 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained and Interpretable Neural Speech Editing
Jul 07, 2024

Fine-grained editing of speech attributes$\unicode{x2014}$such as prosody (i.e., the pitch, loudness, and phoneme durations), pronunciation, speaker identity, and formants$\unicode{x2014}$is useful for fine-tuning and fixing imperfections in human and AI-generated speech recordings for creation of podcasts, film dialogue, and video game dialogue. Existing speech synthesis systems use representations that entangle two or more of these attributes, prohibiting their use in fine-grained, disentangled editing. In this paper, we demonstrate the first disentangled and interpretable representation of speech with comparable subjective and objective vocoding reconstruction accuracy to Mel spectrograms. Our interpretable representation, combined with our proposed data augmentation method, enables training an existing neural vocoder to perform fast, accurate, and high-quality editing of pitch, duration, volume, timbral correlates of volume, pronunciation, speaker identity, and spectral balance.
High-Fidelity Neural Phonetic Posteriorgrams
Feb 27, 2024



A phonetic posteriorgram (PPG) is a time-varying categorical distribution over acoustic units of speech (e.g., phonemes). PPGs are a popular representation in speech generation due to their ability to disentangle pronunciation features from speaker identity, allowing accurate reconstruction of pronunciation (e.g., voice conversion) and coarse-grained pronunciation editing (e.g., foreign accent conversion). In this paper, we demonstrably improve the quality of PPGs to produce a state-of-the-art interpretable PPG representation. We train an off-the-shelf speech synthesizer using our PPG representation and show that high-quality PPGs yield independent control over pitch and pronunciation. We further demonstrate novel uses of PPGs, such as an acoustic pronunciation distance and fine-grained pronunciation control.
Crowdsourced and Automatic Speech Prominence Estimation
Oct 12, 2023



The prominence of a spoken word is the degree to which an average native listener perceives the word as salient or emphasized relative to its context. Speech prominence estimation is the process of assigning a numeric value to the prominence of each word in an utterance. These prominence labels are useful for linguistic analysis, as well as training automated systems to perform emphasis-controlled text-to-speech or emotion recognition. Manually annotating prominence is time-consuming and expensive, which motivates the development of automated methods for speech prominence estimation. However, developing such an automated system using machine-learning methods requires human-annotated training data. Using our system for acquiring such human annotations, we collect and open-source crowdsourced annotations of a portion of the LibriTTS dataset. We use these annotations as ground truth to train a neural speech prominence estimator that generalizes to unseen speakers, datasets, and speaking styles. We investigate design decisions for neural prominence estimation as well as how neural prominence estimation improves as a function of two key factors of annotation cost: dataset size and the number of annotations per utterance.
Cross-domain Neural Pitch and Periodicity Estimation
Jan 28, 2023



Pitch is a foundational aspect of our perception of audio signals. Pitch contours are commonly used to analyze speech and music signals and as input features for many audio tasks, including music transcription, singing voice synthesis, and prosody editing. In this paper, we describe a set of techniques for improving the accuracy of state-of-the-art neural pitch and periodicity estimators. We also introduce a novel entropy-based method for extracting periodicity and per-frame voiced-unvoiced classifications from statistical inference-based pitch estimators (e.g., neural networks), and show how to train a neural pitch estimator to simultaneously handle speech and music without performance degradation. While neural pitch trackers have historically been significantly slower than signal processing based pitch trackers, our estimator implementations approach the speed of state-of-the-art DSP-based pitch estimators on a standard CPU, but with significantly more accurate pitch and periodicity estimation. Our experiments show that an accurate, cross-domain pitch and periodicity estimator written in PyTorch with a hopsize of ten milliseconds can run 11.2x faster than real-time on a Intel i9-9820X 10-core 3.30 GHz CPU or 408x faster than real-time on a NVIDIA GeForce RTX 3090 GPU without hardware optimization. We release all of our code and models as Pitch-Estimating Neural Networks (penn), an open-source, pip-installable Python module for training, evaluating, and performing inference with pitch- and periodicity-estimating neural networks. The code for penn is available at https://github.com/interactiveaudiolab/penn.
Music Separation Enhancement with Generative Modeling
Aug 26, 2022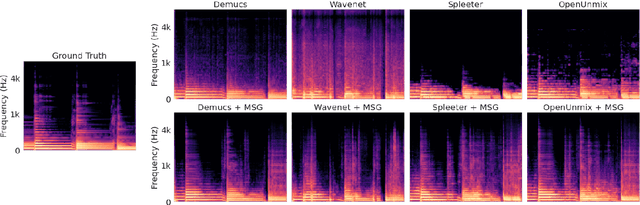
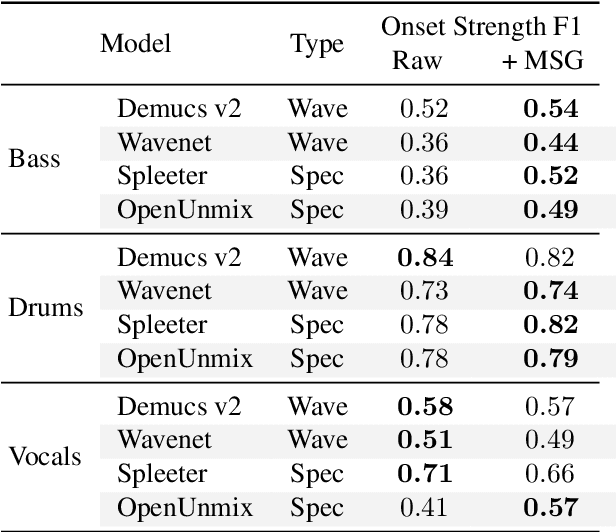
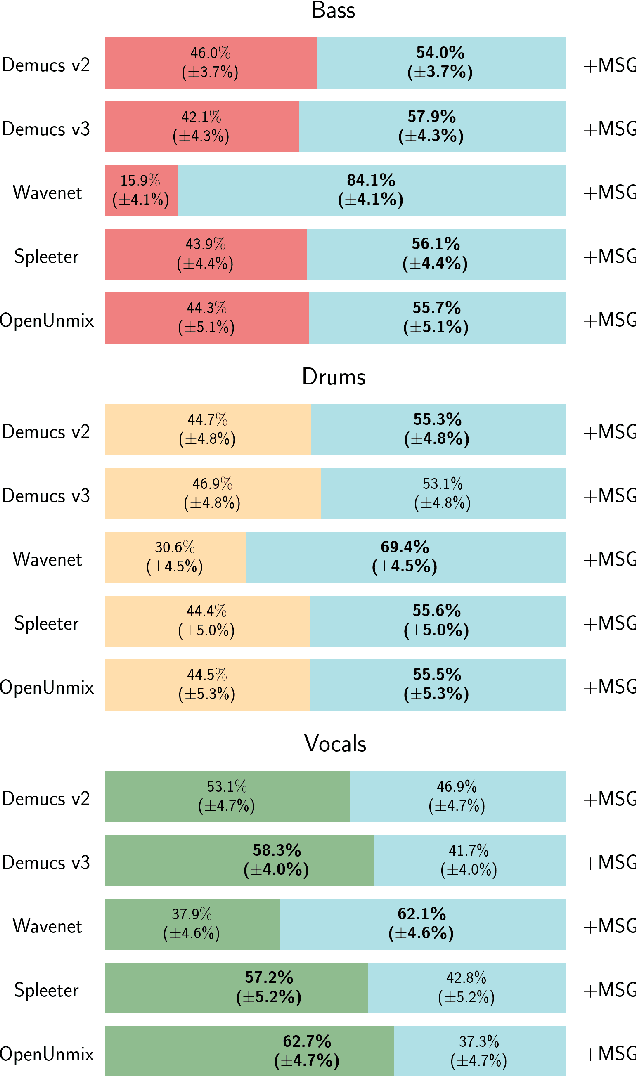
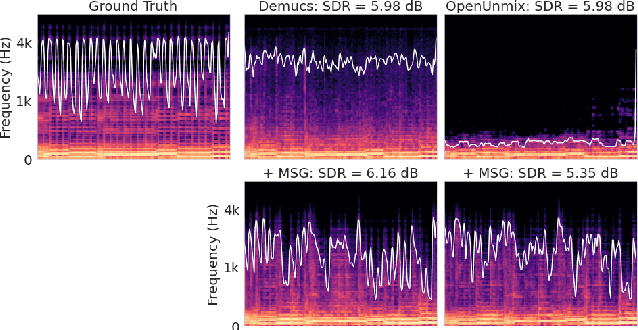
Despite phenomenal progress in recent years, state-of-the-art music separation systems produce source estimates with significant perceptual shortcomings, such as adding extraneous noise or removing harmonics. We propose a post-processing model (the Make it Sound Good (MSG) post-processor) to enhance the output of music source separation systems. We apply our post-processing model to state-of-the-art waveform-based and spectrogram-based music source separators, including a separator unseen by MSG during training. Our analysis of the errors produced by source separators shows that waveform models tend to introduce more high-frequency noise, while spectrogram models tend to lose transients and high frequency content. We introduce objective measures to quantify both kinds of errors and show MSG improves the source reconstruction of both kinds of errors. Crowdsourced subjective evaluations demonstrate that human listeners prefer source estimates of bass and drums that have been post-processed by MSG.
Reproducible Subjective Evaluation
Mar 08, 2022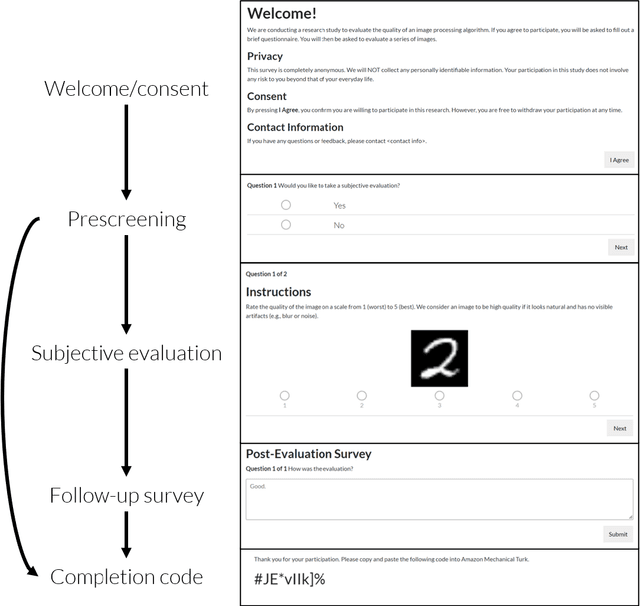

Human perceptual studies are the gold standard for the evaluation of many research tasks in machine learning, linguistics, and psychology. However, these studies require significant time and cost to perform. As a result, many researchers use objective measures that can correlate poorly with human evaluation. When subjective evaluations are performed, they are often not reported with sufficient detail to ensure reproducibility. We propose Reproducible Subjective Evaluation (ReSEval), an open-source framework for quickly deploying crowdsourced subjective evaluations directly from Python. ReSEval lets researchers launch A/B, ABX, Mean Opinion Score (MOS) and MUltiple Stimuli with Hidden Reference and Anchor (MUSHRA) tests on audio, image, text, or video data from a command-line interface or using one line of Python, making it as easy to run as objective evaluation. With ReSEval, researchers can reproduce each other's subjective evaluations by sharing a configuration file and the audio, image, text, or video files.
Chunked Autoregressive GAN for Conditional Waveform Synthesis
Oct 19, 2021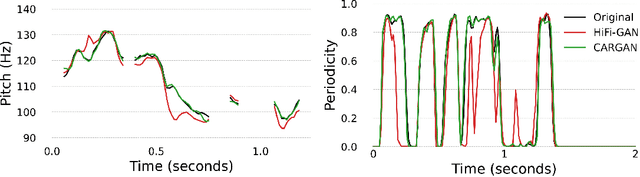

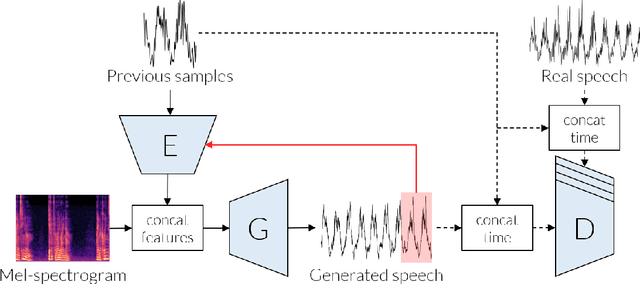
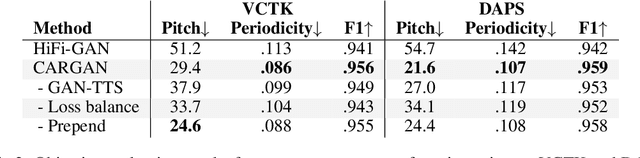
Conditional waveform synthesis models learn a distribution of audio waveforms given conditioning such as text, mel-spectrograms, or MIDI. These systems employ deep generative models that model the waveform via either sequential (autoregressive) or parallel (non-autoregressive) sampling. Generative adversarial networks (GANs) have become a common choice for non-autoregressive waveform synthesis. However, state-of-the-art GAN-based models produce artifacts when performing mel-spectrogram inversion. In this paper, we demonstrate that these artifacts correspond with an inability for the generator to learn accurate pitch and periodicity. We show that simple pitch and periodicity conditioning is insufficient for reducing this error relative to using autoregression. We discuss the inductive bias that autoregression provides for learning the relationship between instantaneous frequency and phase, and show that this inductive bias holds even when autoregressively sampling large chunks of the waveform during each forward pass. Relative to prior state-of- the-art GAN-based models, our proposed model, Chunked Autoregressive GAN (CARGAN) reduces pitch error by 40-60%, reduces training time by 58%, maintains a fast generation speed suitable for real-time or interactive applications, and maintains or improves subjective quality.
Neural Pitch-Shifting and Time-Stretching with Controllable LPCNet
Oct 05, 2021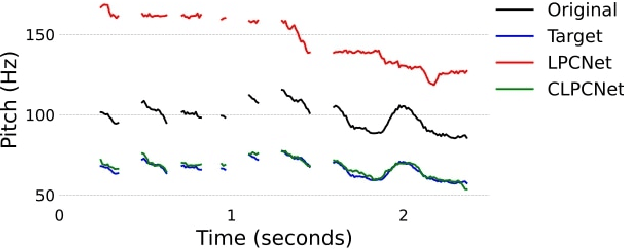
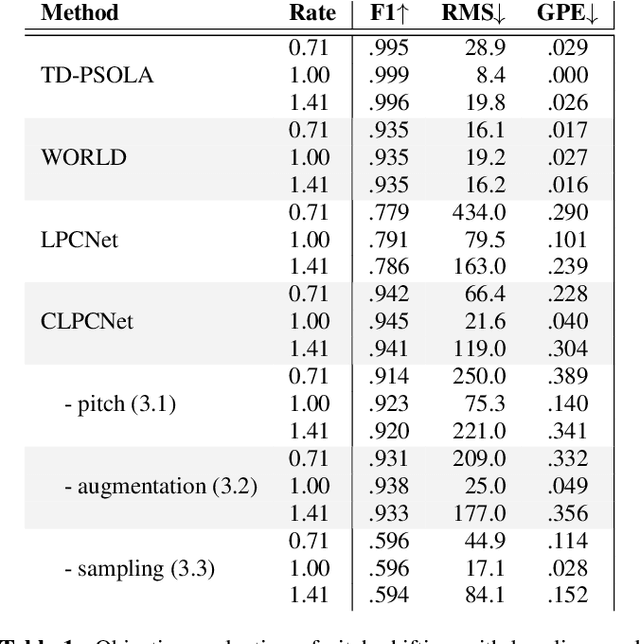
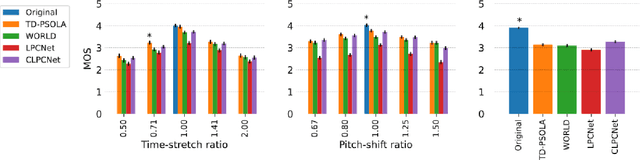
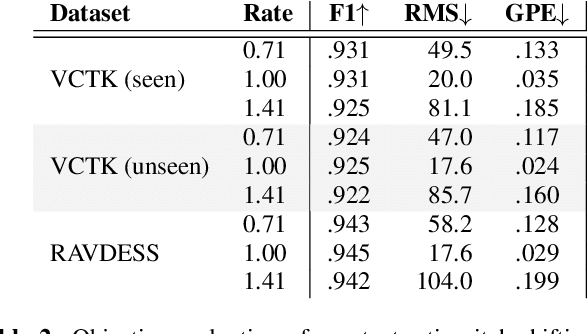
Modifying the pitch and timing of an audio signal are fundamental audio editing operations with applications in speech manipulation, audio-visual synchronization, and singing voice editing and synthesis. Thus far, methods for pitch-shifting and time-stretching that use digital signal processing (DSP) have been favored over deep learning approaches due to their speed and relatively higher quality. However, even existing DSP-based methods for pitch-shifting and time-stretching induce artifacts that degrade audio quality. In this paper, we propose Controllable LPCNet (CLPCNet), an improved LPCNet vocoder capable of pitch-shifting and time-stretching of speech. For objective evaluation, we show that CLPCNet performs pitch-shifting of speech on unseen datasets with high accuracy relative to prior neural methods. For subjective evaluation, we demonstrate that the quality and naturalness of pitch-shifting and time-stretching with CLPCNet on unseen datasets meets or exceeds competitive neural- or DSP-based approaches.
Context-Aware Prosody Correction for Text-Based Speech Editing
Feb 16, 2021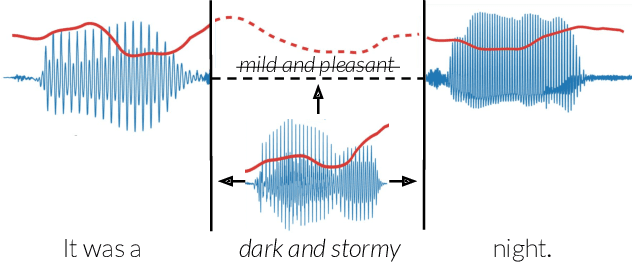

Text-based speech editors expedite the process of editing speech recordings by permitting editing via intuitive cut, copy, and paste operations on a speech transcript. A major drawback of current systems, however, is that edited recordings often sound unnatural because of prosody mismatches around edited regions. In our work, we propose a new context-aware method for more natural sounding text-based editing of speech. To do so, we 1) use a series of neural networks to generate salient prosody features that are dependent on the prosody of speech surrounding the edit and amenable to fine-grained user control 2) use the generated features to control a standard pitch-shift and time-stretch method and 3) apply a denoising neural network to remove artifacts induced by the signal manipulation to yield a high-fidelity result. We evaluate our approach using a subjective listening test, provide a detailed comparative analysis, and conclude several interesting insights.
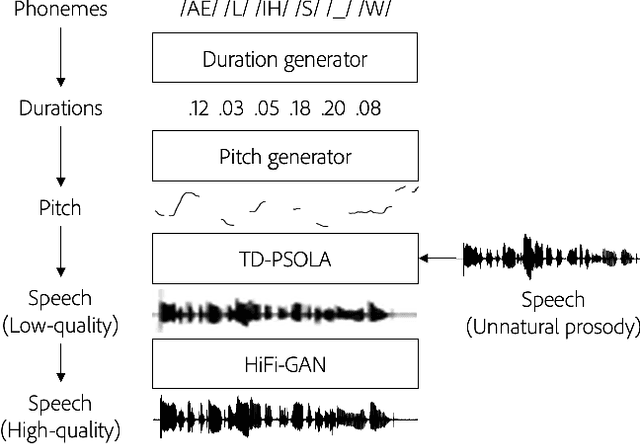
Controllable Neural Prosody Synthesis
Aug 11, 2020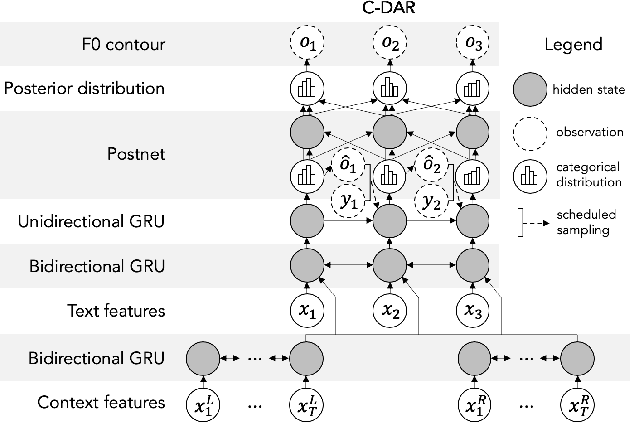

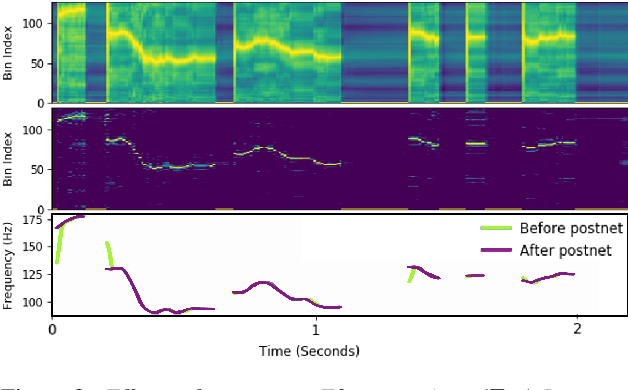
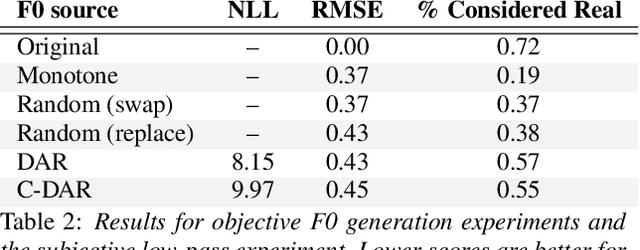
Speech synthesis has recently seen significant improvements in fidelity, driven by the advent of neural vocoders and neural prosody generators. However, these systems lack intuitive user controls over prosody, making them unable to rectify prosody errors (e.g., misplaced emphases and contextually inappropriate emotions) or generate prosodies with diverse speaker excitement levels and emotions. We address these limitations with a user-controllable, context-aware neural prosody generator. Given a real or synthesized speech recording, our model allows a user to input prosody constraints for certain time frames and generates the remaining time frames from input text and contextual prosody. We also propose a pitch-shifting neural vocoder to modify input speech to match the synthesized prosody. Through objective and subjective evaluations we show that we can successfully incorporate user control into our prosody generation model without sacrificing the overall naturalness of the synthesized speech.