 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVarco Arena: A Tournament Approach to Reference-Free Benchmarking Large Language Models
Nov 02, 2024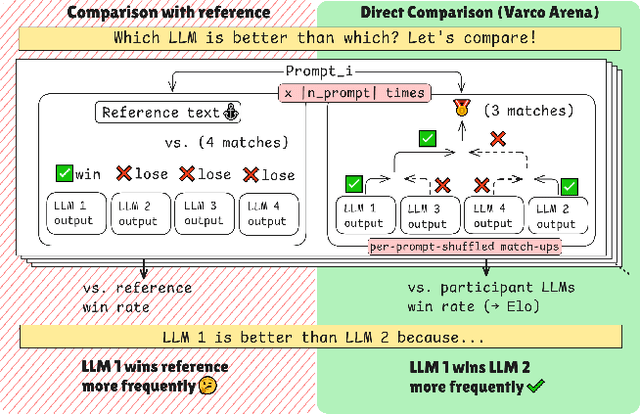

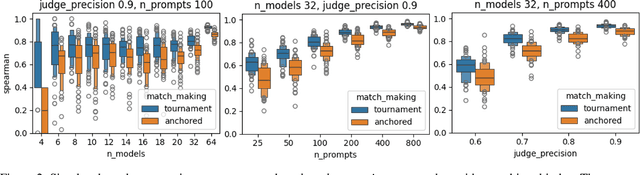

The rapid advancement of Large Language Models (LLMs) necessitates robust evaluation methodologies. Current benchmarking approaches often rely on comparing model outputs against predefined prompts and reference outputs. Relying on predefined reference outputs hinders flexible adaptation of benchmarks to the rapidly evolving capabilities of LLMs. This limitation necessitates periodic efforts to prepare new benchmarks. To keep pace with rapidly evolving LLM capabilities, we propose a more flexible benchmarking approach. Our method, \textit{\textbf{Varco Arena}}, provides reference-free benchmarking of LLMs in tournament style. \textit{\textbf{Varco Arena}} directly compares LLM outputs across a diverse set of prompts, determining model rankings through a single-elimination tournament structure. This direct pairwise comparison offers two key advantages: (1) Direct comparison, unmediated by reference text, more effectively orders competing LLMs, resulting in more reliable rankings, and (2) reference-free approach to benchmarking adds flexibility in updating benchmark prompts by eliminating the need for quality references. Our empirical results, supported by simulation experiments, demonstrate that the \textit{\textbf{Varco Arena}} tournament approach aligns better with the current Elo model for benchmarking LLMs. The alignment is measured in terms of Spearman correlation, showing improvement over current practice of benchmarking that use reference outputs as comparison \textit{anchor}s.
Modulated Intervention Preference Optimization (MIPO): Keey the Easy, Refine the Difficult
Sep 26, 2024Preference optimization methods typically begin training with a well-trained SFT model as a reference model. In RLHF and DPO, a regularization term is used during the preference optimization process to prevent the policy model from deviating too far from the reference model's distribution, thereby avoiding the generation of anomalous responses. When the reference model is already well-aligned with the given data or only requires slight adjustments, this approach can produce a well-aligned model. However, if the reference model is not aligned with the given data and requires significant deviation from its current state, a regularization term may actually hinder the model alignment. In this study, we propose \textbf{Modulated Intervention Preference Optimization (MIPO)} to address this issue. MIPO modulates the degree of intervention from the reference model based on how well the given data is aligned with it. If the data is well-aligned, the intervention is increased to prevent the policy model from diverging significantly from reference model. Conversely, if the alignment is poor, the interference is reduced to facilitate more extensive training. We compare the performance of MIPO and DPO using Mistral-7B and Llama3-8B in Alpaca Eval 2.0 and MT-Bench. The experimental results demonstrate that MIPO consistently outperforms DPO across various evaluation scenarios.