 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Weak Visual-Textual Alignment for Video Moment Retrieval
Jun 05, 2023
Video moment retrieval (VMR) aims to identify the specific moment in an untrimmed video for a given natural language query. However, this task is prone to suffer the weak visual-textual alignment problem from query ambiguity, potentially limiting further performance gains and generalization capability. Due to the complex multimodal interactions in videos, a query may not fully cover the relevant details of the corresponding moment, and the moment may contain misaligned and irrelevant frames. To tackle this problem, we propose a straightforward yet effective model, called Background-aware Moment DEtection TRansformer (BM-DETR). Given a target query and its moment, BM-DETR also takes negative queries corresponding to different moments. Specifically, our model learns to predict the target moment from the joint probability of the given query and the complement of negative queries for each candidate frame. In this way, it leverages the surrounding background to consider relative importance, improving moment sensitivity. Extensive experiments on Charades-STA and QVHighlights demonstrate the effectiveness of our model. Moreover, we show that BM-DETR can perform robustly in three challenging VMR scenarios, such as several out-of-distribution test cases, demonstrating superior generalization ability.
Learning to Write with Coherence From Negative Examples
Sep 22, 2022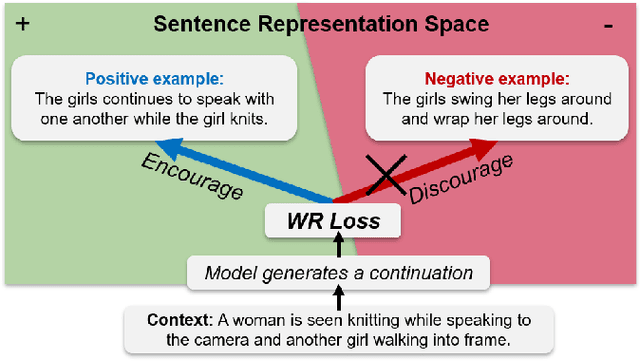
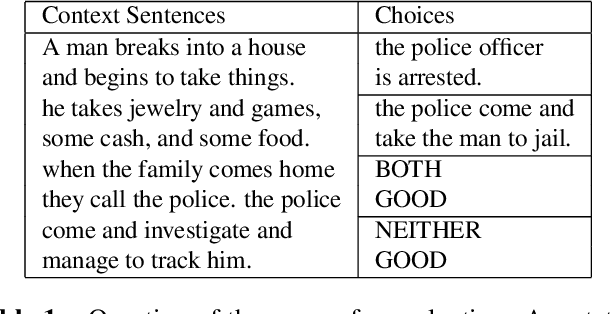
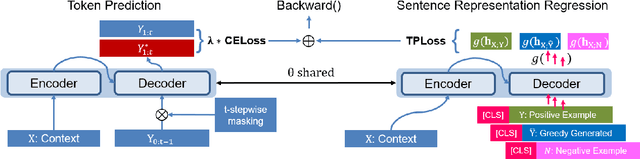
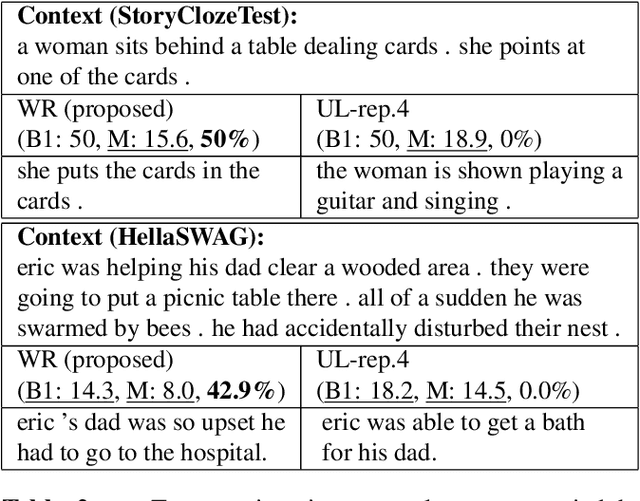
Coherence is one of the critical factors that determine the quality of writing. We propose writing relevance (WR) training method for neural encoder-decoder natural language generation (NLG) models which improves coherence of the continuation by leveraging negative examples. WR loss regresses the vector representation of the context and generated sentence toward positive continuation by contrasting it with the negatives. We compare our approach with Unlikelihood (UL) training in a text continuation task on commonsense natural language inference (NLI) corpora to show which method better models the coherence by avoiding unlikely continuations. The preference of our approach in human evaluation shows the efficacy of our method in improving coherence.
Mounting Video Metadata on Transformer-based Language Model for Open-ended Video Question Answering
Aug 11, 2021

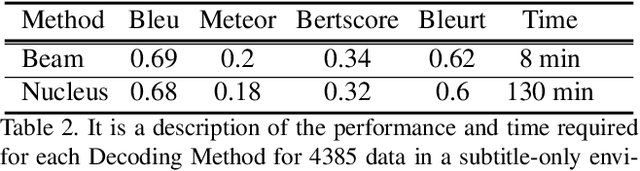
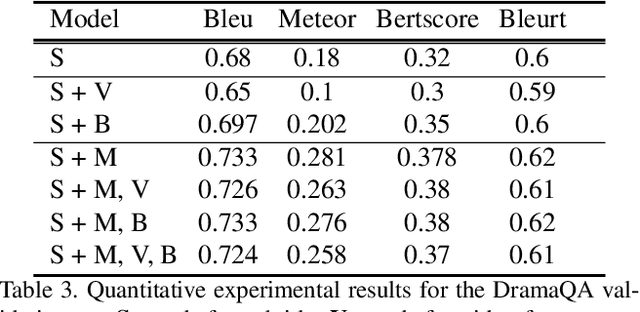
Video question answering has recently received a lot of attention from multimodal video researchers. Most video question answering datasets are usually in the form of multiple-choice. But, the model for the multiple-choice task does not infer the answer. Rather it compares the answer candidates for picking the correct answer. Furthermore, it makes it difficult to extend to other tasks. In this paper, we challenge the existing multiple-choice video question answering by changing it to open-ended video question answering. To tackle open-ended question answering, we use the pretrained GPT2 model. The model is fine-tuned with video inputs and subtitles. An ablation study is performed by changing the existing DramaQA dataset to an open-ended question answering, and it shows that performance can be improved using video metadata.
DramaQA: Character-Centered Video Story Understanding with Hierarchical QA
May 07, 2020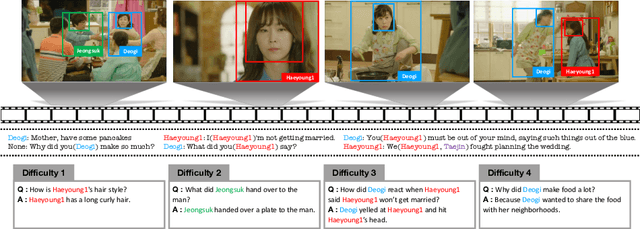
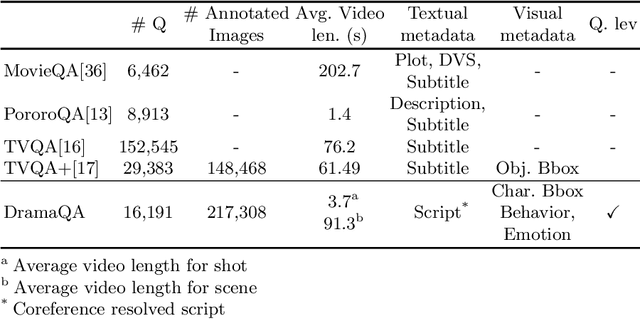
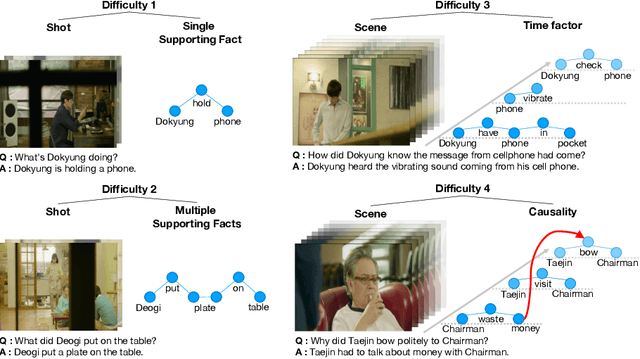
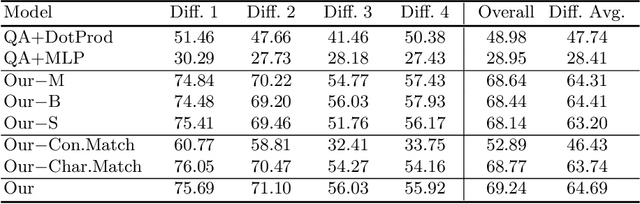
Despite recent progress on computer vision and natural language processing, developing video understanding intelligence is still hard to achieve due to the intrinsic difficulty of story in video. Moreover, there is not a theoretical metric for evaluating the degree of video understanding. In this paper, we propose a novel video question answering (Video QA) task, DramaQA, for a comprehensive understanding of the video story. The DramaQA focused on two perspectives: 1) hierarchical QAs as an evaluation metric based on the cognitive developmental stages of human intelligence. 2) character-centered video annotations to model local coherence of the story. Our dataset is built upon the TV drama "Another Miss Oh" and it contains 16,191 QA pairs from 23,928 various length video clips, with each QA pair belonging to one of four difficulty levels. We provide 217,308 annotated images with rich character-centered annotations, including visual bounding boxes, behaviors, and emotions of main characters, and coreference resolved scripts. Additionally, we provide analyses of the dataset as well as Dual Matching Multistream model which effectively learns character-centered representations of video to answer questions about the video. We are planning to release our dataset and model publicly for research purposes and expect that our work will provide a new perspective on video story understanding research.