 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaRiM$^+$: Evaluating Summary Quality with Hallucination Risk
Nov 24, 2022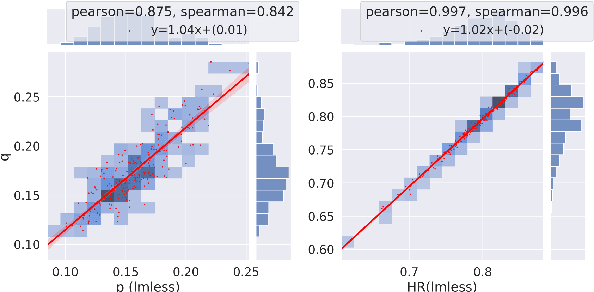
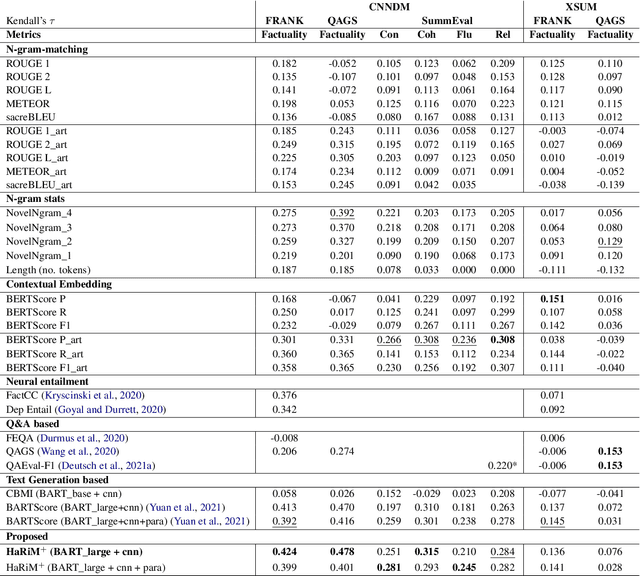
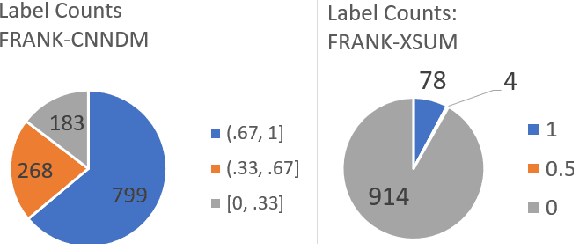
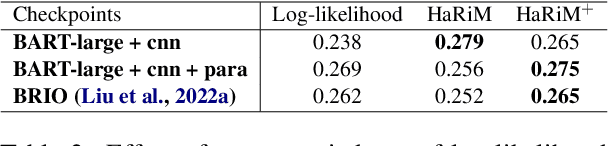
One of the challenges of developing a summarization model arises from the difficulty in measuring the factual inconsistency of the generated text. In this study, we reinterpret the decoder overconfidence-regularizing objective suggested in (Miao et al., 2021) as a hallucination risk measurement to better estimate the quality of generated summaries. We propose a reference-free metric, HaRiM+, which only requires an off-the-shelf summarization model to compute the hallucination risk based on token likelihoods. Deploying it requires no additional training of models or ad-hoc modules, which usually need alignment to human judgments. For summary-quality estimation, HaRiM+ records state-of-the-art correlation to human judgment on three summary-quality annotation sets: FRANK, QAGS, and SummEval. We hope that our work, which merits the use of summarization models, facilitates the progress of both automated evaluation and generation of summary.
* 9 pages (+ 21 pages of Appendix), AACL 2022
May the Force Be with Your Copy Mechanism: Enhanced Supervised-Copy Method for Natural Language Generation
Dec 20, 2021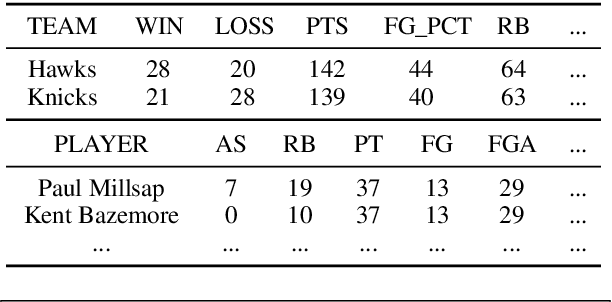
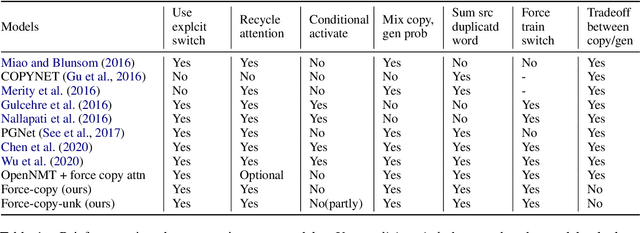
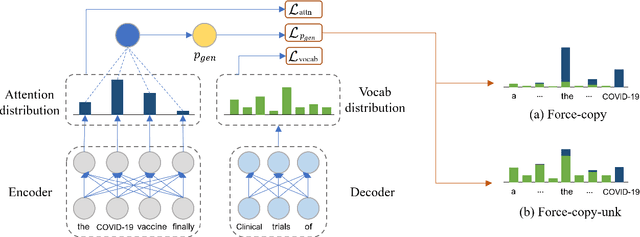
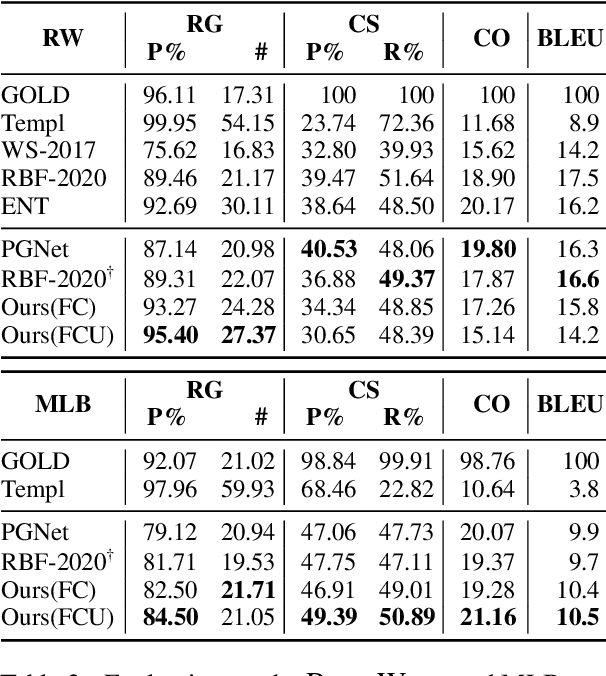
Recent neural sequence-to-sequence models with a copy mechanism have achieved remarkable progress in various text generation tasks. These models addressed out-of-vocabulary problems and facilitated the generation of rare words. However, the identification of the word which needs to be copied is difficult, as observed by prior copy models, which suffer from incorrect generation and lacking abstractness. In this paper, we propose a novel supervised approach of a copy network that helps the model decide which words need to be copied and which need to be generated. Specifically, we re-define the objective function, which leverages source sequences and target vocabularies as guidance for copying. The experimental results on data-to-text generation and abstractive summarization tasks verify that our approach enhances the copying quality and improves the degree of abstractness.