 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Multi-Instrument Music Transcription: Results from the 2025 AMT Challenge
Mar 29, 2026This paper presents the results of the 2025 Automatic Music Transcription (AMT) Challenge, an online competition to benchmark progress in multi-instrument transcription. Eight teams submitted valid solutions; two outperformed the baseline MT3 model. The results highlight both advances in transcription accuracy and the remaining difficulties in handling polyphony and timbre variation. We conclude with directions for future challenges: broader genre coverage and stronger emphasis on instrument detection.
Scoring Intervals using Non-Hierarchical Transformer For Automatic Piano Transcription
Apr 17, 2024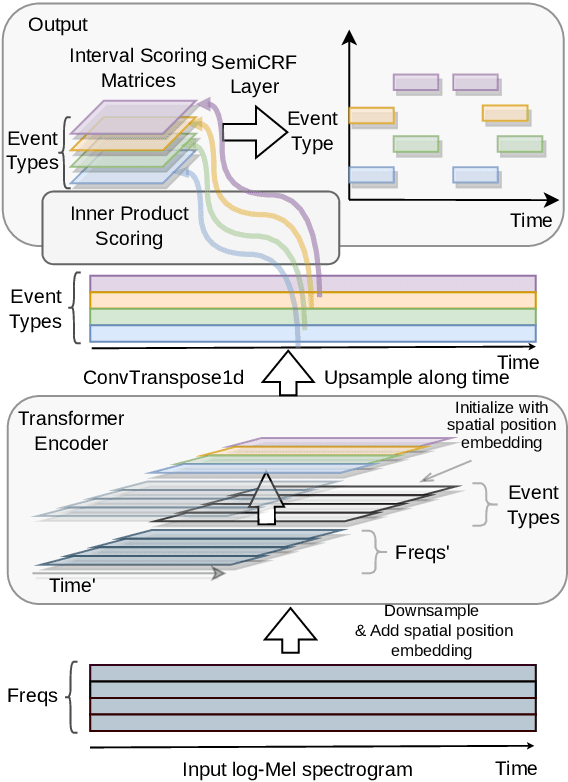

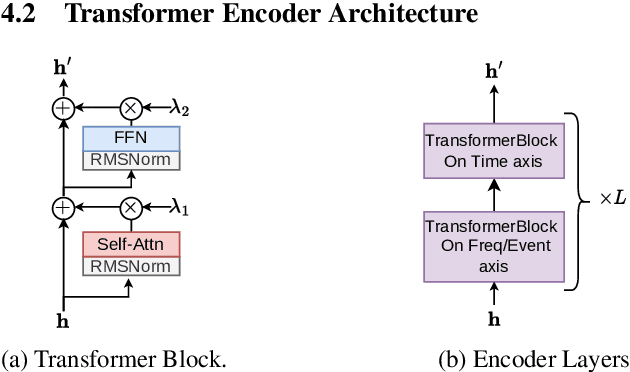
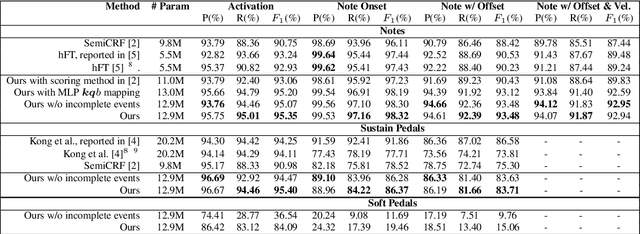
The neural semi-Markov Conditional Random Field (semi-CRF) framework has demonstrated promise for event-based piano transcription. In this framework, all events (notes or pedals) are represented as closed intervals tied to specific event types. The neural semi-CRF approach requires an interval scoring matrix that assigns a score for every candidate interval. However, designing an efficient and expressive architecture for scoring intervals is not trivial. In this paper, we introduce a simple method for scoring intervals using scaled inner product operations that resemble how attention scoring is done in transformers. We show theoretically that, due to the special structure from encoding the non-overlapping intervals, under a mild condition, the inner product operations are expressive enough to represent an ideal scoring matrix that can yield the correct transcription result. We then demonstrate that an encoder-only non-hierarchical transformer backbone, operating only on a low-time-resolution feature map, is capable of transcribing piano notes and pedals with high accuracy and time precision. The experiment shows that our approach achieves the new state-of-the-art performance across all subtasks in terms of the F1 measure on the Maestro dataset.
Transcription free filler word detection with Neural semi-CRFs
Mar 11, 2023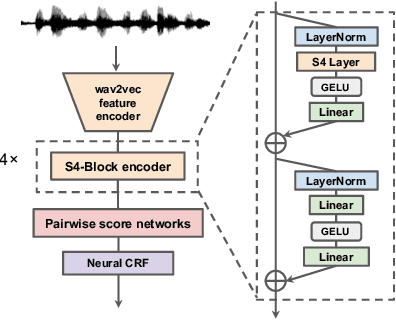
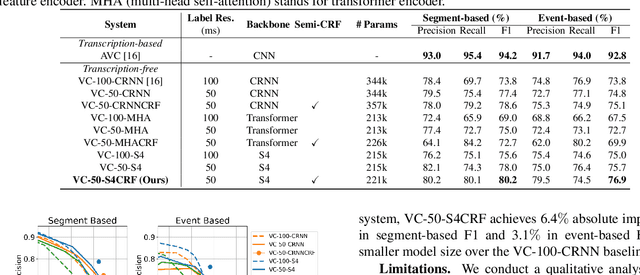
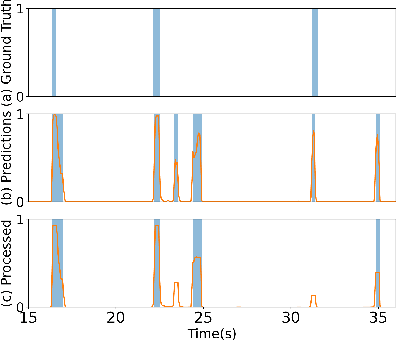
Non-linguistic filler words, such as "uh" or "um", are prevalent in spontaneous speech and serve as indicators for expressing hesitation or uncertainty. Previous works for detecting certain non-linguistic filler words are highly dependent on transcriptions from a well-established commercial automatic speech recognition (ASR) system. However, certain ASR systems are not universally accessible from many aspects, e.g., budget, target languages, and computational power. In this work, we investigate filler word detection system that does not depend on ASR systems. We show that, by using the structured state space sequence model (S4) and neural semi-Markov conditional random fields (semi-CRFs), we achieve an absolute F1 improvement of 6.4% (segment level) and 3.1% (event level) on the PodcastFillers dataset. We also conduct a qualitative analysis on the detected results to analyze the limitations of our proposed system.