 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVarco Arena: A Tournament Approach to Reference-Free Benchmarking Large Language Models
Nov 02, 2024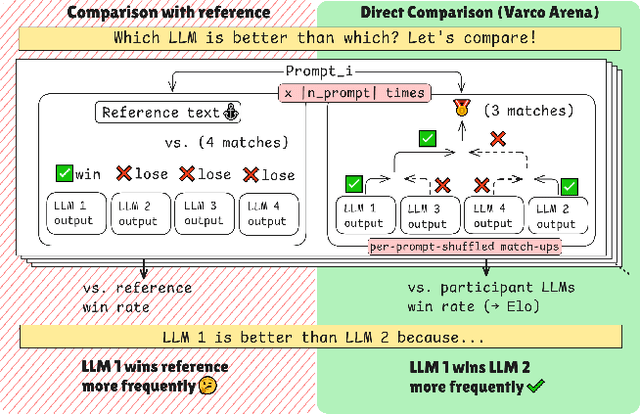

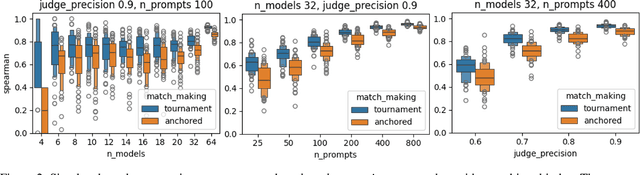

The rapid advancement of Large Language Models (LLMs) necessitates robust evaluation methodologies. Current benchmarking approaches often rely on comparing model outputs against predefined prompts and reference outputs. Relying on predefined reference outputs hinders flexible adaptation of benchmarks to the rapidly evolving capabilities of LLMs. This limitation necessitates periodic efforts to prepare new benchmarks. To keep pace with rapidly evolving LLM capabilities, we propose a more flexible benchmarking approach. Our method, \textit{\textbf{Varco Arena}}, provides reference-free benchmarking of LLMs in tournament style. \textit{\textbf{Varco Arena}} directly compares LLM outputs across a diverse set of prompts, determining model rankings through a single-elimination tournament structure. This direct pairwise comparison offers two key advantages: (1) Direct comparison, unmediated by reference text, more effectively orders competing LLMs, resulting in more reliable rankings, and (2) reference-free approach to benchmarking adds flexibility in updating benchmark prompts by eliminating the need for quality references. Our empirical results, supported by simulation experiments, demonstrate that the \textit{\textbf{Varco Arena}} tournament approach aligns better with the current Elo model for benchmarking LLMs. The alignment is measured in terms of Spearman correlation, showing improvement over current practice of benchmarking that use reference outputs as comparison \textit{anchor}s.
Align-to-Distill: Trainable Attention Alignment for Knowledge Distillation in Neural Machine Translation
Mar 03, 2024The advent of scalable deep models and large datasets has improved the performance of Neural Machine Translation. Knowledge Distillation (KD) enhances efficiency by transferring knowledge from a teacher model to a more compact student model. However, KD approaches to Transformer architecture often rely on heuristics, particularly when deciding which teacher layers to distill from. In this paper, we introduce the 'Align-to-Distill' (A2D) strategy, designed to address the feature mapping problem by adaptively aligning student attention heads with their teacher counterparts during training. The Attention Alignment Module in A2D performs a dense head-by-head comparison between student and teacher attention heads across layers, turning the combinatorial mapping heuristics into a learning problem. Our experiments show the efficacy of A2D, demonstrating gains of up to +3.61 and +0.63 BLEU points for WMT-2022 De->Dsb and WMT-2014 En->De, respectively, compared to Transformer baselines.
HaRiM$^+$: Evaluating Summary Quality with Hallucination Risk
Nov 24, 2022One of the challenges of developing a summarization model arises from the difficulty in measuring the factual inconsistency of the generated text. In this study, we reinterpret the decoder overconfidence-regularizing objective suggested in (Miao et al., 2021) as a hallucination risk measurement to better estimate the quality of generated summaries. We propose a reference-free metric, HaRiM+, which only requires an off-the-shelf summarization model to compute the hallucination risk based on token likelihoods. Deploying it requires no additional training of models or ad-hoc modules, which usually need alignment to human judgments. For summary-quality estimation, HaRiM+ records state-of-the-art correlation to human judgment on three summary-quality annotation sets: FRANK, QAGS, and SummEval. We hope that our work, which merits the use of summarization models, facilitates the progress of both automated evaluation and generation of summary.
* 9 pages (+ 21 pages of Appendix), AACL 2022
Learning to Write with Coherence From Negative Examples
Sep 22, 2022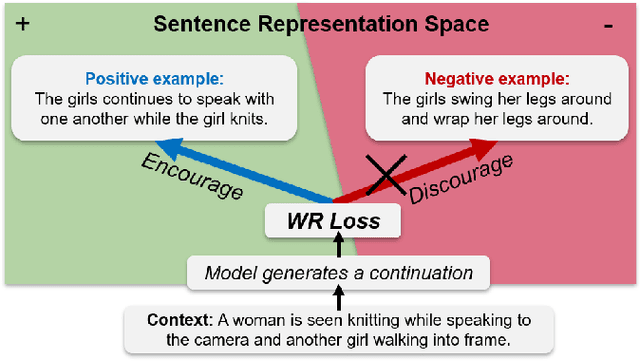
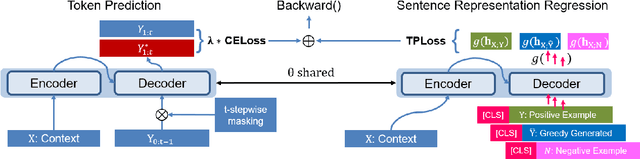
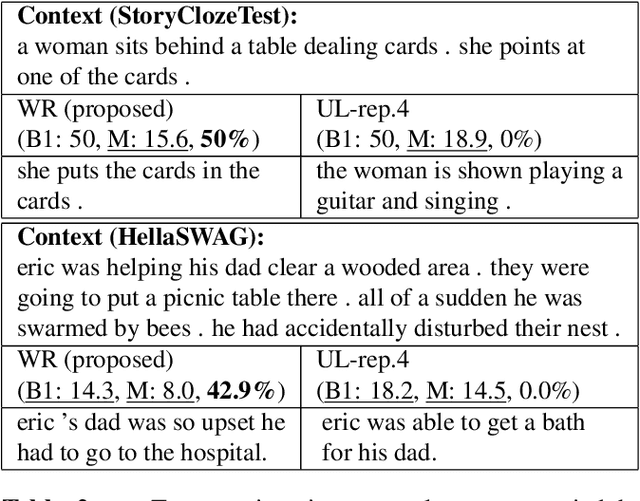
Coherence is one of the critical factors that determine the quality of writing. We propose writing relevance (WR) training method for neural encoder-decoder natural language generation (NLG) models which improves coherence of the continuation by leveraging negative examples. WR loss regresses the vector representation of the context and generated sentence toward positive continuation by contrasting it with the negatives. We compare our approach with Unlikelihood (UL) training in a text continuation task on commonsense natural language inference (NLI) corpora to show which method better models the coherence by avoiding unlikely continuations. The preference of our approach in human evaluation shows the efficacy of our method in improving coherence.
GLAC Net: GLocal Attention Cascading Networks for Multi-image Cued Story Generation
Jun 24, 2018
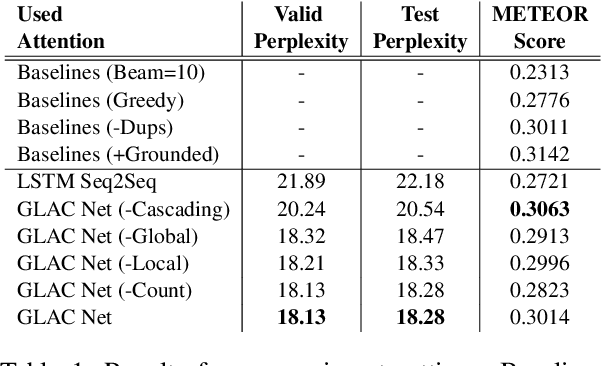
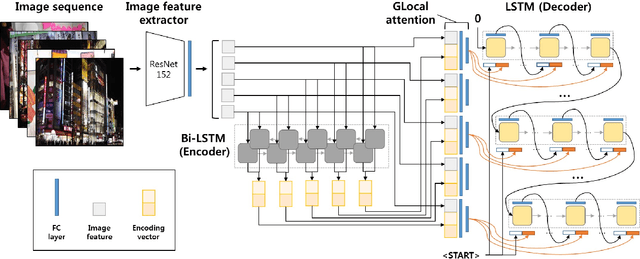

The task of multi-image cued story generation, such as visual storytelling dataset (VIST) challenge, is to compose multiple coherent sentences from a given sequence of images. The main difficulty is how to generate image-specific sentences within the context of overall images. Here we propose a deep learning network model, GLAC Net, that generates visual stories by combining global-local (glocal) attention and context cascading mechanisms. The model incorporates two levels of attention, i.e., overall encoding level and image feature level, to construct image-dependent sentences. While standard attention configuration needs a large number of parameters, the GLAC Net implements them in a very simple way via hard connections from the outputs of encoders or image features onto the sentence generators. The coherency of the generated story is further improved by conveying (cascading) the information of the previous sentence to the next sentence serially. We evaluate the performance of the GLAC Net on the visual storytelling dataset (VIST) and achieve very competitive results compared to the state-of-the-art techniques.