 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-speaker Emotional Text-to-speech Synthesizer
Paper and Code
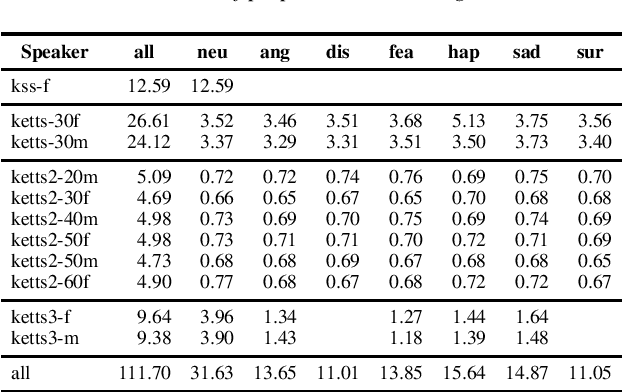
We present a methodology to train our multi-speaker emotional text-to-speech synthesizer that can express speech for 10 speakers' 7 different emotions. All silences from audio samples are removed prior to learning. This results in fast learning by our model. Curriculum learning is applied to train our model efficiently. Our model is first trained with a large single-speaker neutral dataset, and then trained with neutral speech from all speakers. Finally, our model is trained using datasets of emotional speech from all speakers. In each stage, training samples of each speaker-emotion pair have equal probability to appear in mini-batches. Through this procedure, our model can synthesize speech for all targeted speakers and emotions. Our synthesized audio sets are available on our web page.