 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Simplicity: Unveiling Bias in Medical Data Augmentation
Jul 31, 2024Synthetic data is becoming increasingly integral in data-scarce fields such as medical imaging, serving as a substitute for real data. However, its inherent statistical characteristics can significantly impact downstream tasks, potentially compromising deployment performance. In this study, we empirically investigate this issue and uncover a critical phenomenon: downstream neural networks often exploit spurious distinctions between real and synthetic data when there is a strong correlation between the data source and the task label. This exploitation manifests as \textit{simplicity bias}, where models overly rely on superficial features rather than genuine task-related complexities. Through principled experiments, we demonstrate that the source of data (real vs.\ synthetic) can introduce spurious correlating factors leading to poor performance during deployment when the correlation is absent. We first demonstrate this vulnerability on a digit classification task, where the model spuriously utilizes the source of data instead of the digit to provide an inference. We provide further evidence of this phenomenon in a medical imaging problem related to cardiac view classification in echocardiograms, particularly distinguishing between 2-chamber and 4-chamber views. Given the increasing role of utilizing synthetic datasets, we hope that our experiments serve as effective guidelines for the utilization of synthetic datasets in model training.
Task-driven Prompt Evolution for Foundation Models
Oct 26, 2023Promptable foundation models, particularly Segment Anything Model (SAM), have emerged as a promising alternative to the traditional task-specific supervised learning for image segmentation. However, many evaluation studies have found that their performance on medical imaging modalities to be underwhelming compared to conventional deep learning methods. In the world of large pre-trained language and vision-language models, learning prompt from downstream tasks has achieved considerable success in improving performance. In this work, we propose a plug-and-play Prompt Optimization Technique for foundation models like SAM (SAMPOT) that utilizes the downstream segmentation task to optimize the human-provided prompt to obtain improved performance. We demonstrate the utility of SAMPOT on lung segmentation in chest X-ray images and obtain an improvement on a significant number of cases ($\sim75\%$) over human-provided initial prompts. We hope this work will lead to further investigations in the nascent field of automatic visual prompt-tuning.
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023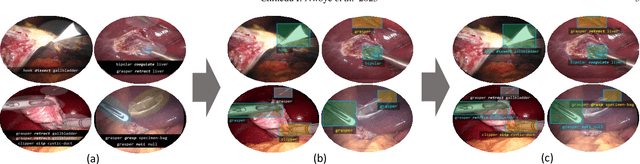
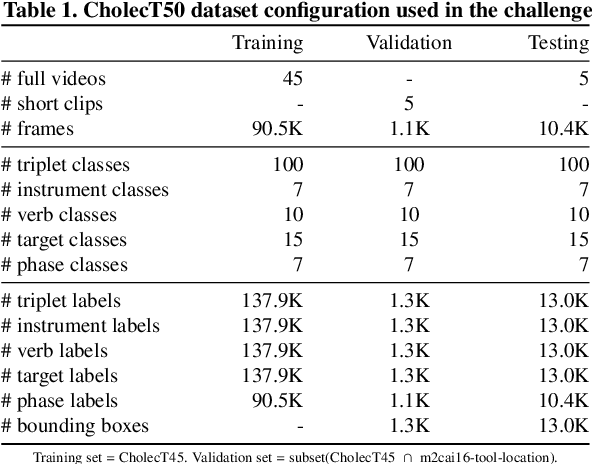
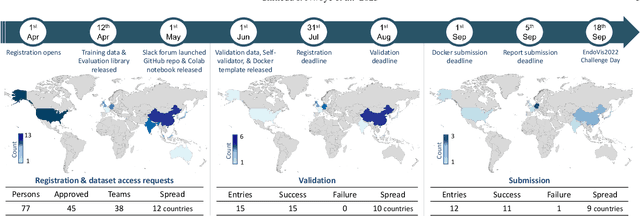
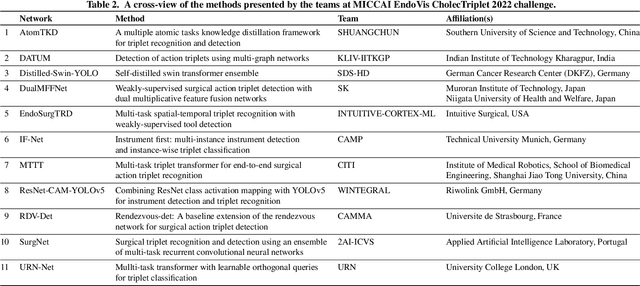
Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022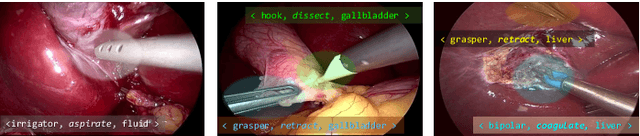

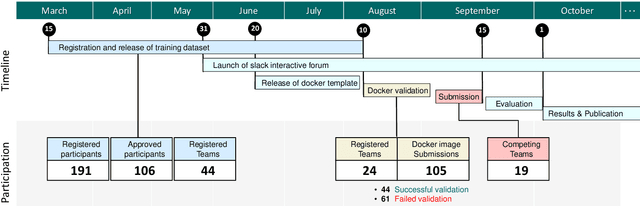
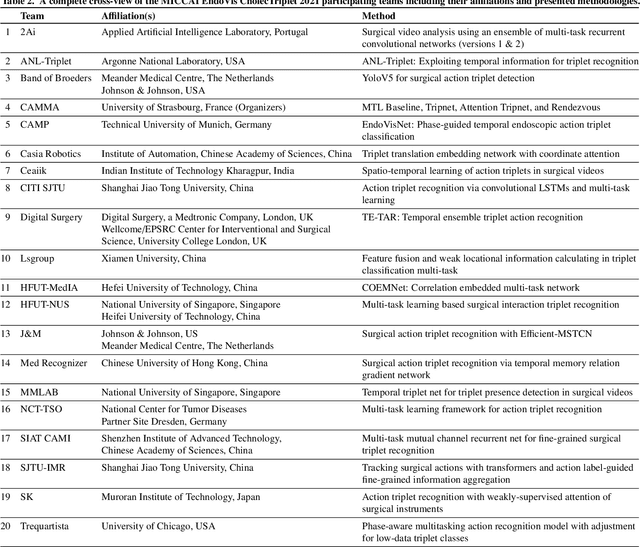
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
Lung Segmentation and Nodule Detection in Computed Tomography Scan using a Convolutional Neural Network Trained Adversarially using Turing Test Loss
Jun 16, 2020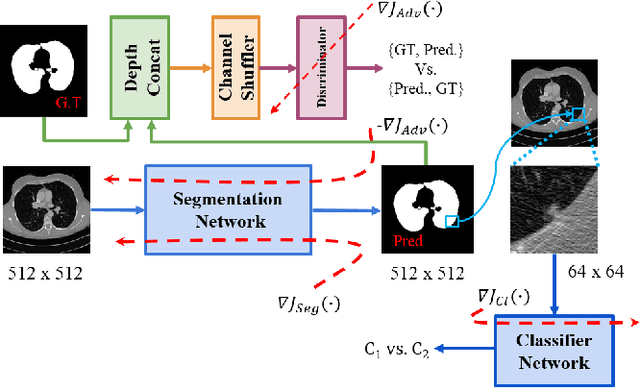
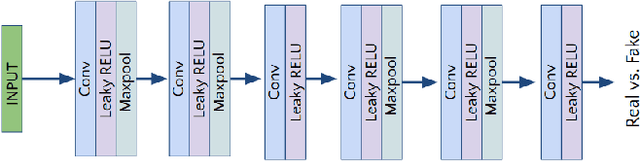
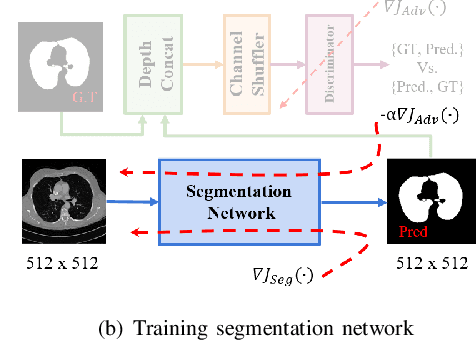
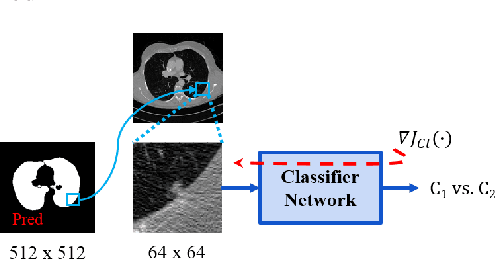
Lung cancer is the most common form of cancer found worldwide with a high mortality rate. Early detection of pulmonary nodules by screening with a low-dose computed tomography (CT) scan is crucial for its effective clinical management. Nodules which are symptomatic of malignancy occupy about 0.0125 - 0.025\% of volume in a CT scan of a patient. Manual screening of all slices is a tedious task and presents a high risk of human errors. To tackle this problem we propose a computationally efficient two stage framework. In the first stage, a convolutional neural network (CNN) trained adversarially using Turing test loss segments the lung region. In the second stage, patches sampled from the segmented region are then classified to detect the presence of nodules. The proposed method is experimentally validated on the LUNA16 challenge dataset with a dice coefficient of $0.984\pm0.0007$ for 10-fold cross-validation.
Identification of Cervical Pathology using Adversarial Neural Networks
Apr 28, 2020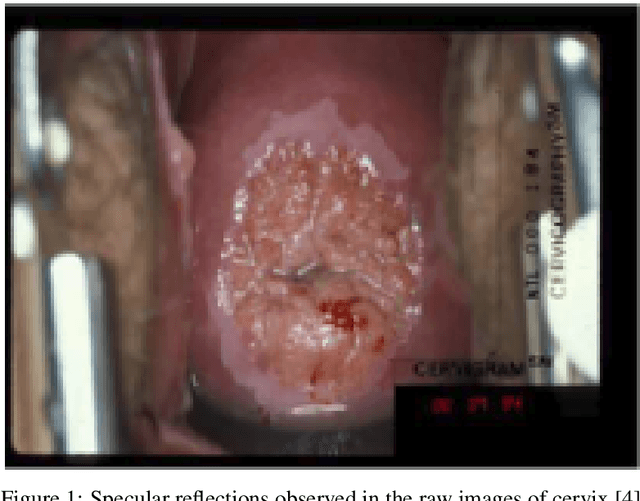
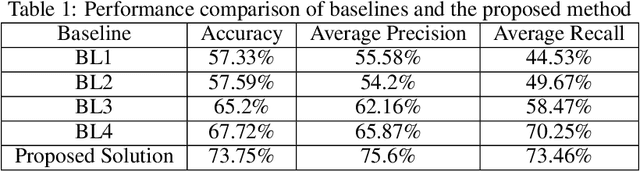
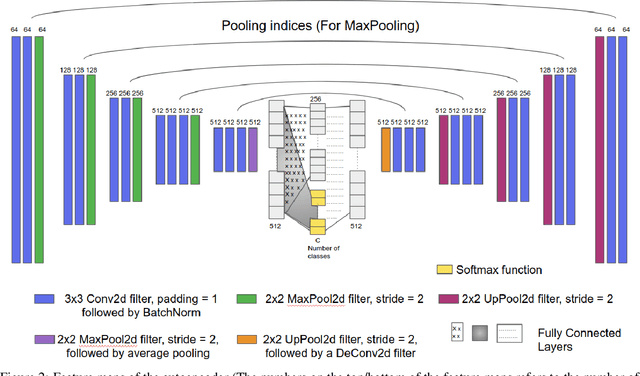
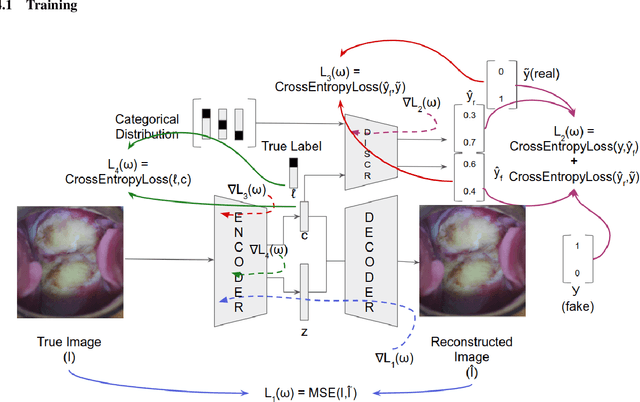
Various screening and diagnostic methods have led to a large reduction of cervical cancer death rates in developed countries. However, cervical cancer is the leading cause of cancer related deaths in women in India and other low and middle income countries (LMICs) especially among the urban poor and slum dwellers. Several sophisticated techniques such as cytology tests, HPV tests etc. have been widely used for screening of cervical cancer. These tests are inherently time consuming. In this paper, we propose a convolutional autoencoder based framework, having an architecture similar to SegNet which is trained in an adversarial fashion for classifying images of the cervix acquired using a colposcope. We validate performance on the Intel-Mobile ODT cervical image classification dataset. The proposed method outperforms the standard technique of fine-tuning convolutional neural networks pre-trained on ImageNet database with an average accuracy of 73.75%.
CHAOS Challenge -- Combined (CT-MR) Healthy Abdominal Organ Segmentation
Jan 17, 2020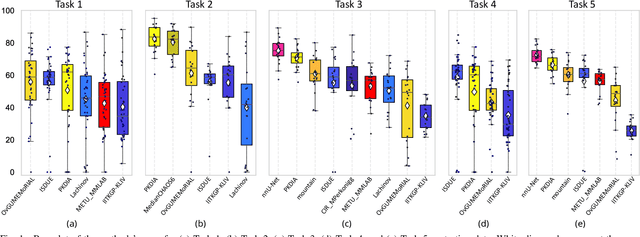
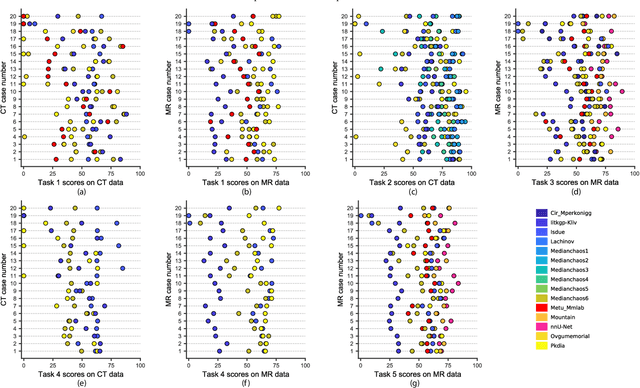
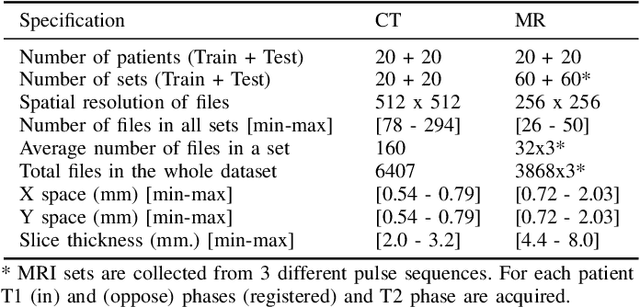
Segmentation of abdominal organs has been a comprehensive, yet unresolved, research field for many years. In the last decade, intensive developments in deep learning (DL) have introduced new state-of-the-art segmentation systems. Despite outperforming the overall accuracy of existing systems, the effects of DL model properties and parameters on the performance is hard to interpret. This makes comparative analysis a necessary tool to achieve explainable studies and systems. Moreover, the performance of DL for emerging learning approaches such as cross-modality and multi-modal tasks have been rarely discussed. In order to expand the knowledge in these topics, CHAOS -- Combined (CT-MR) Healthy Abdominal Organ Segmentation challenge has been organized in the IEEE International Symposium on Biomedical Imaging (ISBI), 2019, in Venice, Italy. Despite a large number of the previous abdomen related challenges, the majority of which are focused on tumor/lesion detection and/or classification with a single modality, CHAOS provides both abdominal CT and MR data from healthy subjects. Five different and complementary tasks have been designed to analyze the capabilities of the current approaches from multiple perspectives. The results are investigated thoroughly, compared with manual annotations and interactive methods. The outcomes are reported in detail to reflect the latest advancements in the field. CHAOS challenge and data will be available online to provide a continuous benchmark resource for segmentation.
Adversarially Trained Convolutional Neural Networks for Semantic Segmentation of Ischaemic Stroke Lesion using Multisequence Magnetic Resonance Imaging
Aug 03, 2019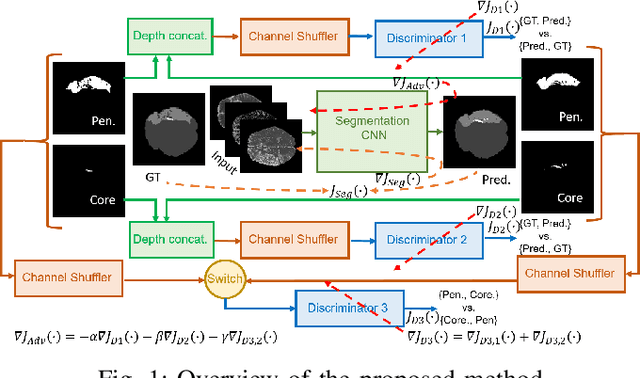
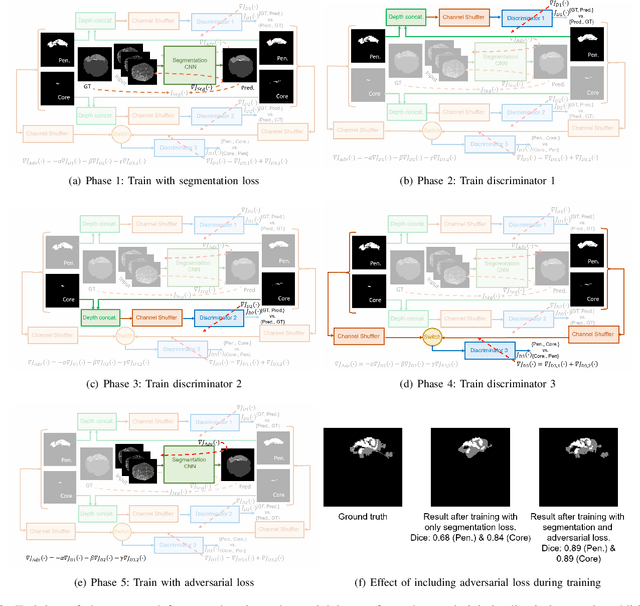


Ischaemic stroke is a medical condition caused by occlusion of blood supply to the brain tissue thus forming a lesion. A lesion is zoned into a core associated with irreversible necrosis typically located at the center of the lesion, while reversible hypoxic changes in the outer regions of the lesion are termed as the penumbra. Early estimation of core and penumbra in ischaemic stroke is crucial for timely intervention with thrombolytic therapy to reverse the damage and restore normalcy. Multisequence magnetic resonance imaging (MRI) is commonly employed for clinical diagnosis. However, a sequence singly has not been found to be sufficiently able to differentiate between core and penumbra, while a combination of sequences is required to determine the extent of the damage. The challenge, however, is that with an increase in the number of sequences, it cognitively taxes the clinician to discover symptomatic biomarkers in these images. In this paper, we present a data-driven fully automated method for estimation of core and penumbra in ischaemic lesions using diffusion-weighted imaging (DWI) and perfusion-weighted imaging (PWI) sequence maps of MRI. The method employs recent developments in convolutional neural networks (CNN) for semantic segmentation in medical images. In the absence of availability of a large amount of labeled data, the CNN is trained using an adversarial approach employing cross-entropy as a segmentation loss along with losses aggregated from three discriminators of which two employ relativistic visual Turing test. This method is experimentally validated on the ISLES-2015 dataset through three-fold cross-validation to obtain with an average Dice score of 0.82 and 0.73 for segmentation of penumbra and core respectively.
Unit Impulse Response as an Explainer of Redundancy in a Deep Convolutional Neural Network
Jun 10, 2019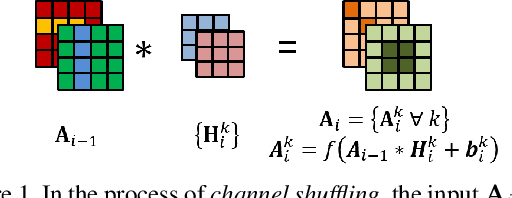
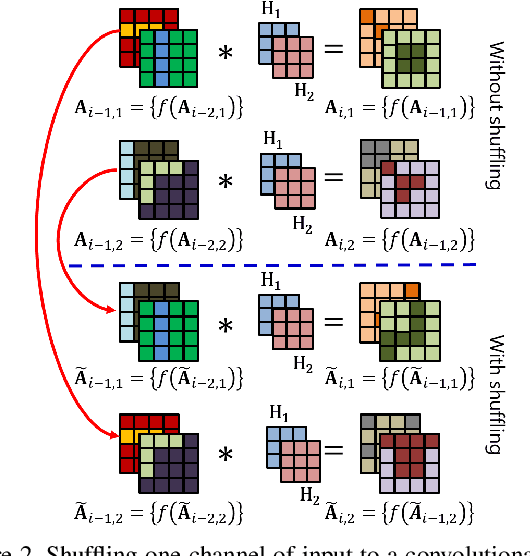
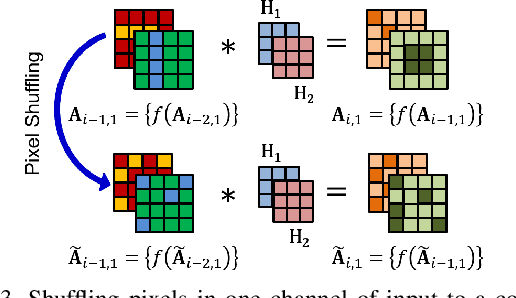
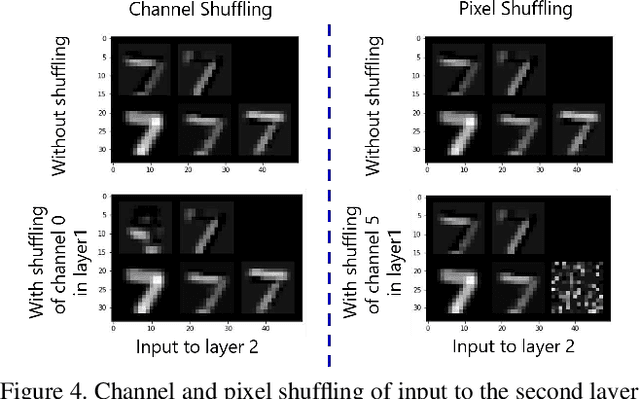
Convolutional neural networks (CNN) are generally designed with a heuristic initialization of network architecture and trained for a certain task. This often leads to overparametrization after learning and induces redundancy in the information flow paths within the network. This robustness and reliability is at the increased cost of redundant computations. Several methods have been proposed which leverage metrics that quantify the redundancy in each layer. However, layer-wise evaluation in these methods disregards the long-range redundancy which exists across depth on account of the distributed nature of the features learned by the model. In this paper, we propose (i) a mechanism to empirically demonstrate the robustness in performance of a CNN on account of redundancy across its depth, (ii) a method to identify the systemic redundancy in response of a CNN across depth using the understanding of unit impulse response, we subsequently demonstrate use of these methods to interpret redundancy in few networks as example. These techniques provide better insights into the internal dynamics of a CNN
Multitask Learning of Temporal Connectionism in Convolutional Networks using a Joint Distribution Loss Function to Simultaneously Identify Tools and Phase in Surgical Videos
May 25, 2019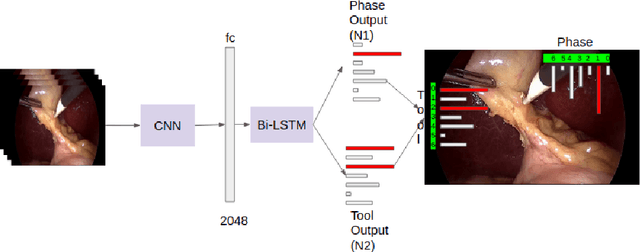
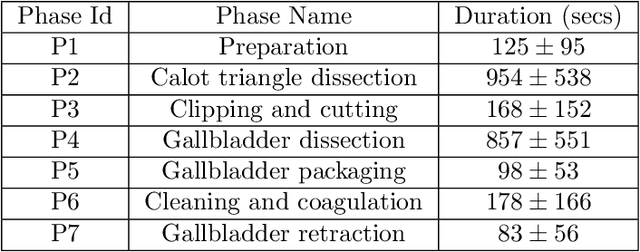
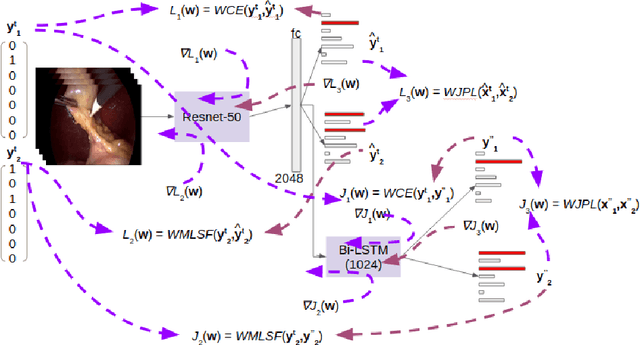
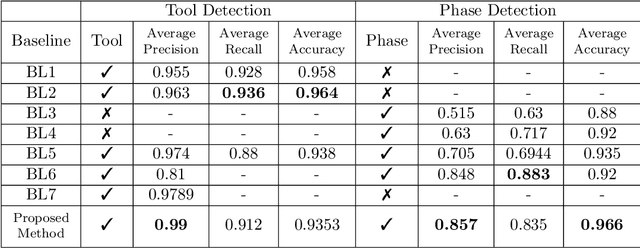
Surgical workflow analysis is of importance for understanding onset and persistence of surgical phases and individual tool usage across surgery and in each phase. It is beneficial for clinical quality control and to hospital administrators for understanding surgery planning. Video acquired during surgery typically can be leveraged for this task. Currently, a combination of convolutional neural network (CNN) and recurrent neural networks (RNN) are popularly used for video analysis in general, not only being restricted to surgical videos. In this paper, we propose a multi-task learning framework using CNN followed by a bi-directional long short term memory (Bi-LSTM) to learn to encapsulate both forward and backward temporal dependencies. Further, the joint distribution indicating set of tools associated with a phase is used as an additional loss during learning to correct for their co-occurrence in any predictions. Experimental evaluation is performed using the Cholec80 dataset. We report a mean average precision (mAP) score of 0.99 and 0.86 for tool and phase identification respectively which are higher compared to prior-art in the field.