 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTs of a feather do not generalize together: Large variability in generalization across models with similar test set performance
Paper and Code

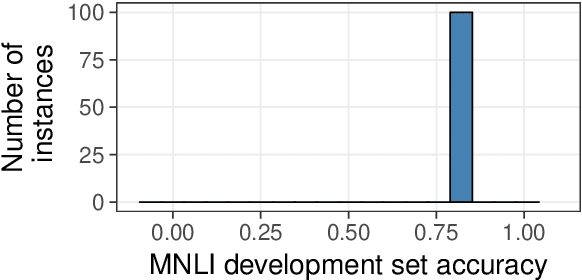
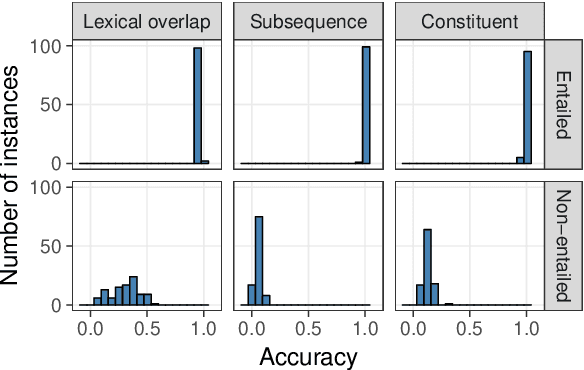
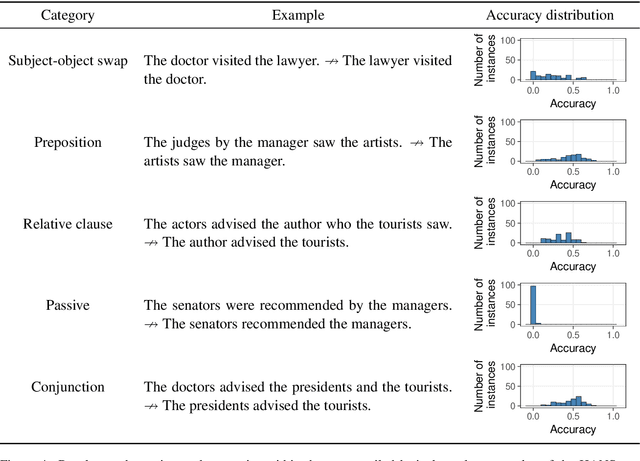
If the same neural architecture is trained multiple times on the same dataset, will it make similar linguistic generalizations across runs? To study this question, we fine-tuned 100 instances of BERT on the Multi-genre Natural Language Inference (MNLI) dataset and evaluated them on the HANS dataset, which measures syntactic generalization in natural language inference. On the MNLI development set, the behavior of all instances was remarkably consistent, with accuracy ranging between 83.6% and 84.8%. In stark contrast, the same models varied widely in their generalization performance. For example, on the simple case of subject-object swap (e.g., knowing that "the doctor visited the lawyer" does not entail "the lawyer visited the doctor"), accuracy ranged from 0.00% to 66.2%. Such variation likely arises from the presence of many local minima that are equally attractive to a low-bias learner such as a neural network; decreasing the variability may therefore require models with stronger inductive biases.