 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscription free filler word detection with Neural semi-CRFs
Paper and Code
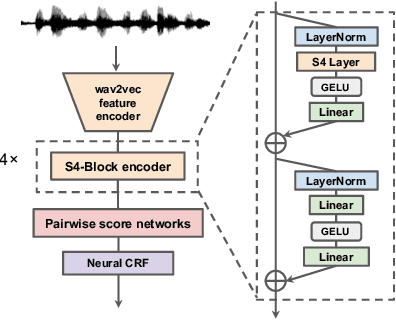
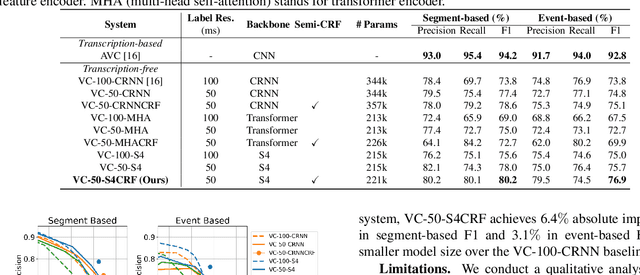
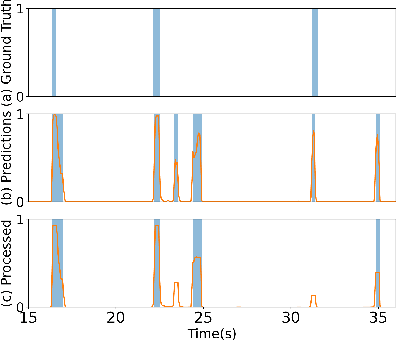
Non-linguistic filler words, such as "uh" or "um", are prevalent in spontaneous speech and serve as indicators for expressing hesitation or uncertainty. Previous works for detecting certain non-linguistic filler words are highly dependent on transcriptions from a well-established commercial automatic speech recognition (ASR) system. However, certain ASR systems are not universally accessible from many aspects, e.g., budget, target languages, and computational power. In this work, we investigate filler word detection system that does not depend on ASR systems. We show that, by using the structured state space sequence model (S4) and neural semi-Markov conditional random fields (semi-CRFs), we achieve an absolute F1 improvement of 6.4% (segment level) and 3.1% (event level) on the PodcastFillers dataset. We also conduct a qualitative analysis on the detected results to analyze the limitations of our proposed system.