 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLAC Net: GLocal Attention Cascading Networks for Multi-image Cued Story Generation
Jun 24, 2018
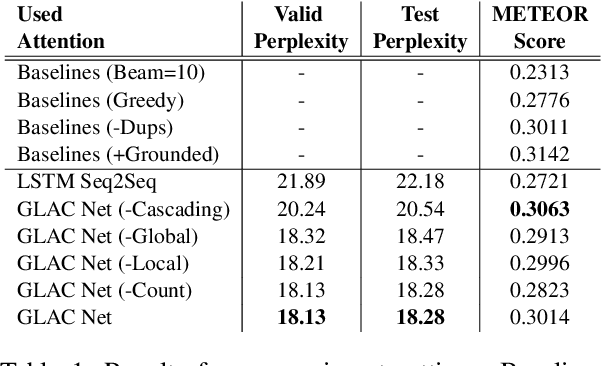
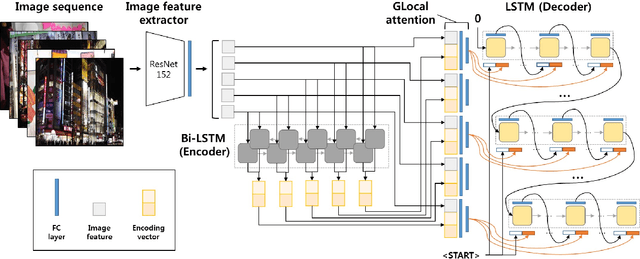

The task of multi-image cued story generation, such as visual storytelling dataset (VIST) challenge, is to compose multiple coherent sentences from a given sequence of images. The main difficulty is how to generate image-specific sentences within the context of overall images. Here we propose a deep learning network model, GLAC Net, that generates visual stories by combining global-local (glocal) attention and context cascading mechanisms. The model incorporates two levels of attention, i.e., overall encoding level and image feature level, to construct image-dependent sentences. While standard attention configuration needs a large number of parameters, the GLAC Net implements them in a very simple way via hard connections from the outputs of encoders or image features onto the sentence generators. The coherency of the generated story is further improved by conveying (cascading) the information of the previous sentence to the next sentence serially. We evaluate the performance of the GLAC Net on the visual storytelling dataset (VIST) and achieve very competitive results compared to the state-of-the-art techniques.
DeepStory: Video Story QA by Deep Embedded Memory Networks
Jul 04, 2017


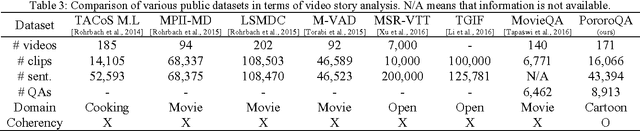
Question-answering (QA) on video contents is a significant challenge for achieving human-level intelligence as it involves both vision and language in real-world settings. Here we demonstrate the possibility of an AI agent performing video story QA by learning from a large amount of cartoon videos. We develop a video-story learning model, i.e. Deep Embedded Memory Networks (DEMN), to reconstruct stories from a joint scene-dialogue video stream using a latent embedding space of observed data. The video stories are stored in a long-term memory component. For a given question, an LSTM-based attention model uses the long-term memory to recall the best question-story-answer triplet by focusing on specific words containing key information. We trained the DEMN on a novel QA dataset of children's cartoon video series, Pororo. The dataset contains 16,066 scene-dialogue pairs of 20.5-hour videos, 27,328 fine-grained sentences for scene description, and 8,913 story-related QA pairs. Our experimental results show that the DEMN outperforms other QA models. This is mainly due to 1) the reconstruction of video stories in a scene-dialogue combined form that utilize the latent embedding and 2) attention. DEMN also achieved state-of-the-art results on the MovieQA benchmark.
Multimodal Residual Learning for Visual QA
Aug 31, 2016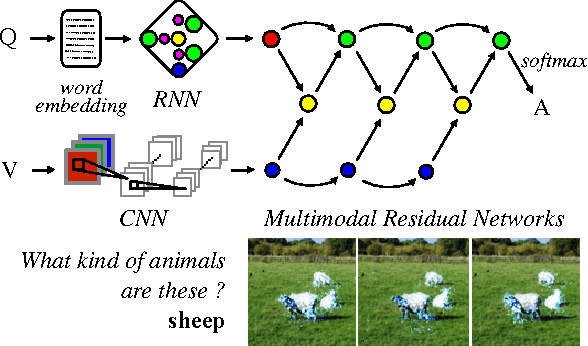
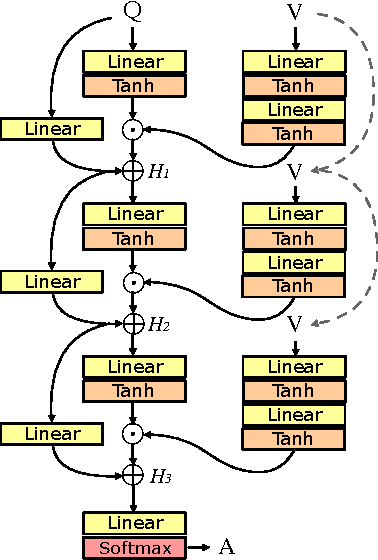
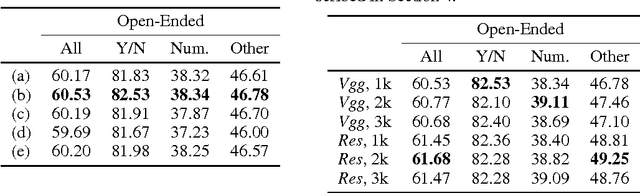
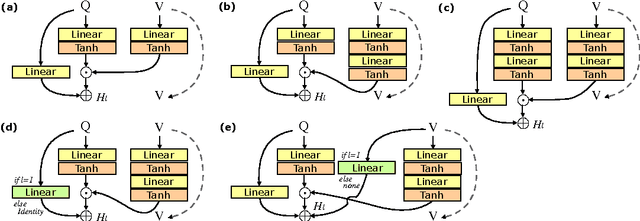
Deep neural networks continue to advance the state-of-the-art of image recognition tasks with various methods. However, applications of these methods to multimodality remain limited. We present Multimodal Residual Networks (MRN) for the multimodal residual learning of visual question-answering, which extends the idea of the deep residual learning. Unlike the deep residual learning, MRN effectively learns the joint representation from vision and language information. The main idea is to use element-wise multiplication for the joint residual mappings exploiting the residual learning of the attentional models in recent studies. Various alternative models introduced by multimodality are explored based on our study. We achieve the state-of-the-art results on the Visual QA dataset for both Open-Ended and Multiple-Choice tasks. Moreover, we introduce a novel method to visualize the attention effect of the joint representations for each learning block using back-propagation algorithm, even though the visual features are collapsed without spatial information.
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy
Jun 15, 2015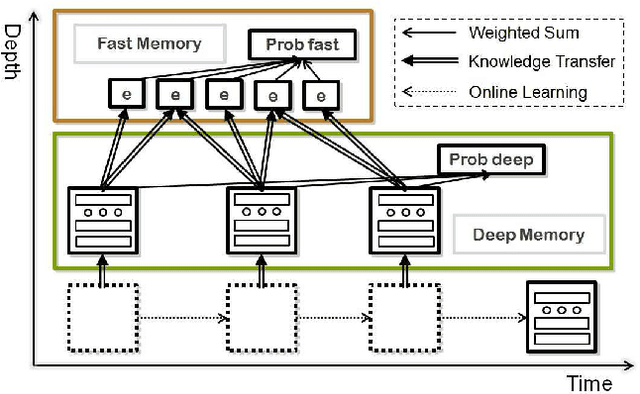
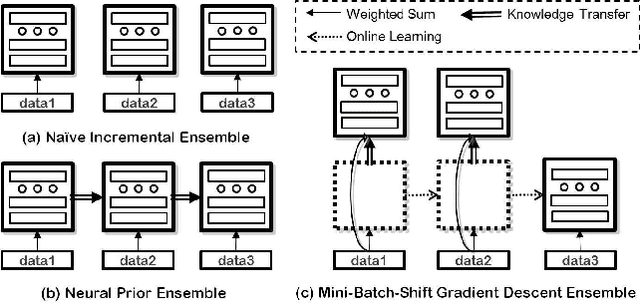
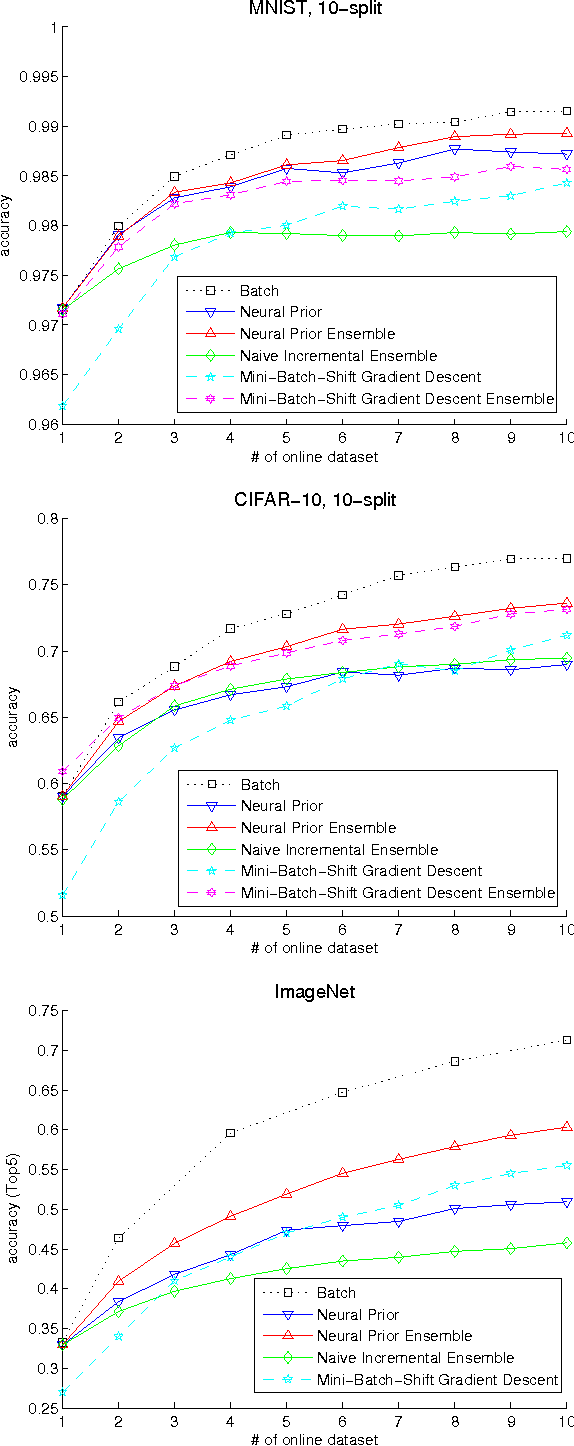
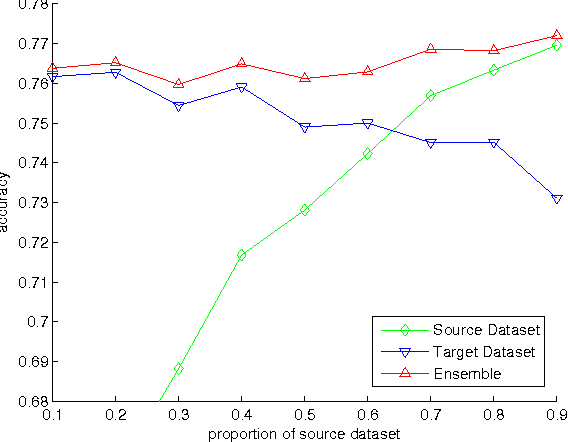
The online learning of deep neural networks is an interesting problem of machine learning because, for example, major IT companies want to manage the information of the massive data uploaded on the web daily, and this technology can contribute to the next generation of lifelong learning. We aim to train deep models from new data that consists of new classes, distributions, and tasks at minimal computational cost, which we call online deep learning. Unfortunately, deep neural network learning through classical online and incremental methods does not work well in both theory and practice. In this paper, we introduce dual memory architectures for online incremental deep learning. The proposed architecture consists of deep representation learners and fast learnable shallow kernel networks, both of which synergize to track the information of new data. During the training phase, we use various online, incremental ensemble, and transfer learning techniques in order to achieve lower error of the architecture. On the MNIST, CIFAR-10, and ImageNet image recognition tasks, the proposed dual memory architectures performs much better than the classical online and incremental ensemble algorithm, and their accuracies are similar to that of the batch learner.