 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Relabelling for Multi-task Transfer using Successor Features
Paper and Code



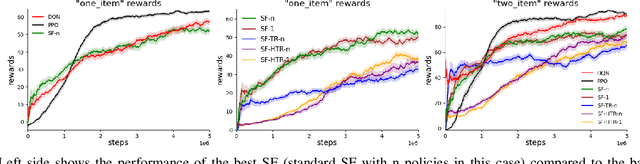
Deep Reinforcement Learning has been very successful recently with various works on complex domains. Most works are concerned with learning a single policy that solves the target task, but is fixed in the sense that if the environment changes the agent is unable to adapt to it. Successor Features (SFs) proposes a mechanism that allows learning policies that are not tied to any particular reward function. In this work we investigate how SFs may be pre-trained without observing any reward in a custom environment that features resource collection, traps and crafting. After pre-training we expose the SF agents to various target tasks and see how well they can transfer to new tasks. Transferring is done without any further training on the SF agents, instead just by providing a task vector. For training the SFs we propose a task relabelling method which greatly improves the agent's performance.