 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributed Text Generation via Post-hoc Research and Revision
Paper and Code
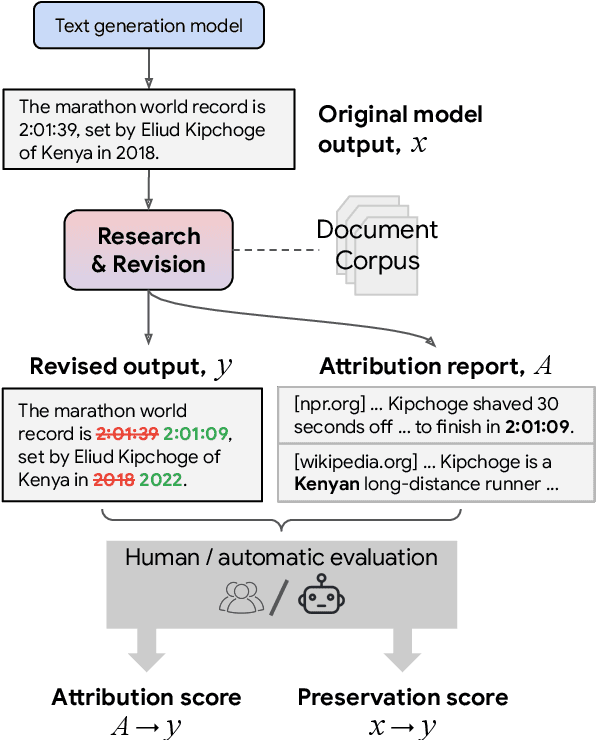
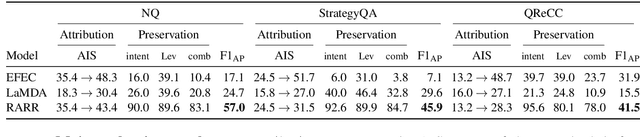
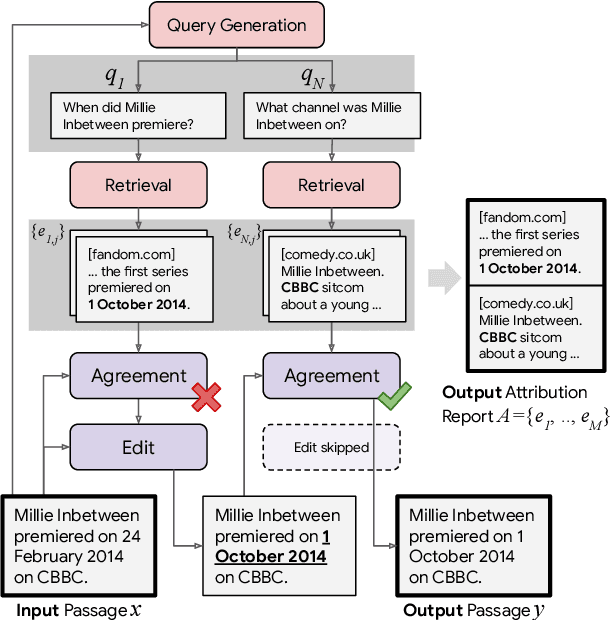
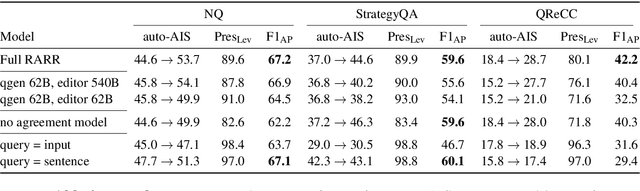
Language models (LMs) now excel at many tasks such as few-shot learning, question answering, reasoning, and dialog. However, they sometimes generate unsupported or misleading content. A user cannot easily determine whether their outputs are trustworthy or not, because most LMs do not have any built-in mechanism for attribution to external evidence. To enable attribution while still preserving all the powerful advantages of recent generation models, we propose RARR (Retrofit Attribution using Research and Revision), a system that 1) automatically finds attribution for the output of any text generation model and 2) post-edits the output to fix unsupported content while preserving the original output as much as possible. When applied to the output of several state-of-the-art LMs on a diverse set of generation tasks, we find that RARR significantly improves attribution while otherwise preserving the original input to a much greater degree than previously explored edit models. Furthermore, the implementation of RARR requires only a handful of training examples, a large language model, and standard web search.