 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend What You Need: Motion-Appearance Synergistic Networks for Video Question Answering
Jun 19, 2021
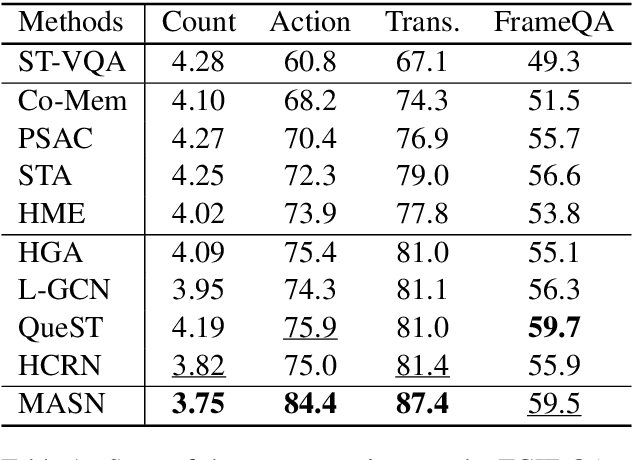
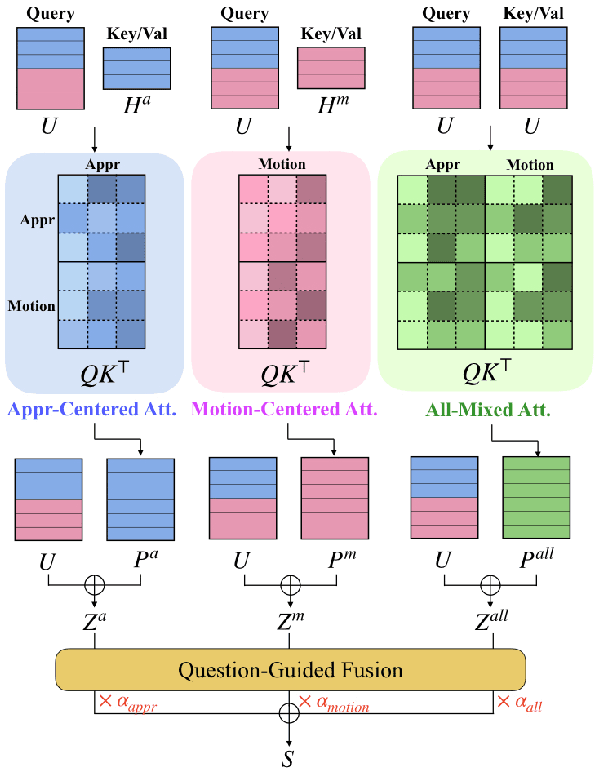
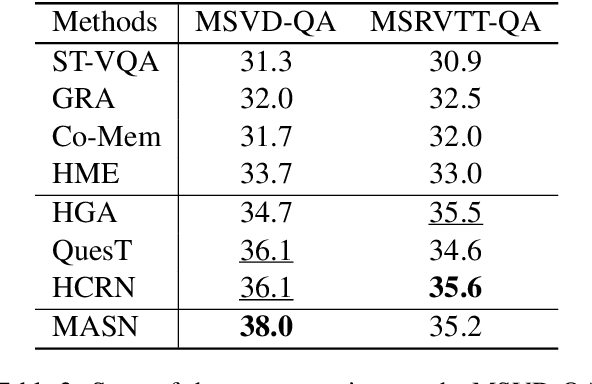
Video Question Answering is a task which requires an AI agent to answer questions grounded in video. This task entails three key challenges: (1) understand the intention of various questions, (2) capturing various elements of the input video (e.g., object, action, causality), and (3) cross-modal grounding between language and vision information. We propose Motion-Appearance Synergistic Networks (MASN), which embed two cross-modal features grounded on motion and appearance information and selectively utilize them depending on the question's intentions. MASN consists of a motion module, an appearance module, and a motion-appearance fusion module. The motion module computes the action-oriented cross-modal joint representations, while the appearance module focuses on the appearance aspect of the input video. Finally, the motion-appearance fusion module takes each output of the motion module and the appearance module as input, and performs question-guided fusion. As a result, MASN achieves new state-of-the-art performance on the TGIF-QA and MSVD-QA datasets. We also conduct qualitative analysis by visualizing the inference results of MASN. The code is available at https://github.com/ahjeongseo/MASN-pytorch.
DramaQA: Character-Centered Video Story Understanding with Hierarchical QA
May 07, 2020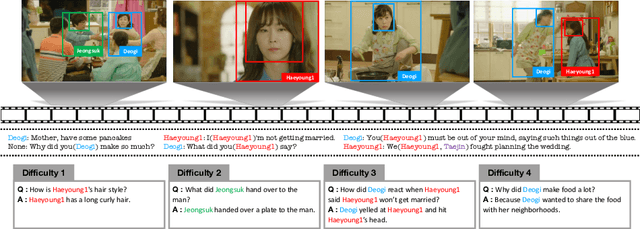
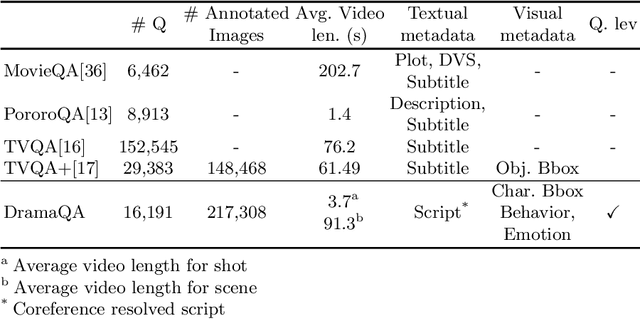
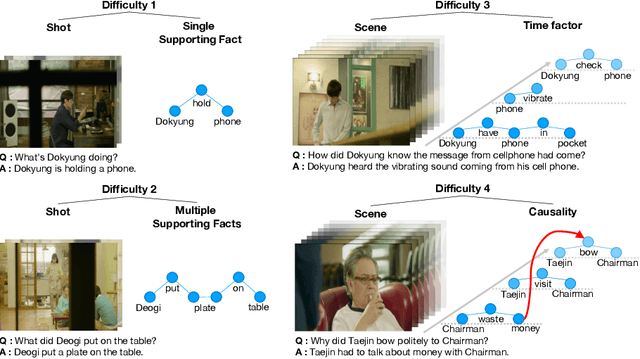
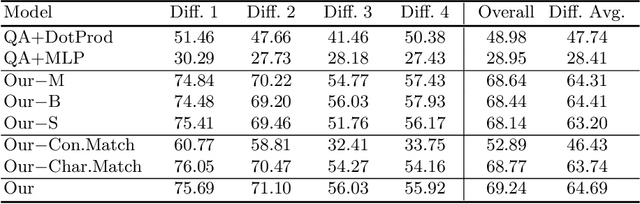
Despite recent progress on computer vision and natural language processing, developing video understanding intelligence is still hard to achieve due to the intrinsic difficulty of story in video. Moreover, there is not a theoretical metric for evaluating the degree of video understanding. In this paper, we propose a novel video question answering (Video QA) task, DramaQA, for a comprehensive understanding of the video story. The DramaQA focused on two perspectives: 1) hierarchical QAs as an evaluation metric based on the cognitive developmental stages of human intelligence. 2) character-centered video annotations to model local coherence of the story. Our dataset is built upon the TV drama "Another Miss Oh" and it contains 16,191 QA pairs from 23,928 various length video clips, with each QA pair belonging to one of four difficulty levels. We provide 217,308 annotated images with rich character-centered annotations, including visual bounding boxes, behaviors, and emotions of main characters, and coreference resolved scripts. Additionally, we provide analyses of the dataset as well as Dual Matching Multistream model which effectively learns character-centered representations of video to answer questions about the video. We are planning to release our dataset and model publicly for research purposes and expect that our work will provide a new perspective on video story understanding research.