 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly detection in non-stationary videos using time-recursive differencing network based prediction
Mar 04, 2025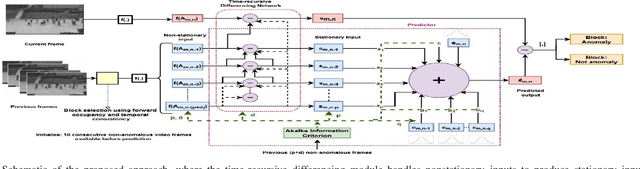



Most videos, including those captured through aerial remote sensing, are usually non-stationary in nature having time-varying feature statistics. Although, sophisticated reconstruction and prediction models exist for video anomaly detection, effective handling of non-stationarity has seldom been considered explicitly. In this paper, we propose to perform prediction using a time-recursive differencing network followed by autoregressive moving average estimation for video anomaly detection. The differencing network is employed to effectively handle non-stationarity in video data during the anomaly detection. Focusing on the prediction process, the effectiveness of the proposed approach is demonstrated considering a simple optical flow based video feature, and by generating qualitative and quantitative results on three aerial video datasets and two standard anomaly detection video datasets. EER, AUC and ROC curve based comparison with several existing methods including the state-of-the-art reveal the superiority of the proposed approach.
* Copyright 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Histopathological Image Analysis with Style-Augmented Feature Domain Mixing for Improved Generalization
Oct 31, 2023



Histopathological images are essential for medical diagnosis and treatment planning, but interpreting them accurately using machine learning can be challenging due to variations in tissue preparation, staining and imaging protocols. Domain generalization aims to address such limitations by enabling the learning models to generalize to new datasets or populations. Style transfer-based data augmentation is an emerging technique that can be used to improve the generalizability of machine learning models for histopathological images. However, existing style transfer-based methods can be computationally expensive, and they rely on artistic styles, which can negatively impact model accuracy. In this study, we propose a feature domain style mixing technique that uses adaptive instance normalization to generate style-augmented versions of images. We compare our proposed method with existing style transfer-based data augmentation methods and found that it performs similarly or better, despite requiring less computation and time. Our results demonstrate the potential of feature domain statistics mixing in the generalization of learning models for histopathological image analysis.
Transmission Map and Atmospheric Light Guided Iterative Updater Network for Single Image Dehazing
Aug 04, 2020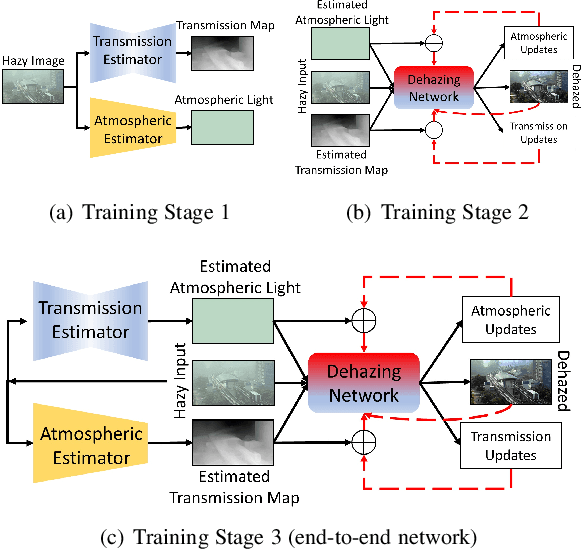



Hazy images obscure content visibility and hinder several subsequent computer vision tasks. For dehazing in a wide variety of hazy conditions, an end-to-end deep network jointly estimating the dehazed image along with suitable transmission map and atmospheric light for guidance could prove effective. To this end, we propose an Iterative Prior Updated Dehazing Network (IPUDN) based on a novel iterative update framework. We present a novel convolutional architecture to estimate channel-wise atmospheric light, which along with an estimated transmission map are used as priors for the dehazing network. Use of channel-wise atmospheric light allows our network to handle color casts in hazy images. In our IPUDN, the transmission map and atmospheric light estimates are updated iteratively using corresponding novel updater networks. The iterative mechanism is leveraged to gradually modify the estimates toward those appropriately representing the hazy condition. These updates occur jointly with the iterative estimation of the dehazed image using a convolutional neural network with LSTM driven recurrence, which introduces inter-iteration dependencies. Our approach is qualitatively and quantitatively found effective for synthetic and real-world hazy images depicting varied hazy conditions, and it outperforms the state-of-the-art. Thorough analyses of IPUDN through additional experiments and detailed ablation studies are also presented.
Across-scale Process Similarity based Interpolation for Image Super-Resolution
Mar 20, 2020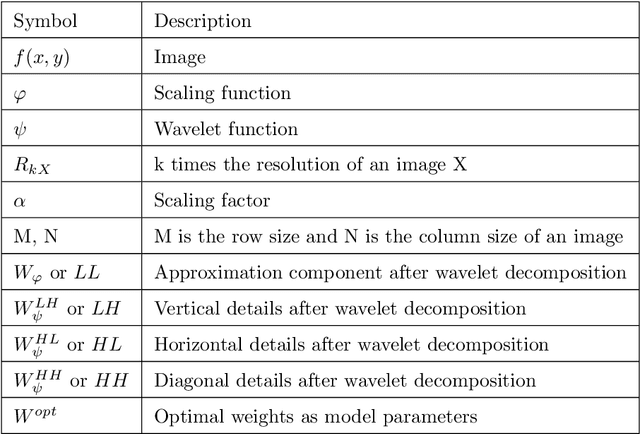
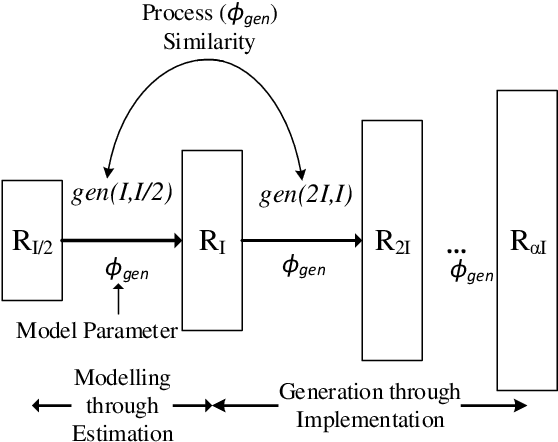
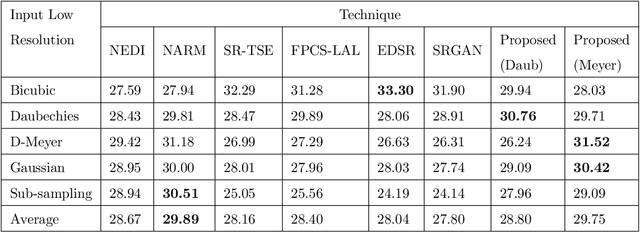

A pivotal step in image super-resolution techniques is interpolation, which aims at generating high resolution images without introducing artifacts such as blurring and ringing. In this paper, we propose a technique that performs interpolation through an infusion of high frequency signal components computed by exploiting `process similarity'. By `process similarity', we refer to the resemblance between a decomposition of the image at a resolution to the decomposition of the image at another resolution. In our approach, the decompositions generating image details and approximations are obtained through the discrete wavelet (DWT) and stationary wavelet (SWT) transforms. The complementary nature of DWT and SWT is leveraged to get the structural relation between the input image and its low resolution approximation. The structural relation is represented by optimal model parameters obtained through particle swarm optimization (PSO). Owing to process similarity, these parameters are used to generate the high resolution output image from the input image. The proposed approach is compared with six existing techniques qualitatively and in terms of PSNR, SSIM, and FSIM measures, along with computation time (CPU time). It is found that our approach is the fastest in terms of CPU time and produces comparable results.
Evaluating Salient Object Detection in Natural Images with Multiple Objects having Multi-level Saliency
Mar 19, 2020
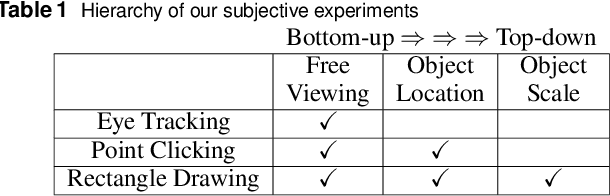

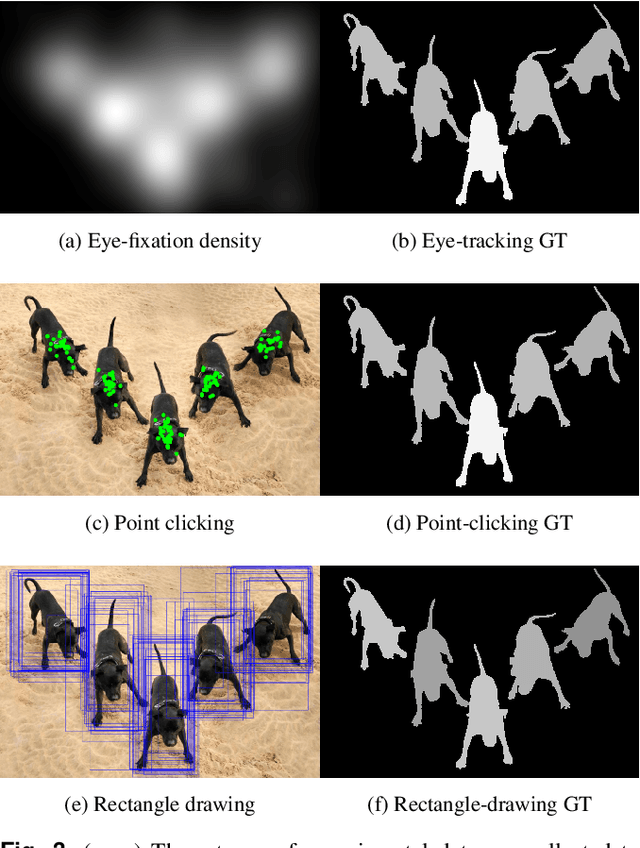
Salient object detection is evaluated using binary ground truth with the labels being salient object class and background. In this paper, we corroborate based on three subjective experiments on a novel image dataset that objects in natural images are inherently perceived to have varying levels of importance. Our dataset, named SalMoN (saliency in multi-object natural images), has 588 images containing multiple objects. The subjective experiments performed record spontaneous attention and perception through eye fixation duration, point clicking and rectangle drawing. As object saliency in a multi-object image is inherently multi-level, we propose that salient object detection must be evaluated for the capability to detect all multi-level salient objects apart from the salient object class detection capability. For this purpose, we generate multi-level maps as ground truth corresponding to all the dataset images using the results of the subjective experiments, with the labels being multi-level salient objects and background. We then propose the use of mean absolute error, Kendall's rank correlation and average area under precision-recall curve to evaluate existing salient object detection methods on our multi-level saliency ground truth dataset. Approaches that represent saliency detection on images as local-global hierarchical processing of a graph perform well in our dataset.
* Accepted Article
Video Skimming: Taxonomy and Comprehensive Survey
Sep 21, 2019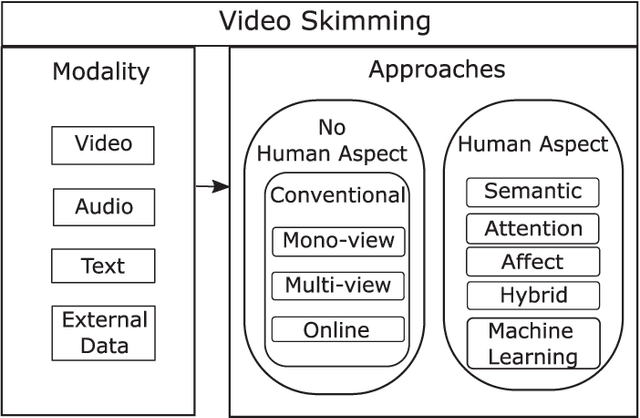
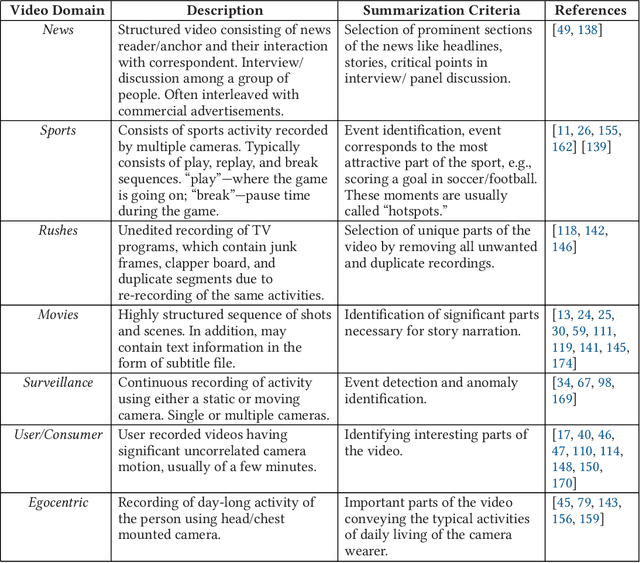
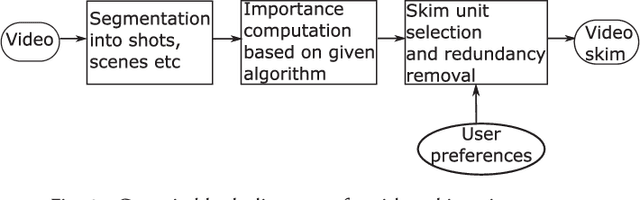
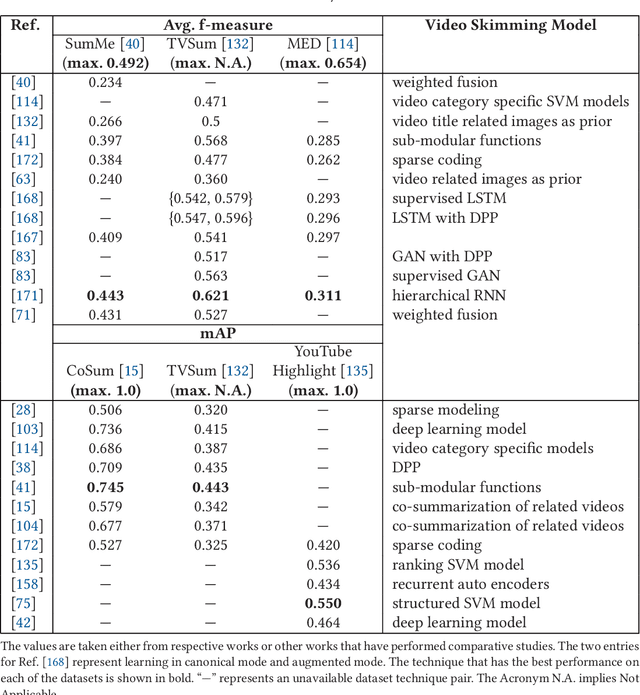
Video skimming, also known as dynamic video summarization, generates a temporally abridged version of a given video. Skimming can be achieved by identifying significant components either in uni-modal or multi-modal features extracted from the video. Being dynamic in nature, video skimming, through temporal connectivity, allows better understanding of the video from its summary. Having this obvious advantage, recently, video skimming has drawn the focus of many researchers benefiting from the easy availability of the required computing resources. In this paper, we provide a comprehensive survey on video skimming focusing on the substantial amount of literature from the past decade. We present a taxonomy of video skimming approaches, and discuss their evolution highlighting key advances. We also provide a study on the components required for the evaluation of a video skimming performance.
KarNet: An Efficient Boolean Function Simplifier
Jun 04, 2019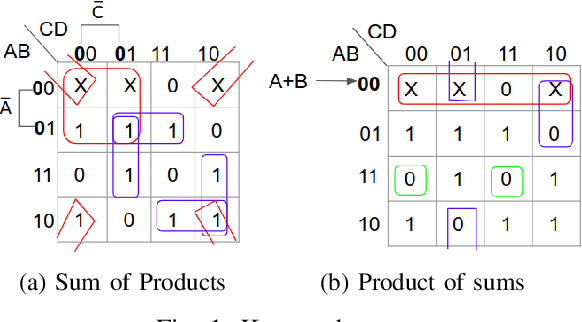
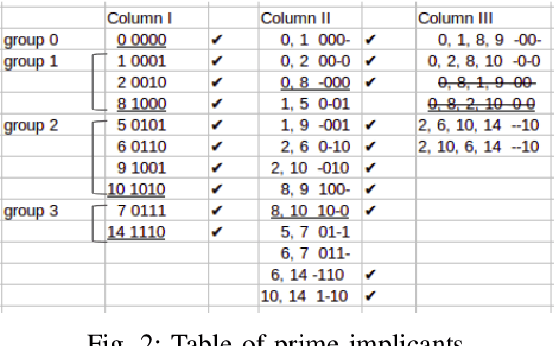
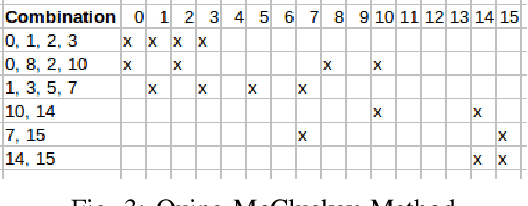
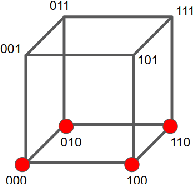
Many approaches such as Quine-McCluskey algorithm, Karnaugh map solving, Petrick's method and McBoole's method have been devised to simplify Boolean expressions in order to optimize hardware implementation of digital circuits. However, the algorithmic implementations of these methods are hard-coded and also their computation time is proportional to the number of minterms involved in the expression. In this paper, we propose KarNet, where the ability of Convolutional Neural Networks to model relationships between various cell locations and values by capturing spatial dependencies is exploited to solve Karnaugh maps. In order to do so, a Karnaugh map is represented as an image signal, where each cell is considered as a pixel. Experimental results show that the computation time of KarNet is independent of the number of minterms and is of the order of one-hundredth to one-tenth that of the rule-based methods. KarNet being a learned system is found to achieve nearly a hundred percent accuracy, precision, and recall. We train KarNet to solve four variable Karnaugh maps and also show that a similar method can be applied on Karnaugh maps with more variables. Finally, we show a way to build a fully accurate and computationally fast system using KarNet.