 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring and Reducing Gendered Correlations in Pre-trained Models
Paper and Code
Oct 12, 2020
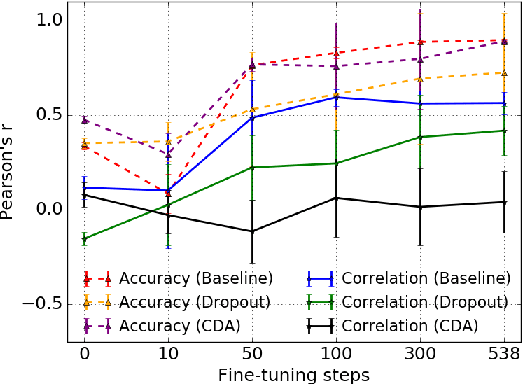
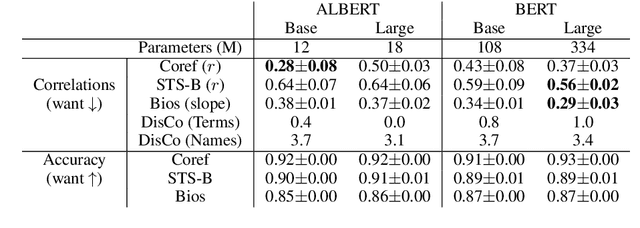
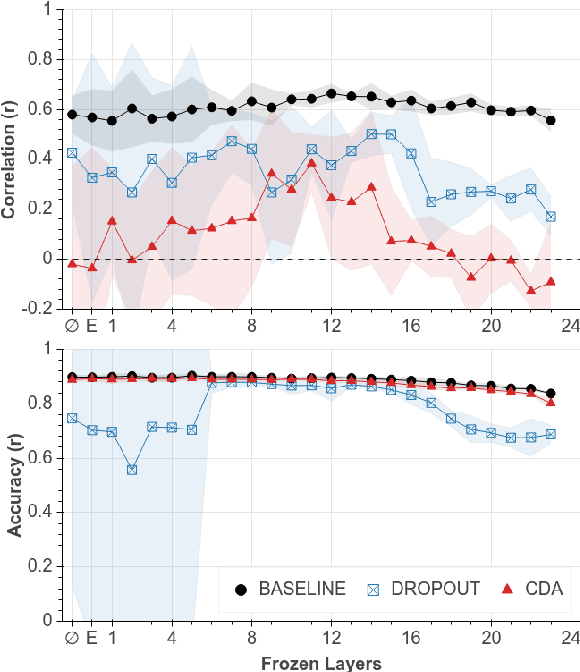
Pre-trained models have revolutionized natural language understanding. However, researchers have found they can encode artifacts undesired in many applications, such as professions correlating with one gender more than another. We explore such gendered correlations as a case study for how to address unintended correlations in pre-trained models. We define metrics and reveal that it is possible for models with similar accuracy to encode correlations at very different rates. We show how measured correlations can be reduced with general-purpose techniques, and highlight the trade offs different strategies have. With these results, we make recommendations for training robust models: (1) carefully evaluate unintended correlations, (2) be mindful of seemingly innocuous configuration differences, and (3) focus on general mitigations.