 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePURR: Efficiently Editing Language Model Hallucinations by Denoising Language Model Corruptions
May 24, 2023

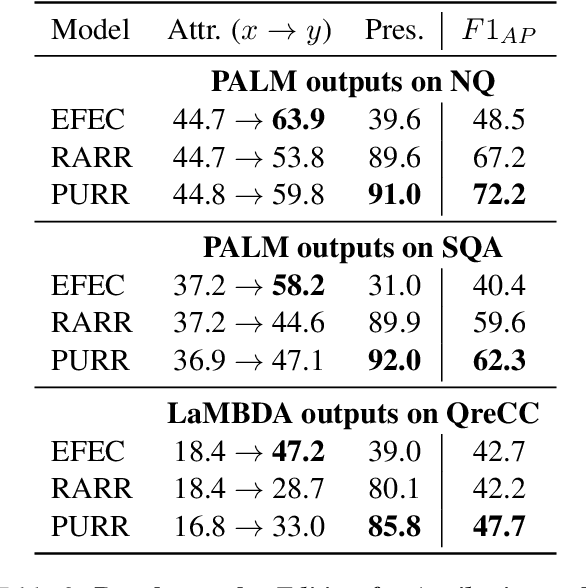

The remarkable capabilities of large language models have been accompanied by a persistent drawback: the generation of false and unsubstantiated claims commonly known as "hallucinations". To combat this issue, recent research has introduced approaches that involve editing and attributing the outputs of language models, particularly through prompt-based editing. However, the inference cost and speed of using large language models for editing currently bottleneck prompt-based methods. These bottlenecks motivate the training of compact editors, which is challenging due to the scarcity of training data for this purpose. To overcome these challenges, we exploit the power of large language models to introduce corruptions (i.e., noise) into text and subsequently fine-tune compact editors to denoise the corruptions by incorporating relevant evidence. Our methodology is entirely unsupervised and provides us with faux hallucinations for training in any domain. Our Petite Unsupervised Research and Revision model, PURR, not only improves attribution over existing editing methods based on fine-tuning and prompting, but also achieves faster execution times by orders of magnitude.
Attributed Text Generation via Post-hoc Research and Revision
Oct 17, 2022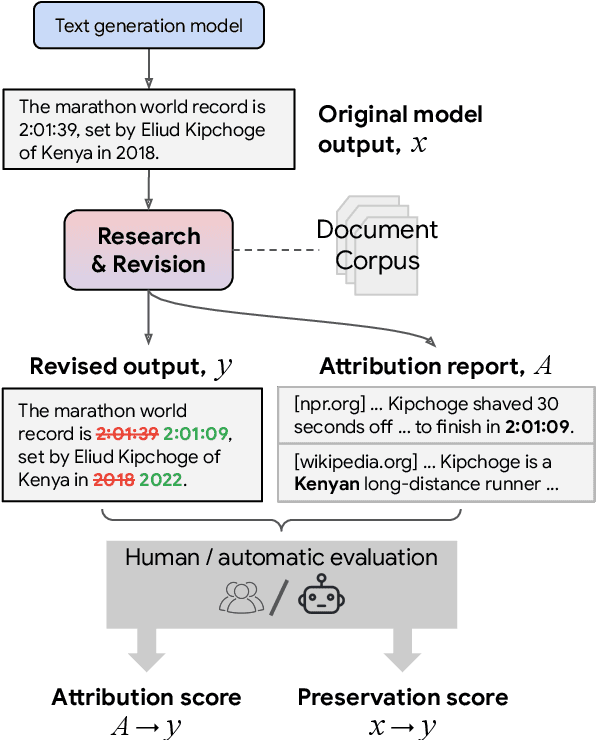
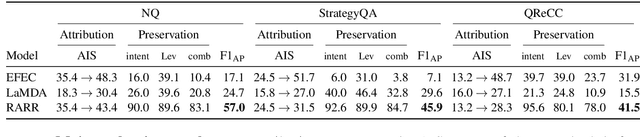
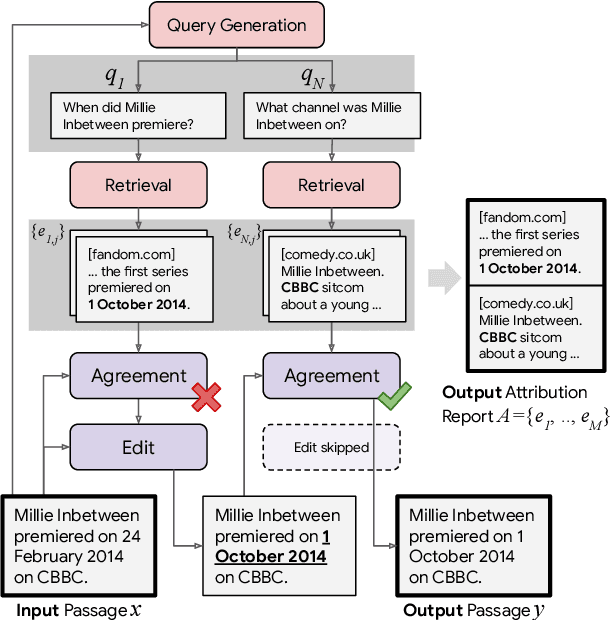
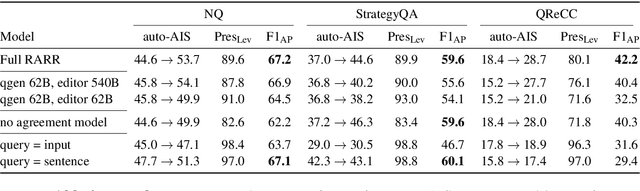
Language models (LMs) now excel at many tasks such as few-shot learning, question answering, reasoning, and dialog. However, they sometimes generate unsupported or misleading content. A user cannot easily determine whether their outputs are trustworthy or not, because most LMs do not have any built-in mechanism for attribution to external evidence. To enable attribution while still preserving all the powerful advantages of recent generation models, we propose RARR (Retrofit Attribution using Research and Revision), a system that 1) automatically finds attribution for the output of any text generation model and 2) post-edits the output to fix unsupported content while preserving the original output as much as possible. When applied to the output of several state-of-the-art LMs on a diverse set of generation tasks, we find that RARR significantly improves attribution while otherwise preserving the original input to a much greater degree than previously explored edit models. Furthermore, the implementation of RARR requires only a handful of training examples, a large language model, and standard web search.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022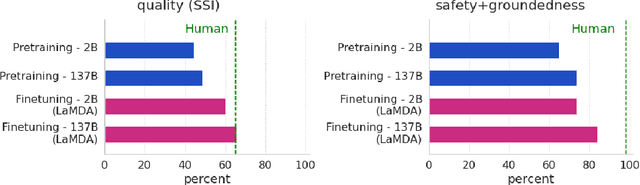
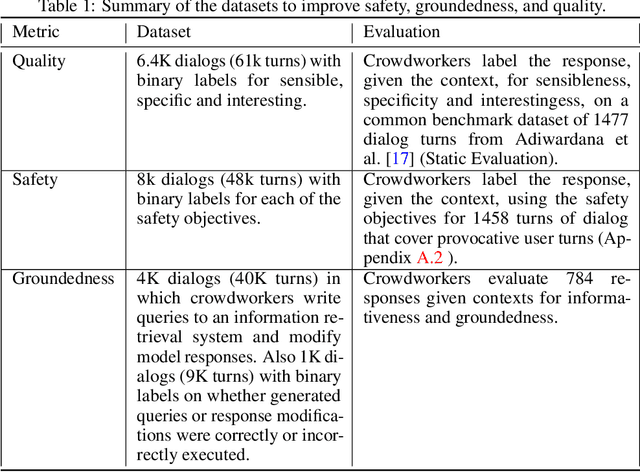
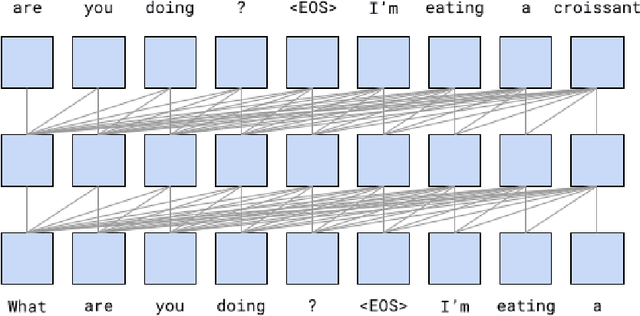

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
Title Generation for Web Tables
Jun 30, 2018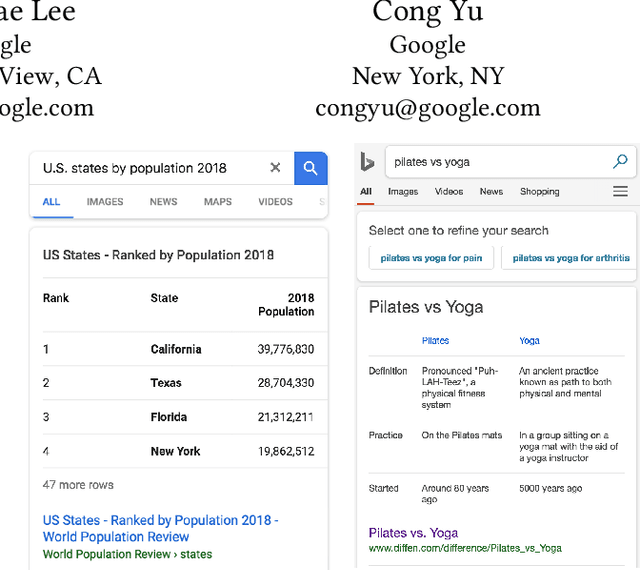


Descriptive titles provide crucial context for interpreting tables that are extracted from web pages and are a key component of table-based web applications. Prior approaches have attempted to produce titles by selecting existing text snippets associated with the table. These approaches, however, are limited by their dependence on suitable titles existing a priori. In our user study, we observe that the relevant information for the title tends to be scattered across the page, and often---more than 80% of time---does not appear verbatim anywhere in the page. We propose instead the application of a sequence-to-sequence neural network model as a more generalizable means of generating high-quality titles. This is accomplished by extracting many text snippets that have potentially relevant information to the table, encoding them into an input sequence, and using both copy and generation mechanisms in the decoder to balance relevance and readability of the generated title. We validate this approach with human evaluation on sample web tables and report that while sequence models with only a copy mechanism or only a generation mechanism are easily outperformed by simple selection-based baselines, the model with both capabilities outperforms them all, approaching the quality of crowdsourced titles while training on fewer than ten thousand examples. To the best of our knowledge, the proposed technique is the first to consider text-generation methods for table titles, and establishes a new state of the art.
Learning to Skim Text
Apr 29, 2017



Recurrent Neural Networks are showing much promise in many sub-areas of natural language processing, ranging from document classification to machine translation to automatic question answering. Despite their promise, many recurrent models have to read the whole text word by word, making it slow to handle long documents. For example, it is difficult to use a recurrent network to read a book and answer questions about it. In this paper, we present an approach of reading text while skipping irrelevant information if needed. The underlying model is a recurrent network that learns how far to jump after reading a few words of the input text. We employ a standard policy gradient method to train the model to make discrete jumping decisions. In our benchmarks on four different tasks, including number prediction, sentiment analysis, news article classification and automatic Q\&A, our proposed model, a modified LSTM with jumping, is up to 6 times faster than the standard sequential LSTM, while maintaining the same or even better accuracy.