 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Write with Coherence From Negative Examples
Sep 22, 2022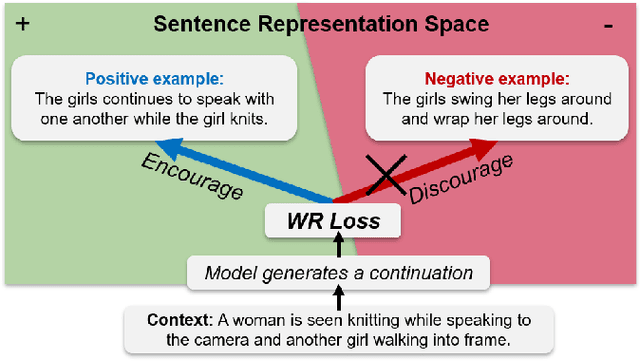
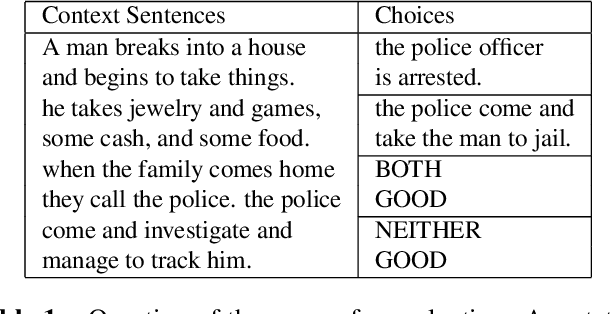
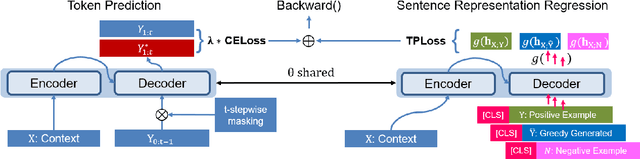
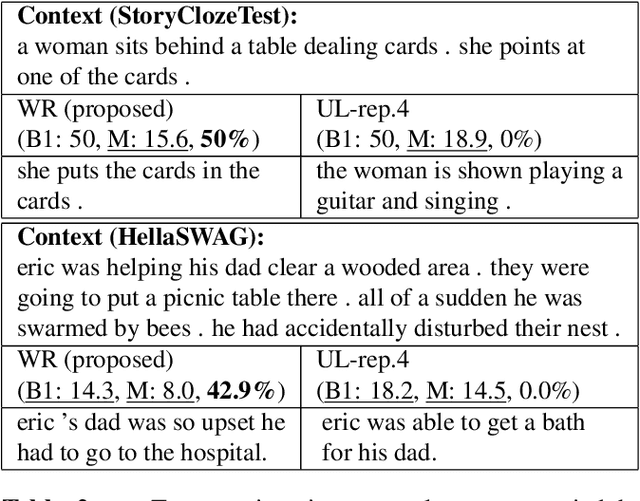
Coherence is one of the critical factors that determine the quality of writing. We propose writing relevance (WR) training method for neural encoder-decoder natural language generation (NLG) models which improves coherence of the continuation by leveraging negative examples. WR loss regresses the vector representation of the context and generated sentence toward positive continuation by contrasting it with the negatives. We compare our approach with Unlikelihood (UL) training in a text continuation task on commonsense natural language inference (NLI) corpora to show which method better models the coherence by avoiding unlikely continuations. The preference of our approach in human evaluation shows the efficacy of our method in improving coherence.
Human-Like Active Learning: Machines Simulating the Human Learning Process
Nov 07, 2020
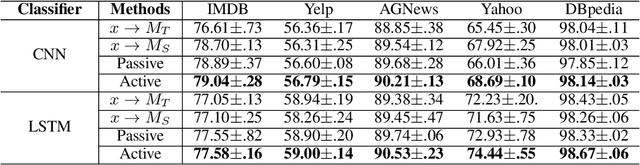
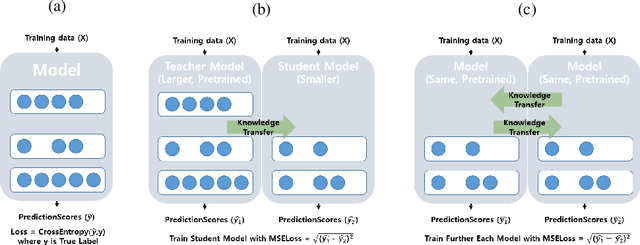
Although the use of active learning to increase learners' engagement has recently been introduced in a variety of methods, empirical experiments are lacking. In this study, we attempted to align two experiments in order to (1) make a hypothesis for machine and (2) empirically confirm the effect of active learning on learning. In Experiment 1, we compared the effect of a passive form of learning to active form of learning. The results showed that active learning had a greater learning outcomes than passive learning. In the machine experiment based on the human result, we imitated the human active learning as a form of knowledge distillation. The active learning framework performed better than the passive learning framework. In the end, we showed not only that we can make build better machine training framework through the human experiment result, but also empirically confirm the result of human experiment through imitated machine experiments; human-like active learning have crucial effect on learning performance.
Simulating Problem Difficulty in Arithmetic Cognition Through Dynamic Connectionist Models
May 30, 2019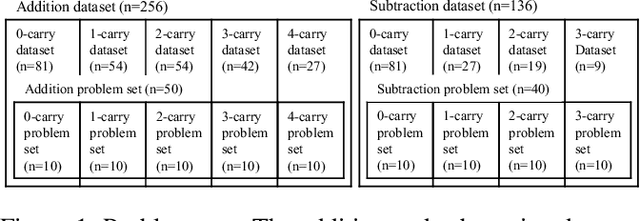
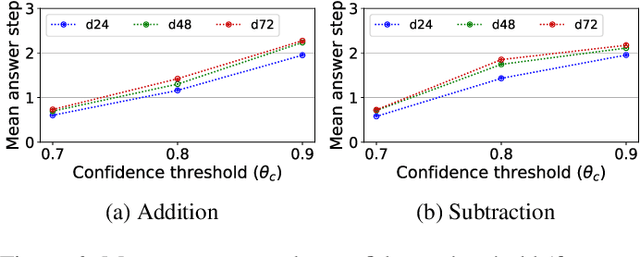
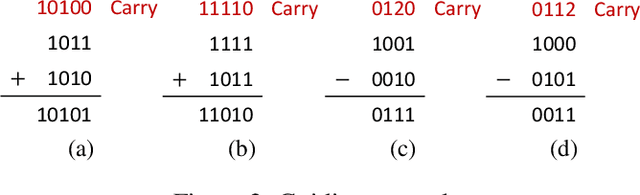

The present study aims to investigate similarities between how humans and connectionist models experience difficulty in arithmetic problems. Problem difficulty was operationalized by the number of carries involved in solving a given problem. Problem difficulty was measured in humans by response time, and in models by computational steps. The present study found that both humans and connectionist models experience difficulty similarly when solving binary addition and subtraction. Specifically, both agents found difficulty to be strictly increasing with respect to the number of carries. Another notable similarity is that problem difficulty increases more steeply in subtraction than in addition, for both humans and connectionist models. Further investigation on two model hyperparameters --- confidence threshold and hidden dimension --- shows higher confidence thresholds cause the model to take more computational steps to arrive at the correct answer. Likewise, larger hidden dimensions cause the model to take more computational steps to correctly answer arithmetic problems; however, this effect by hidden dimensions is negligible.
Constructing Hierarchical Q&A Datasets for Video Story Understanding
Apr 01, 2019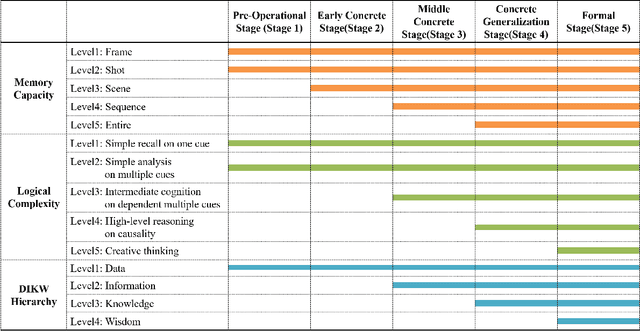
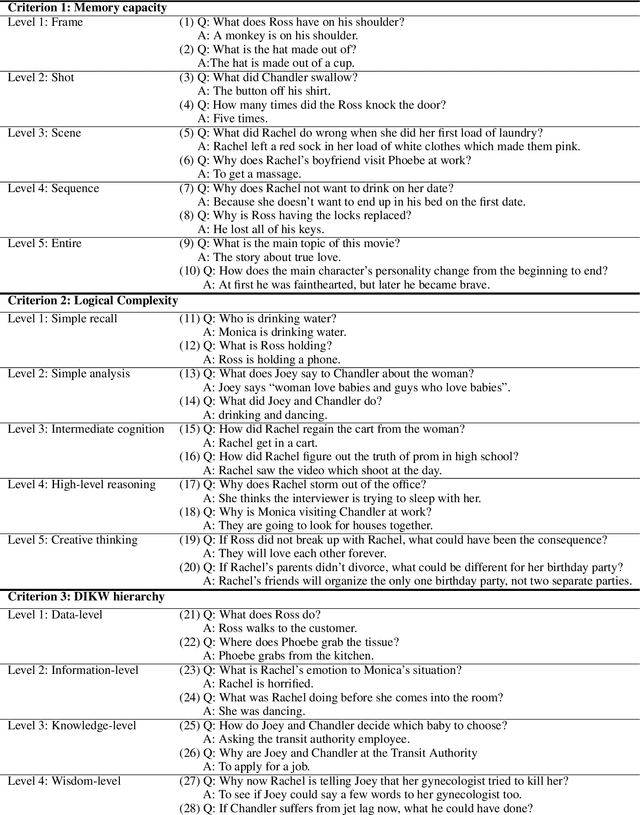
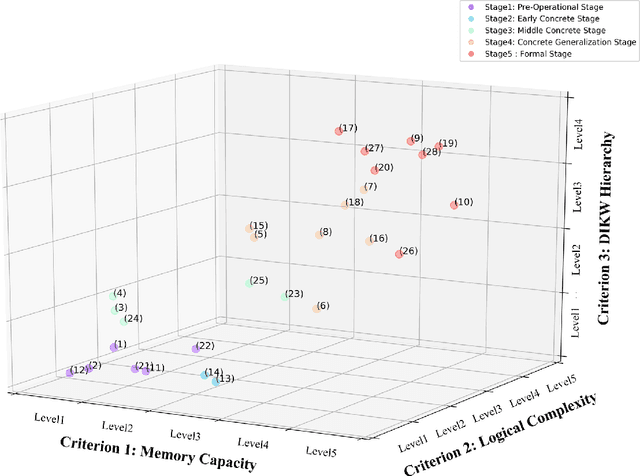
Video understanding is emerging as a new paradigm for studying human-like AI. Question-and-Answering (Q&A) is used as a general benchmark to measure the level of intelligence for video understanding. While several previous studies have suggested datasets for video Q&A tasks, they did not really incorporate story-level understanding, resulting in highly-biased and lack of variance in degree of question difficulty. In this paper, we propose a hierarchical method for building Q&A datasets, i.e. hierarchical difficulty levels. We introduce three criteria for video story understanding, i.e. memory capacity, logical complexity, and DIKW (Data-Information-Knowledge-Wisdom) pyramid. We discuss how three-dimensional map constructed from these criteria can be used as a metric for evaluating the levels of intelligence relating to video story understanding.
Dual Attention Networks for Visual Reference Resolution in Visual Dialog
Feb 25, 2019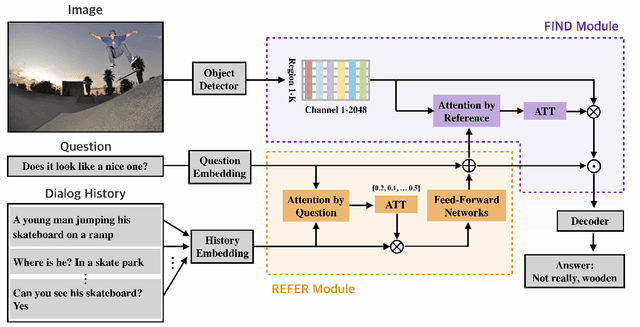
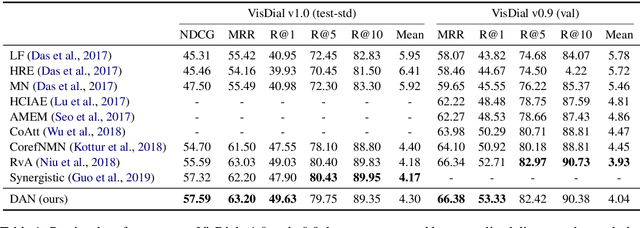
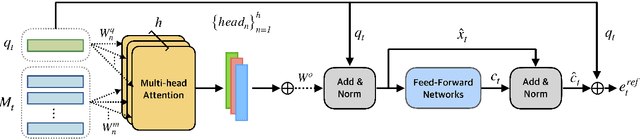
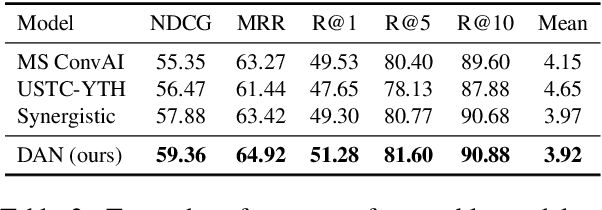
Visual dialog (VisDial) is a task which requires an AI agent to answer a series of questions grounded in an image. Unlike in visual question answering (VQA), the series of questions should be able to capture a temporal context from a dialog history and exploit visually-grounded information. A problem called visual reference resolution involves these challenges, requiring the agent to resolve ambiguous references in a given question and find the references in a given image. In this paper, we propose Dual Attention Networks (DAN) for visual reference resolution. DAN consists of two kinds of attention networks, REFER and FIND. Specifically, REFER module learns latent relationships between a given question and a dialog history by employing a self-attention mechanism. FIND module takes image features and reference-aware representations (i.e., the output of REFER module) as input, and performs visual grounding via bottom-up attention mechanism. We qualitatively and quantitatively evaluate our model on VisDial v1.0 and v0.9 datasets, showing that DAN outperforms the previous state-of-the-art model by a significant margin (2.0% on NDCG).