 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial advantage estimator for proximal policy optimization
Jan 26, 2023Estimation of value in policy gradient methods is a fundamental problem. Generalized Advantage Estimation (GAE) is an exponentially-weighted estimator of an advantage function similar to $\lambda$-return. It substantially reduces the variance of policy gradient estimates at the expense of bias. In practical applications, a truncated GAE is used due to the incompleteness of the trajectory, which results in a large bias during estimation. To address this challenge, instead of using the entire truncated GAE, we propose to take a part of it when calculating updates, which significantly reduces the bias resulting from the incomplete trajectory. We perform experiments in MuJoCo and $\mu$RTS to investigate the effect of different partial coefficient and sampling lengths. We show that our partial GAE approach yields better empirical results in both environments.
Joint action loss for proximal policy optimization
Jan 26, 2023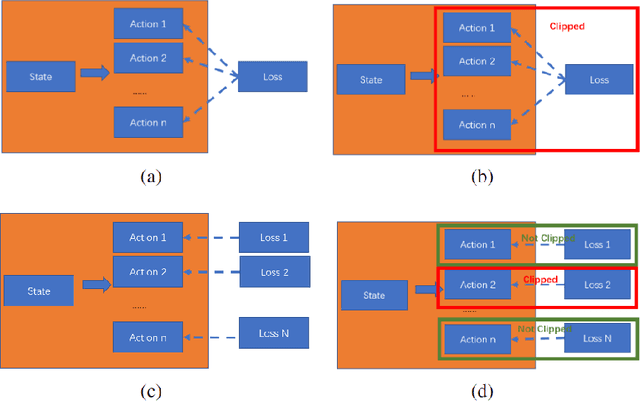

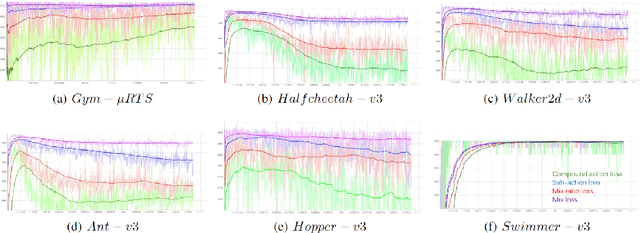
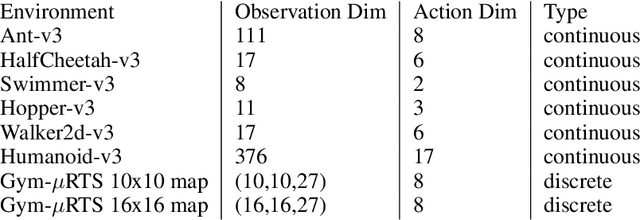
PPO (Proximal Policy Optimization) is a state-of-the-art policy gradient algorithm that has been successfully applied to complex computer games such as Dota 2 and Honor of Kings. In these environments, an agent makes compound actions consisting of multiple sub-actions. PPO uses clipping to restrict policy updates. Although clipping is simple and effective, it is not efficient in its sample use. For compound actions, most PPO implementations consider the joint probability (density) of sub-actions, which means that if the ratio of a sample (state compound-action pair) exceeds the range, the gradient the sample produces is zero. Instead, for each sub-action we calculate the loss separately, which is less prone to clipping during updates thereby making better use of samples. Further, we propose a multi-action mixed loss that combines joint and separate probabilities. We perform experiments in Gym-$\mu$RTS and MuJoCo. Our hybrid model improves performance by more than 50\% in different MuJoCo environments compared to OpenAI's PPO benchmark results. And in Gym-$\mu$RTS, we find the sub-action loss outperforms the standard PPO approach, especially when the clip range is large. Our findings suggest this method can better balance the use-efficiency and quality of samples.