 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffsetBias: Leveraging Debiased Data for Tuning Evaluators
Jul 09, 2024



Employing Large Language Models (LLMs) to assess the quality of generated responses, such as prompting instruct-tuned models or fine-tuning judge models, has become a widely adopted evaluation method. It is also known that such evaluators are vulnerable to biases, such as favoring longer responses. While it is important to overcome this problem, the specifics of these biases remain under-explored. In this work, we qualitatively identify six types of biases inherent in various judge models. We propose EvalBiasBench as a meta-evaluation collection of hand-crafted test cases for each bias type. Additionally, we present de-biasing dataset construction methods and the associated preference dataset OffsetBias. Experimental results demonstrate that fine-tuning on our dataset significantly enhances the robustness of judge models against biases and improves performance across most evaluation scenarios. We release our datasets and the fine-tuned judge model to public.
HaRiM$^+$: Evaluating Summary Quality with Hallucination Risk
Nov 24, 2022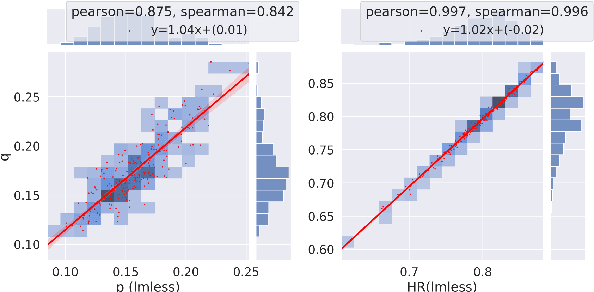
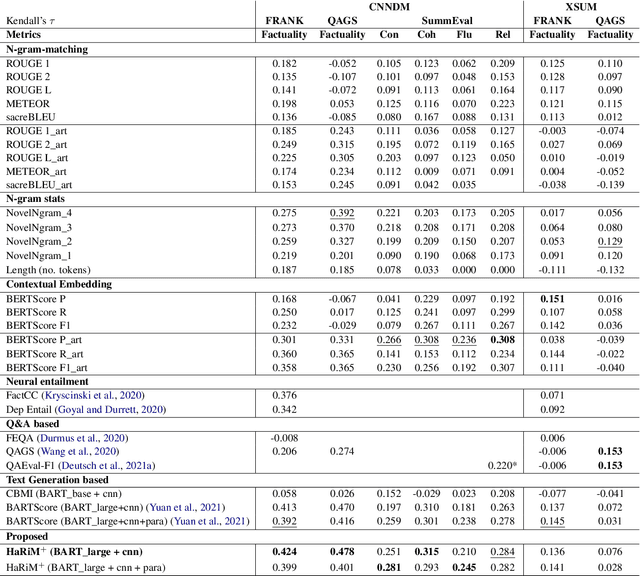
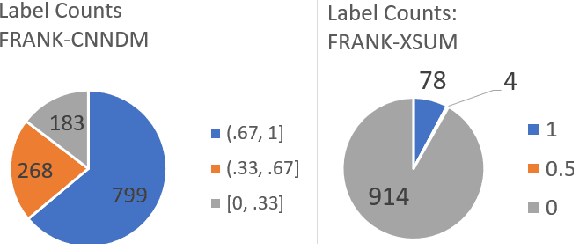
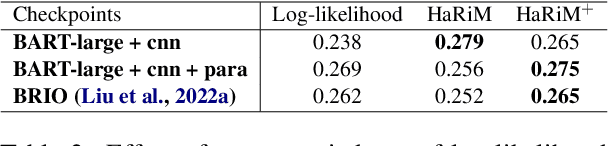
One of the challenges of developing a summarization model arises from the difficulty in measuring the factual inconsistency of the generated text. In this study, we reinterpret the decoder overconfidence-regularizing objective suggested in (Miao et al., 2021) as a hallucination risk measurement to better estimate the quality of generated summaries. We propose a reference-free metric, HaRiM+, which only requires an off-the-shelf summarization model to compute the hallucination risk based on token likelihoods. Deploying it requires no additional training of models or ad-hoc modules, which usually need alignment to human judgments. For summary-quality estimation, HaRiM+ records state-of-the-art correlation to human judgment on three summary-quality annotation sets: FRANK, QAGS, and SummEval. We hope that our work, which merits the use of summarization models, facilitates the progress of both automated evaluation and generation of summary.
* 9 pages (+ 21 pages of Appendix), AACL 2022