 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign-to-Distill: Trainable Attention Alignment for Knowledge Distillation in Neural Machine Translation
Mar 03, 2024The advent of scalable deep models and large datasets has improved the performance of Neural Machine Translation. Knowledge Distillation (KD) enhances efficiency by transferring knowledge from a teacher model to a more compact student model. However, KD approaches to Transformer architecture often rely on heuristics, particularly when deciding which teacher layers to distill from. In this paper, we introduce the 'Align-to-Distill' (A2D) strategy, designed to address the feature mapping problem by adaptively aligning student attention heads with their teacher counterparts during training. The Attention Alignment Module in A2D performs a dense head-by-head comparison between student and teacher attention heads across layers, turning the combinatorial mapping heuristics into a learning problem. Our experiments show the efficacy of A2D, demonstrating gains of up to +3.61 and +0.63 BLEU points for WMT-2022 De->Dsb and WMT-2014 En->De, respectively, compared to Transformer baselines.
HaRiM$^+$: Evaluating Summary Quality with Hallucination Risk
Nov 24, 2022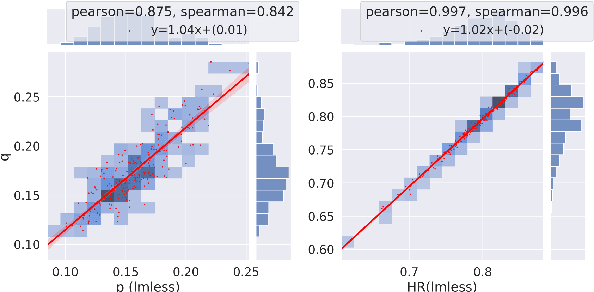
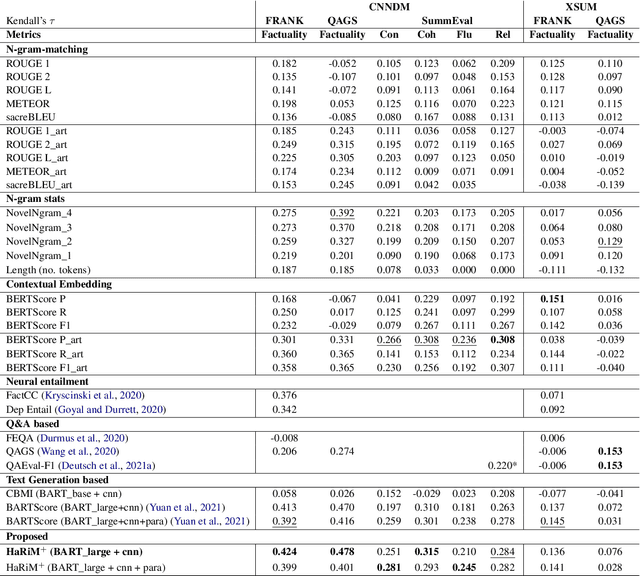
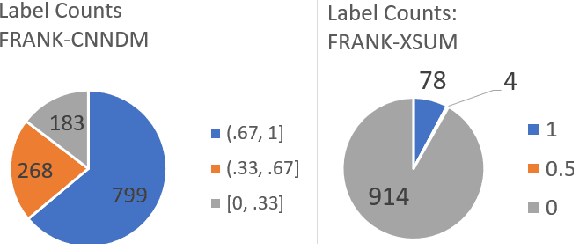
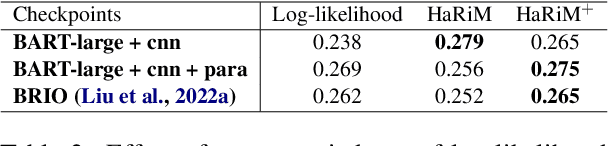
One of the challenges of developing a summarization model arises from the difficulty in measuring the factual inconsistency of the generated text. In this study, we reinterpret the decoder overconfidence-regularizing objective suggested in (Miao et al., 2021) as a hallucination risk measurement to better estimate the quality of generated summaries. We propose a reference-free metric, HaRiM+, which only requires an off-the-shelf summarization model to compute the hallucination risk based on token likelihoods. Deploying it requires no additional training of models or ad-hoc modules, which usually need alignment to human judgments. For summary-quality estimation, HaRiM+ records state-of-the-art correlation to human judgment on three summary-quality annotation sets: FRANK, QAGS, and SummEval. We hope that our work, which merits the use of summarization models, facilitates the progress of both automated evaluation and generation of summary.
* 9 pages (+ 21 pages of Appendix), AACL 2022
May the Force Be with Your Copy Mechanism: Enhanced Supervised-Copy Method for Natural Language Generation
Dec 20, 2021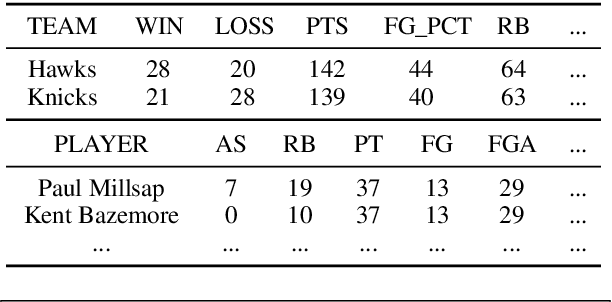
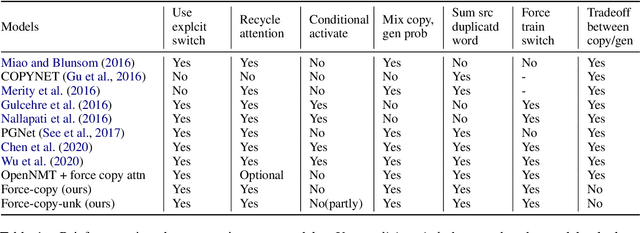
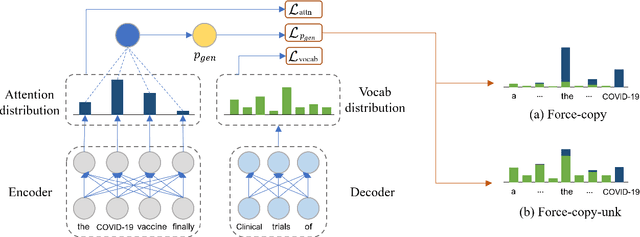
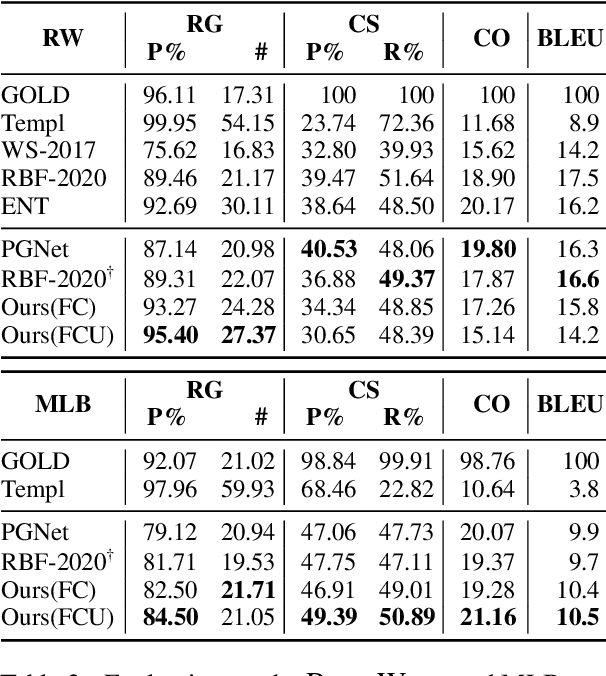
Recent neural sequence-to-sequence models with a copy mechanism have achieved remarkable progress in various text generation tasks. These models addressed out-of-vocabulary problems and facilitated the generation of rare words. However, the identification of the word which needs to be copied is difficult, as observed by prior copy models, which suffer from incorrect generation and lacking abstractness. In this paper, we propose a novel supervised approach of a copy network that helps the model decide which words need to be copied and which need to be generated. Specifically, we re-define the objective function, which leverages source sequences and target vocabularies as guidance for copying. The experimental results on data-to-text generation and abstractive summarization tasks verify that our approach enhances the copying quality and improves the degree of abstractness.
SANVis: Visual Analytics for Understanding Self-Attention Networks
Sep 13, 2019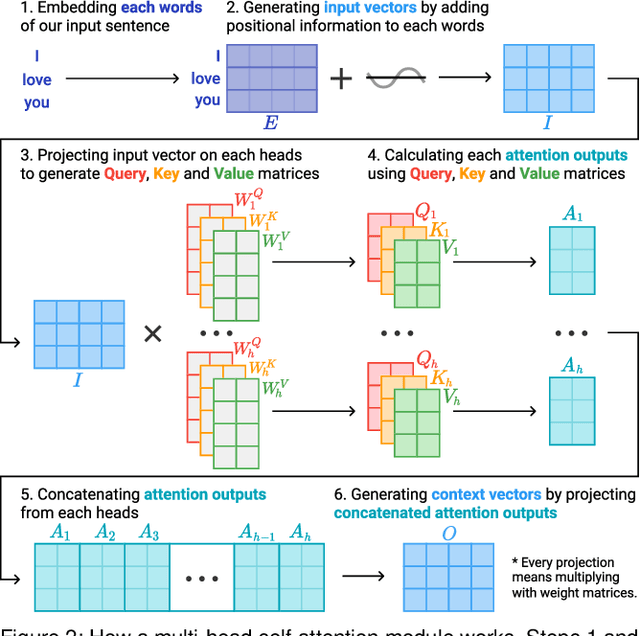
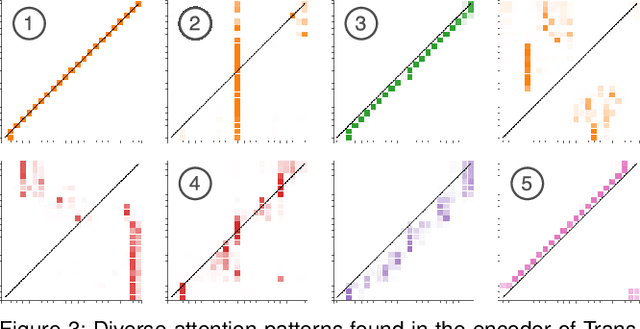
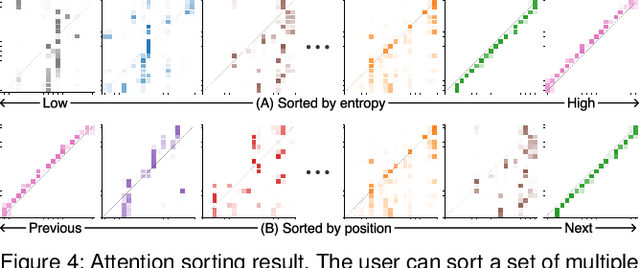
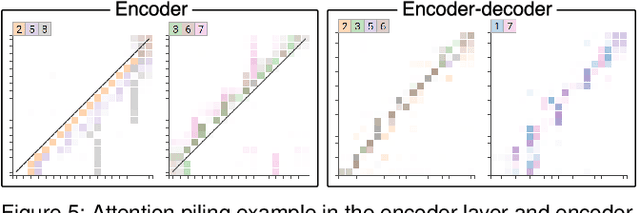
Attention networks, a deep neural network architecture inspired by humans' attention mechanism, have seen significant success in image captioning, machine translation, and many other applications. Recently, they have been further evolved into an advanced approach called multi-head self-attention networks, which can encode a set of input vectors, e.g., word vectors in a sentence, into another set of vectors. Such encoding aims at simultaneously capturing diverse syntactic and semantic features within a set, each of which corresponds to a particular attention head, forming altogether multi-head attention. Meanwhile, the increased model complexity prevents users from easily understanding and manipulating the inner workings of models. To tackle the challenges, we present a visual analytics system called SANVis, which helps users understand the behaviors and the characteristics of multi-head self-attention networks. Using a state-of-the-art self-attention model called Transformer, we demonstrate usage scenarios of SANVis in machine translation tasks. Our system is available at http://short.sanvis.org
Question-Aware Sentence Gating Networks for Question and Answering
Jul 20, 2018
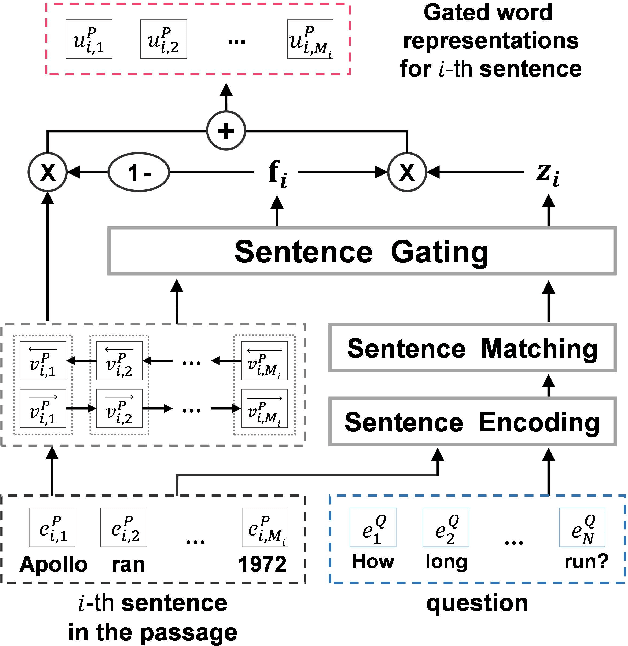
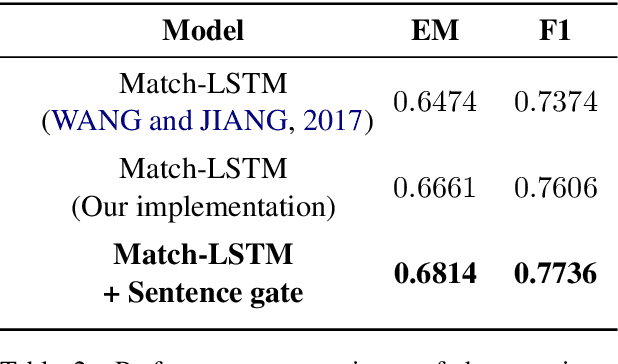
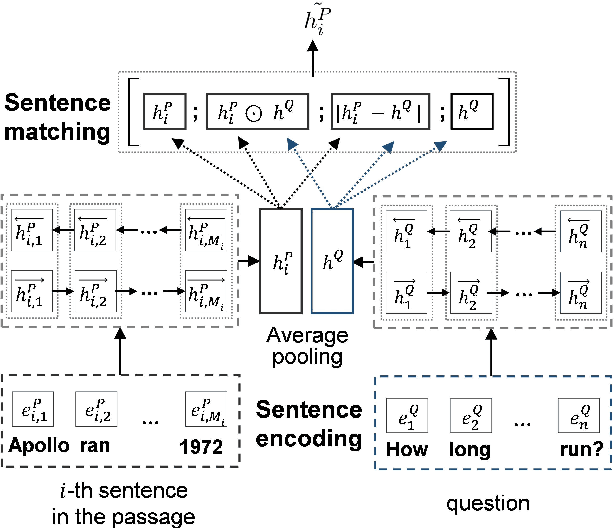
Machine comprehension question answering, which finds an answer to the question given a passage, involves high-level reasoning processes of understanding and tracking the relevant contents across various semantic units such as words, phrases, and sentences in a document. This paper proposes the novel question-aware sentence gating networks that directly incorporate the sentence-level information into word-level encoding processes. To this end, our model first learns question-aware sentence representations and then dynamically combines them with word-level representations, resulting in semantically meaningful word representations for QA tasks. Experimental results demonstrate that our approach consistently improves the accuracy over existing baseline approaches on various QA datasets and bears the wide applicability to other neural network-based QA models.