 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVarco Arena: A Tournament Approach to Reference-Free Benchmarking Large Language Models
Nov 02, 2024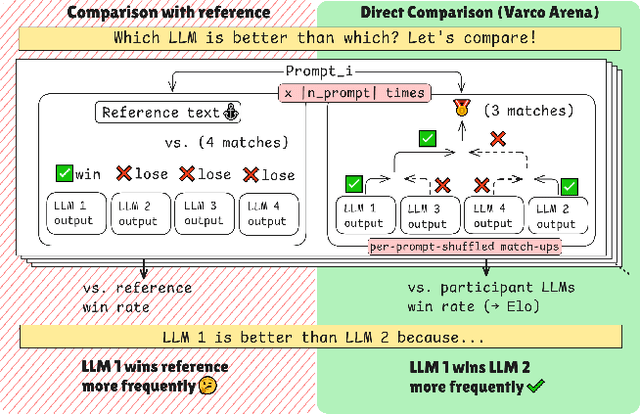

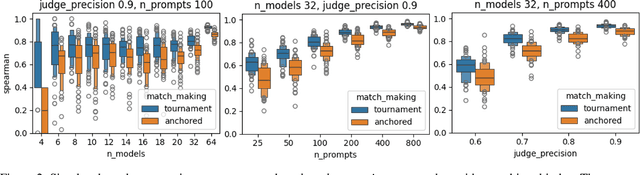

The rapid advancement of Large Language Models (LLMs) necessitates robust evaluation methodologies. Current benchmarking approaches often rely on comparing model outputs against predefined prompts and reference outputs. Relying on predefined reference outputs hinders flexible adaptation of benchmarks to the rapidly evolving capabilities of LLMs. This limitation necessitates periodic efforts to prepare new benchmarks. To keep pace with rapidly evolving LLM capabilities, we propose a more flexible benchmarking approach. Our method, \textit{\textbf{Varco Arena}}, provides reference-free benchmarking of LLMs in tournament style. \textit{\textbf{Varco Arena}} directly compares LLM outputs across a diverse set of prompts, determining model rankings through a single-elimination tournament structure. This direct pairwise comparison offers two key advantages: (1) Direct comparison, unmediated by reference text, more effectively orders competing LLMs, resulting in more reliable rankings, and (2) reference-free approach to benchmarking adds flexibility in updating benchmark prompts by eliminating the need for quality references. Our empirical results, supported by simulation experiments, demonstrate that the \textit{\textbf{Varco Arena}} tournament approach aligns better with the current Elo model for benchmarking LLMs. The alignment is measured in terms of Spearman correlation, showing improvement over current practice of benchmarking that use reference outputs as comparison \textit{anchor}s.
Align-to-Distill: Trainable Attention Alignment for Knowledge Distillation in Neural Machine Translation
Mar 03, 2024The advent of scalable deep models and large datasets has improved the performance of Neural Machine Translation. Knowledge Distillation (KD) enhances efficiency by transferring knowledge from a teacher model to a more compact student model. However, KD approaches to Transformer architecture often rely on heuristics, particularly when deciding which teacher layers to distill from. In this paper, we introduce the 'Align-to-Distill' (A2D) strategy, designed to address the feature mapping problem by adaptively aligning student attention heads with their teacher counterparts during training. The Attention Alignment Module in A2D performs a dense head-by-head comparison between student and teacher attention heads across layers, turning the combinatorial mapping heuristics into a learning problem. Our experiments show the efficacy of A2D, demonstrating gains of up to +3.61 and +0.63 BLEU points for WMT-2022 De->Dsb and WMT-2014 En->De, respectively, compared to Transformer baselines.
Adaptive Attention Link-based Regularization for Vision Transformers
Nov 25, 2022Although transformer networks are recently employed in various vision tasks with outperforming performance, extensive training data and a lengthy training time are required to train a model to disregard an inductive bias. Using trainable links between the channel-wise spatial attention of a pre-trained Convolutional Neural Network (CNN) and the attention head of Vision Transformers (ViT), we present a regularization technique to improve the training efficiency of ViT. The trainable links are referred to as the attention augmentation module, which is trained simultaneously with ViT, boosting the training of ViT and allowing it to avoid the overfitting issue caused by a lack of data. From the trained attention augmentation module, we can extract the relevant relationship between each CNN activation map and each ViT attention head, and based on this, we also propose an advanced attention augmentation module. Consequently, even with a small amount of data, the suggested method considerably improves the performance of ViT while achieving faster convergence during training.