 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLee and Seung (2000)'s Algorithms for Non-negative Matrix Factorization: A Supplementary Proof Guide
Jan 20, 2025Lee and Seung (2000) introduced numerical solutions for non-negative matrix factorization (NMF) using iterative multiplicative update algorithms. These algorithms have been actively utilized as dimensionality reduction tools for high-dimensional non-negative data and learning algorithms for artificial neural networks. Despite a considerable amount of literature on the applications of the NMF algorithms, detailed explanations about their formulation and derivation are lacking. This report provides supplementary details to help understand the formulation and derivation of the proofs as used in the original paper.
Multi-speaker Emotional Text-to-speech Synthesizer
Dec 07, 2021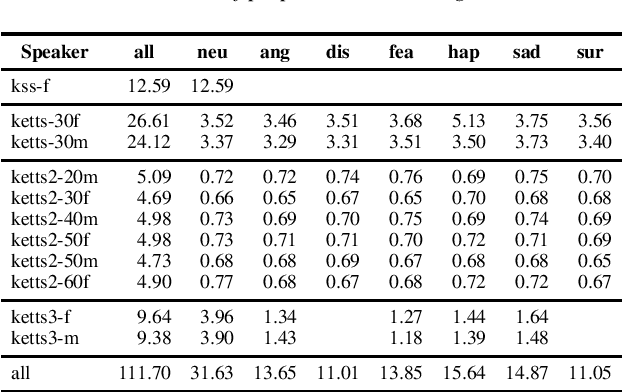
We present a methodology to train our multi-speaker emotional text-to-speech synthesizer that can express speech for 10 speakers' 7 different emotions. All silences from audio samples are removed prior to learning. This results in fast learning by our model. Curriculum learning is applied to train our model efficiently. Our model is first trained with a large single-speaker neutral dataset, and then trained with neutral speech from all speakers. Finally, our model is trained using datasets of emotional speech from all speakers. In each stage, training samples of each speaker-emotion pair have equal probability to appear in mini-batches. Through this procedure, our model can synthesize speech for all targeted speakers and emotions. Our synthesized audio sets are available on our web page.
* 2 pages; Published in the Proceedings of Interspeech 2021; Presented in Show and Tell; For the published paper, see https://www.isca-speech.org/archive/interspeech_2021/cho21_interspeech.html
Emotional Voice Conversion using Multitask Learning with Text-to-speech
Nov 27, 2019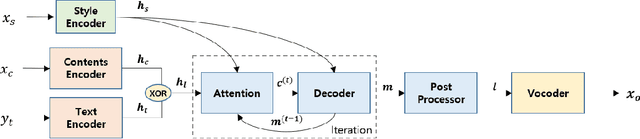

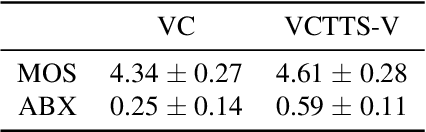
Voice conversion (VC) is a task to transform a person's voice to different style while conserving linguistic contents. Previous state-of-the-art on VC is based on sequence-to-sequence (seq2seq) model, which could mislead linguistic information. There was an attempt to overcome it by using textual supervision, it requires explicit alignment which loses the benefit of using seq2seq model. In this paper, a voice converter using multitask learning with text-to-speech (TTS) is presented. The embedding space of seq2seq-based TTS has abundant information on the text. The role of the decoder of TTS is to convert embedding space to speech, which is same to VC. In the proposed model, the whole network is trained to minimize loss of VC and TTS. VC is expected to capture more linguistic information and to preserve training stability by multitask learning. Experiments of VC were performed on a male Korean emotional text-speech dataset, and it is shown that multitask learning is helpful to keep linguistic contents in VC.
Simulating Problem Difficulty in Arithmetic Cognition Through Dynamic Connectionist Models
May 30, 2019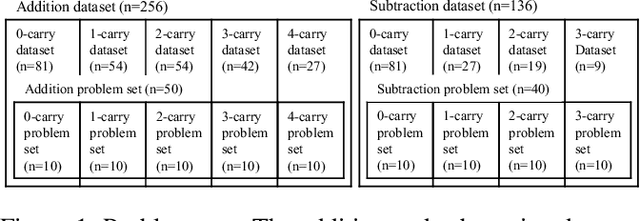
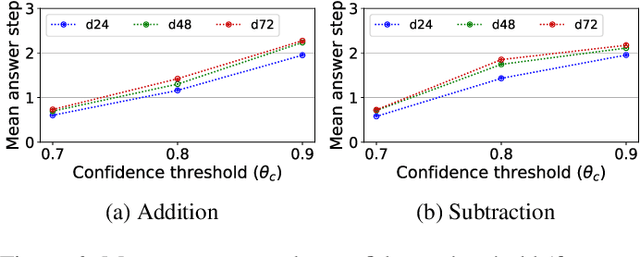
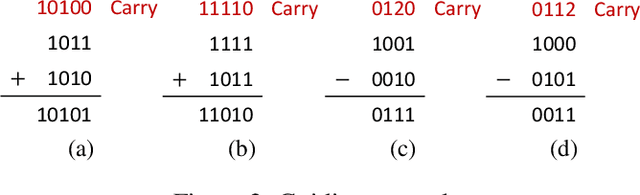

The present study aims to investigate similarities between how humans and connectionist models experience difficulty in arithmetic problems. Problem difficulty was operationalized by the number of carries involved in solving a given problem. Problem difficulty was measured in humans by response time, and in models by computational steps. The present study found that both humans and connectionist models experience difficulty similarly when solving binary addition and subtraction. Specifically, both agents found difficulty to be strictly increasing with respect to the number of carries. Another notable similarity is that problem difficulty increases more steeply in subtraction than in addition, for both humans and connectionist models. Further investigation on two model hyperparameters --- confidence threshold and hidden dimension --- shows higher confidence thresholds cause the model to take more computational steps to arrive at the correct answer. Likewise, larger hidden dimensions cause the model to take more computational steps to correctly answer arithmetic problems; however, this effect by hidden dimensions is negligible.