation, the task of producing musically-synchronized and isolated instrument audio clips, offers the potential of greater user control and better alignment with musician workflows compared to conventional text-to-music models. Existing stem generation approaches, however, either rely on fixed architectures that output a predefined set of stems in parallel, or generate only one stem at a time, resulting in slow inference despite flexibility in stem combination. We propose Stemphonic, a diffusion-/flow-based framework that overcomes this trade-off and generates a variable set of synchronized stems in one inference pass. During training, we treat each stem as a batch element, group synchronized stems in a batch, and apply a shared noise latent to each group. At inference-time, we use a shared initial noise latent and stem-specific text inputs to generate synchronized multi-stem outputs in one pass. We further expand our approach to enable one-pass conditional multi-stem generation and stem-wise activity controls to empower users to iteratively generate and orchestrate the temporal layering of a mix. We benchmark our results on multiple open-source stem evaluation sets and show that Stemphonic produces higher-quality outputs while accelerating the full mix generation process by 25 to 50%. Demos at: https://stemphonic-demo.vercel.app.
MusicHiFi: Fast High-Fidelity Stereo Vocoding
Mar 20, 2024



Diffusion-based audio and music generation models commonly generate music by constructing an image representation of audio (e.g., a mel-spectrogram) and then converting it to audio using a phase reconstruction model or vocoder. Typical vocoders, however, produce monophonic audio at lower resolutions (e.g., 16-24 kHz), which limits their effectiveness. We propose MusicHiFi -- an efficient high-fidelity stereophonic vocoder. Our method employs a cascade of three generative adversarial networks (GANs) that convert low-resolution mel-spectrograms to audio, upsamples to high-resolution audio via bandwidth expansion, and upmixes to stereophonic audio. Compared to previous work, we propose 1) a unified GAN-based generator and discriminator architecture and training procedure for each stage of our cascade, 2) a new fast, near downsampling-compatible bandwidth extension module, and 3) a new fast downmix-compatible mono-to-stereo upmixer that ensures the preservation of monophonic content in the output. We evaluate our approach using both objective and subjective listening tests and find our approach yields comparable or better audio quality, better spatialization control, and significantly faster inference speed compared to past work. Sound examples are at https://MusicHiFi.github.io/web/.
Transcription free filler word detection with Neural semi-CRFs
Mar 11, 2023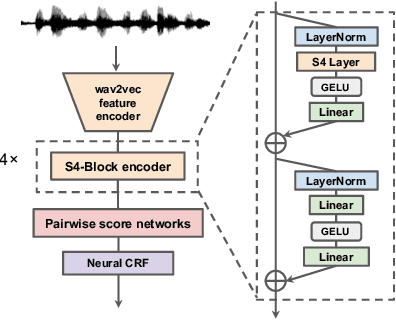
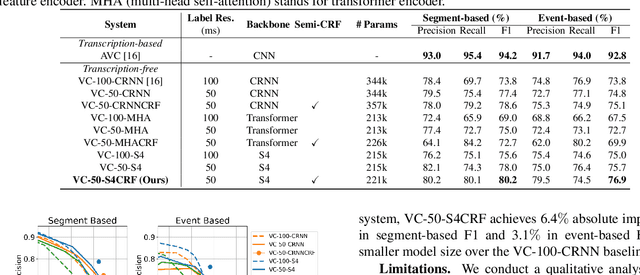
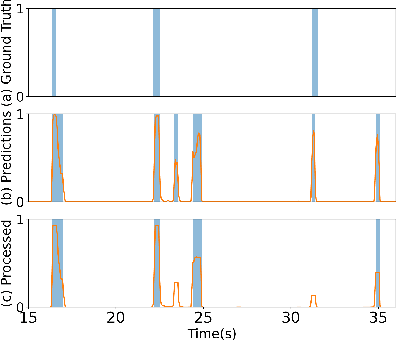
Non-linguistic filler words, such as "uh" or "um", are prevalent in spontaneous speech and serve as indicators for expressing hesitation or uncertainty. Previous works for detecting certain non-linguistic filler words are highly dependent on transcriptions from a well-established commercial automatic speech recognition (ASR) system. However, certain ASR systems are not universally accessible from many aspects, e.g., budget, target languages, and computational power. In this work, we investigate filler word detection system that does not depend on ASR systems. We show that, by using the structured state space sequence model (S4) and neural semi-Markov conditional random fields (semi-CRFs), we achieve an absolute F1 improvement of 6.4% (segment level) and 3.1% (event level) on the PodcastFillers dataset. We also conduct a qualitative analysis on the detected results to analyze the limitations of our proposed system.
Filler Word Detection and Classification: A Dataset and Benchmark
Mar 28, 2022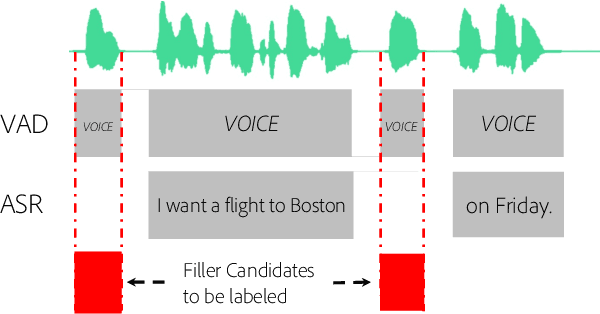
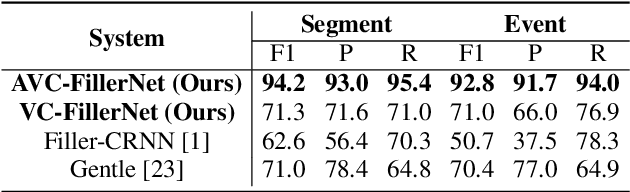
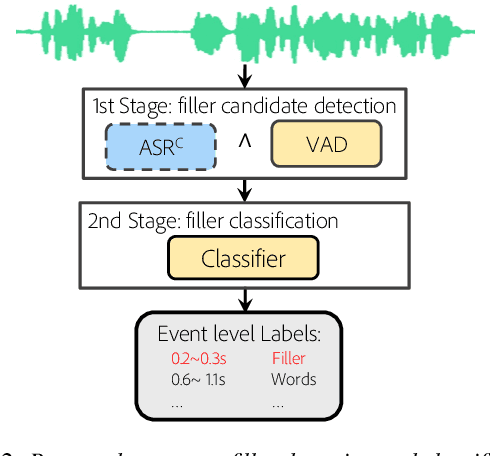

Filler words such as `uh' or `um' are sounds or words people use to signal they are pausing to think. Finding and removing filler words from recordings is a common and tedious task in media editing. Automatically detecting and classifying filler words could greatly aid in this task, but few studies have been published on this problem. A key reason is the absence of a dataset with annotated filler words for training and evaluation. In this work, we present a novel speech dataset, PodcastFillers, with 35K annotated filler words and 50K annotations of other sounds that commonly occur in podcasts such as breaths, laughter, and word repetitions. We propose a pipeline that leverages VAD and ASR to detect filler candidates and a classifier to distinguish between filler word types. We evaluate our proposed pipeline on PodcastFillers, compare to several baselines, and present a detailed ablation study. In particular, we evaluate the importance of using ASR and how it compares to a transcription-free approach resembling keyword spotting. We show that our pipeline obtains state-of-the-art results, and that leveraging ASR strongly outperforms a keyword spotting approach. We make PodcastFillers publicly available, and hope our work serves as a benchmark for future research.
Neural Pitch-Shifting and Time-Stretching with Controllable LPCNet
Oct 05, 2021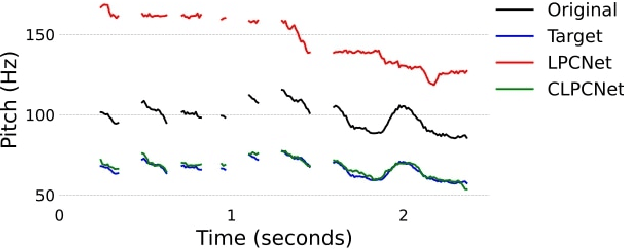
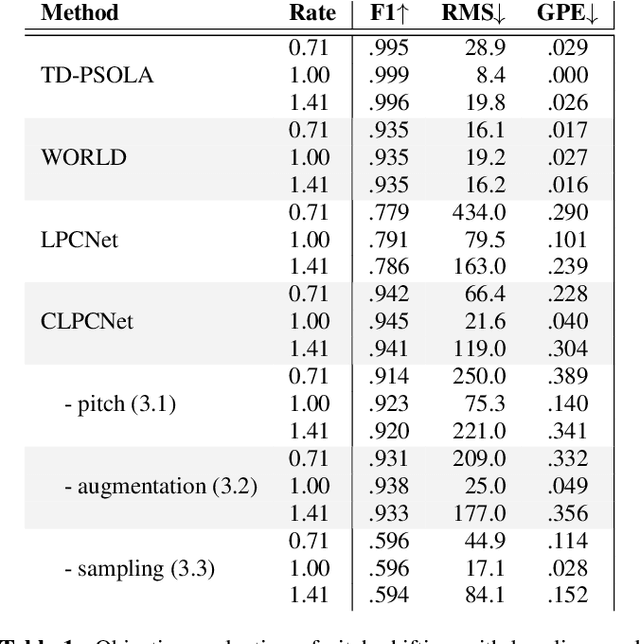
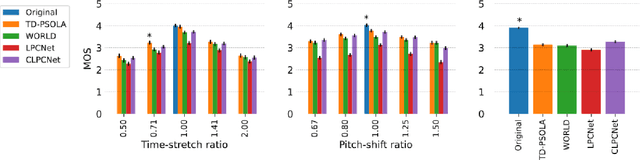
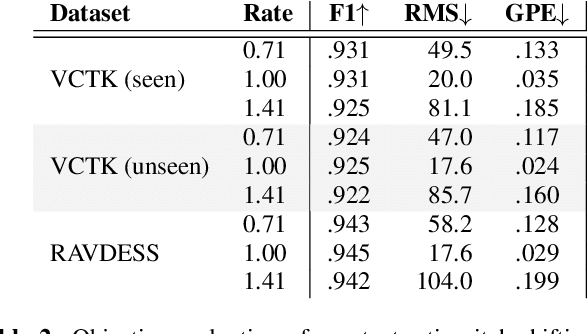
Modifying the pitch and timing of an audio signal are fundamental audio editing operations with applications in speech manipulation, audio-visual synchronization, and singing voice editing and synthesis. Thus far, methods for pitch-shifting and time-stretching that use digital signal processing (DSP) have been favored over deep learning approaches due to their speed and relatively higher quality. However, even existing DSP-based methods for pitch-shifting and time-stretching induce artifacts that degrade audio quality. In this paper, we propose Controllable LPCNet (CLPCNet), an improved LPCNet vocoder capable of pitch-shifting and time-stretching of speech. For objective evaluation, we show that CLPCNet performs pitch-shifting of speech on unseen datasets with high accuracy relative to prior neural methods. For subjective evaluation, we demonstrate that the quality and naturalness of pitch-shifting and time-stretching with CLPCNet on unseen datasets meets or exceeds competitive neural- or DSP-based approaches.
Context-Aware Prosody Correction for Text-Based Speech Editing
Feb 16, 2021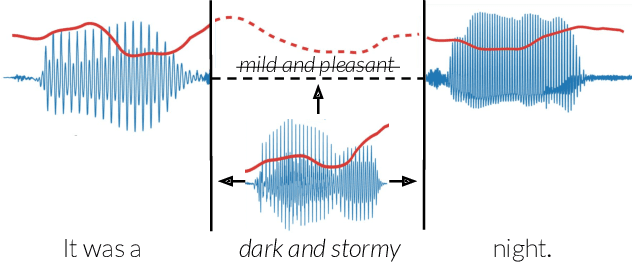

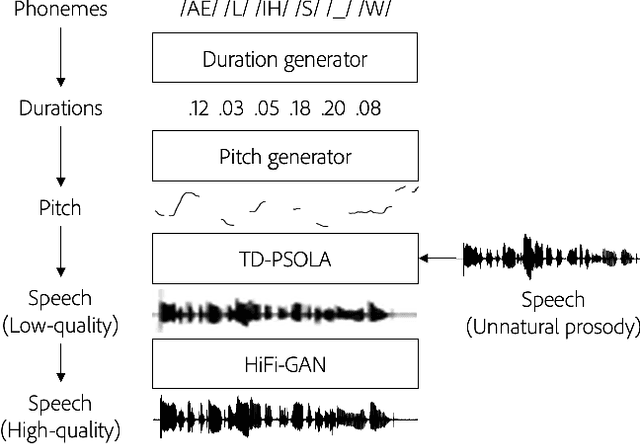
Text-based speech editors expedite the process of editing speech recordings by permitting editing via intuitive cut, copy, and paste operations on a speech transcript. A major drawback of current systems, however, is that edited recordings often sound unnatural because of prosody mismatches around edited regions. In our work, we propose a new context-aware method for more natural sounding text-based editing of speech. To do so, we 1) use a series of neural networks to generate salient prosody features that are dependent on the prosody of speech surrounding the edit and amenable to fine-grained user control 2) use the generated features to control a standard pitch-shift and time-stretch method and 3) apply a denoising neural network to remove artifacts induced by the signal manipulation to yield a high-fidelity result. We evaluate our approach using a subjective listening test, provide a detailed comparative analysis, and conclude several interesting insights.