 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistopathological Image Analysis with Style-Augmented Feature Domain Mixing for Improved Generalization
Oct 31, 2023



Histopathological images are essential for medical diagnosis and treatment planning, but interpreting them accurately using machine learning can be challenging due to variations in tissue preparation, staining and imaging protocols. Domain generalization aims to address such limitations by enabling the learning models to generalize to new datasets or populations. Style transfer-based data augmentation is an emerging technique that can be used to improve the generalizability of machine learning models for histopathological images. However, existing style transfer-based methods can be computationally expensive, and they rely on artistic styles, which can negatively impact model accuracy. In this study, we propose a feature domain style mixing technique that uses adaptive instance normalization to generate style-augmented versions of images. We compare our proposed method with existing style transfer-based data augmentation methods and found that it performs similarly or better, despite requiring less computation and time. Our results demonstrate the potential of feature domain statistics mixing in the generalization of learning models for histopathological image analysis.
Self Supervised Low Dose Computed Tomography Image Denoising Using Invertible Network Exploiting Inter Slice Congruence
Nov 03, 2022The resurgence of deep neural networks has created an alternative pathway for low-dose computed tomography denoising by learning a nonlinear transformation function between low-dose CT (LDCT) and normal-dose CT (NDCT) image pairs. However, those paired LDCT and NDCT images are rarely available in the clinical environment, making deep neural network deployment infeasible. This study proposes a novel method for self-supervised low-dose CT denoising to alleviate the requirement of paired LDCT and NDCT images. Specifically, we have trained an invertible neural network to minimize the pixel-based mean square distance between a noisy slice and the average of its two immediate adjacent noisy slices. We have shown the aforementioned is similar to training a neural network to minimize the distance between clean NDCT and noisy LDCT image pairs. Again, during the reverse mapping of the invertible network, the output image is mapped to the original input image, similar to cycle consistency loss. Finally, the trained invertible network's forward mapping is used for denoising LDCT images. Extensive experiments on two publicly available datasets showed that our method performs favourably against other existing unsupervised methods.
Iterative Gradient Encoding Network with Feature Co-Occurrence Loss for Single Image Reflection Removal
Mar 29, 2021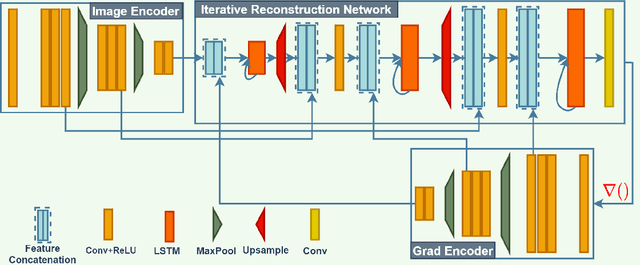



Removing undesired reflections from a photo taken in front of glass is of great importance for enhancing visual computing systems' efficiency. Previous learning-based approaches have produced visually plausible results for some reflections type, however, failed to generalize against other reflection types. There is a dearth of literature for efficient methods concerning single image reflection removal, which can generalize well in large-scale reflection types. In this study, we proposed an iterative gradient encoding network for single image reflection removal. Next, to further supervise the network in learning the correlation between the transmission layer features, we proposed a feature co-occurrence loss. Extensive experiments on the public benchmark dataset of SIR$^2$ demonstrated that our method can remove reflection favorably against the existing state-of-the-art method on all imaging settings, including diverse backgrounds. Moreover, as the reflection strength increases, our method can still remove reflection even where other state of the art methods failed.
Noise Conscious Training of Non Local Neural Network powered by Self Attentive Spectral Normalized Markovian Patch GAN for Low Dose CT Denoising
Nov 11, 2020
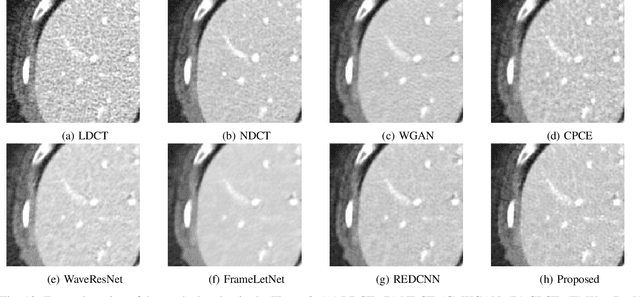
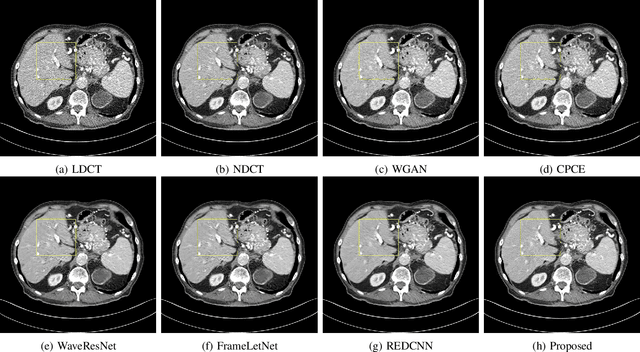
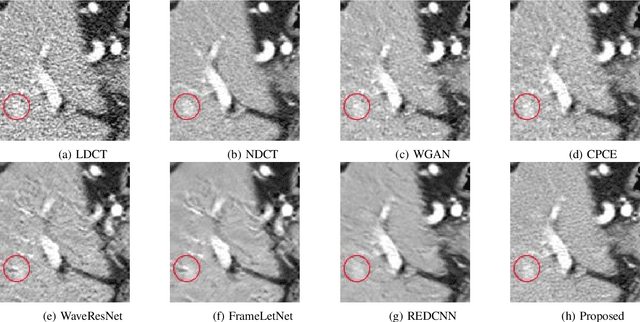
The explosive rise of the use of Computer tomography (CT) imaging in medical practice has heightened public concern over the patient's associated radiation dose. However, reducing the radiation dose leads to increased noise and artifacts, which adversely degrades the scan's interpretability. Consequently, an advanced image reconstruction algorithm to improve the diagnostic performance of low dose ct arose as the primary concern among the researchers, which is challenging due to the ill-posedness of the problem. In recent times, the deep learning-based technique has emerged as a dominant method for low dose CT(LDCT) denoising. However, some common bottleneck still exists, which hinders deep learning-based techniques from furnishing the best performance. In this study, we attempted to mitigate these problems with three novel accretions. First, we propose a novel convolutional module as the first attempt to utilize neighborhood similarity of CT images for denoising tasks. Our proposed module assisted in boosting the denoising by a significant margin. Next, we moved towards the problem of non-stationarity of CT noise and introduced a new noise aware mean square error loss for LDCT denoising. Moreover, the loss mentioned above also assisted to alleviate the laborious effort required while training CT denoising network using image patches. Lastly, we propose a novel discriminator function for CT denoising tasks. The conventional vanilla discriminator tends to overlook the fine structural details and focus on the global agreement. Our proposed discriminator leverage self-attention and pixel-wise GANs for restoring the diagnostic quality of LDCT images. Our method validated on a publicly available dataset of the 2016 NIH-AAPM-Mayo Clinic Low Dose CT Grand Challenge performed remarkably better than the existing state of the art method.
Lightweight Modules for Efficient Deep Learning based Image Restoration
Jul 11, 2020
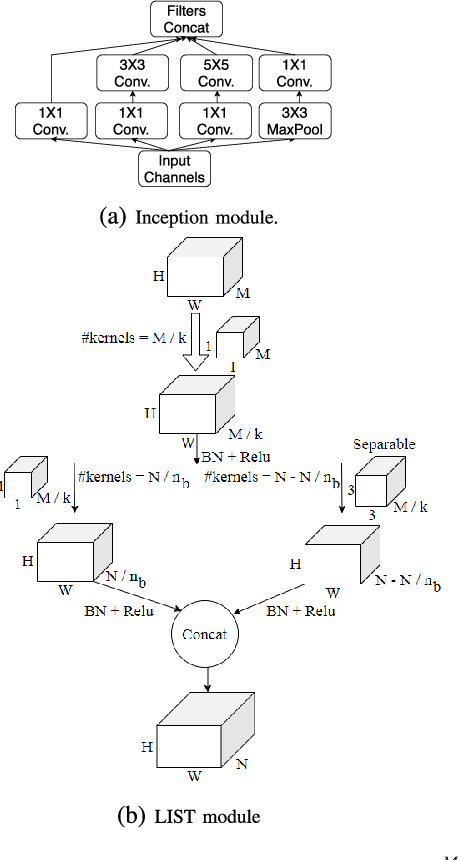
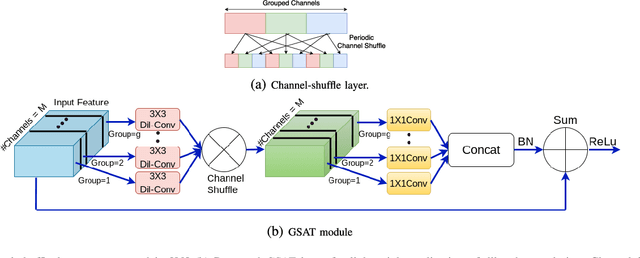
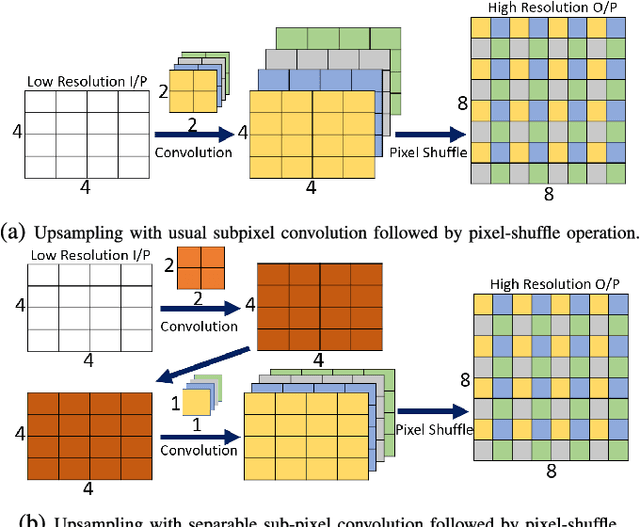
Low level image restoration is an integral component of modern artificial intelligence (AI) driven camera pipelines. Most of these frameworks are based on deep neural networks which present a massive computational overhead on resource constrained platform like a mobile phone. In this paper, we propose several lightweight low-level modules which can be used to create a computationally low cost variant of a given baseline model. Recent works for efficient neural networks design have mainly focused on classification. However, low-level image processing falls under the image-to-image' translation genre which requires some additional computational modules not present in classification. This paper seeks to bridge this gap by designing generic efficient modules which can replace essential components used in contemporary deep learning based image restoration networks. We also present and analyse our results highlighting the drawbacks of applying depthwise separable convolutional kernel (a popular method for efficient classification network) for sub-pixel convolution based upsampling (a popular upsampling strategy for low-level vision applications). This shows that concepts from domain of classification cannot always be seamlessly integrated into image-to-image translation tasks. We extensively validate our findings on three popular tasks of image inpainting, denoising and super-resolution. Our results show that proposed networks consistently output visually similar reconstructions compared to full capacity baselines with significant reduction of parameters, memory footprint and execution speeds on contemporary mobile devices.