 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrid Partitioned Attention: Efficient TransformerApproximation with Inductive Bias for High Resolution Detail Generation
Jul 08, 2021


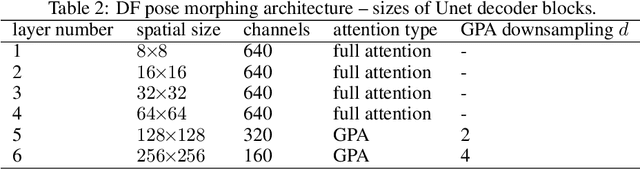
Attention is a general reasoning mechanism than can flexibly deal with image information, but its memory requirements had made it so far impractical for high resolution image generation. We present Grid Partitioned Attention (GPA), a new approximate attention algorithm that leverages a sparse inductive bias for higher computational and memory efficiency in image domains: queries attend only to few keys, spatially close queries attend to close keys due to correlations. Our paper introduces the new attention layer, analyzes its complexity and how the trade-off between memory usage and model power can be tuned by the hyper-parameters.We will show how such attention enables novel deep learning architectures with copying modules that are especially useful for conditional image generation tasks like pose morphing. Our contributions are (i) algorithm and code1of the novel GPA layer, (ii) a novel deep attention-copying architecture, and (iii) new state-of-the art experimental results in human pose morphing generation benchmarks.
Evaluating Salient Object Detection in Natural Images with Multiple Objects having Multi-level Saliency
Mar 19, 2020

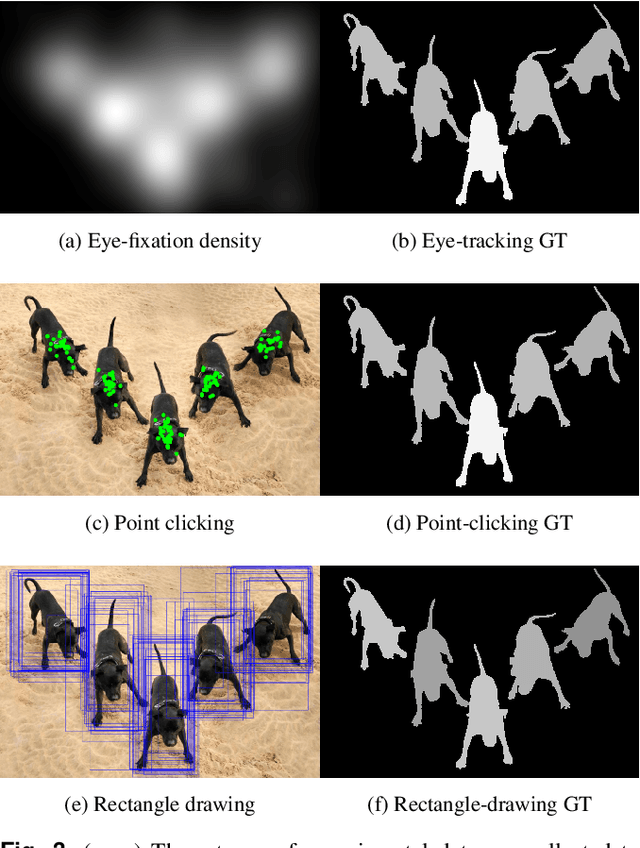
Salient object detection is evaluated using binary ground truth with the labels being salient object class and background. In this paper, we corroborate based on three subjective experiments on a novel image dataset that objects in natural images are inherently perceived to have varying levels of importance. Our dataset, named SalMoN (saliency in multi-object natural images), has 588 images containing multiple objects. The subjective experiments performed record spontaneous attention and perception through eye fixation duration, point clicking and rectangle drawing. As object saliency in a multi-object image is inherently multi-level, we propose that salient object detection must be evaluated for the capability to detect all multi-level salient objects apart from the salient object class detection capability. For this purpose, we generate multi-level maps as ground truth corresponding to all the dataset images using the results of the subjective experiments, with the labels being multi-level salient objects and background. We then propose the use of mean absolute error, Kendall's rank correlation and average area under precision-recall curve to evaluate existing salient object detection methods on our multi-level saliency ground truth dataset. Approaches that represent saliency detection on images as local-global hierarchical processing of a graph perform well in our dataset.
* Accepted Article
Transform the Set: Memory Attentive Generation of Guided and Unguided Image Collages
Oct 16, 2019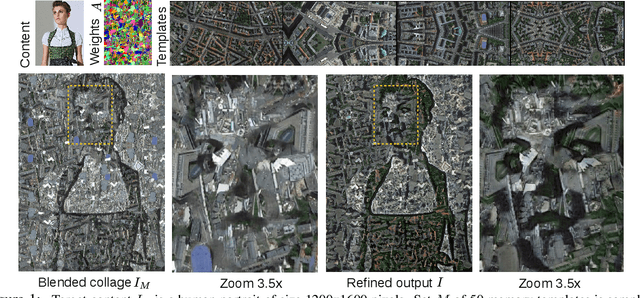

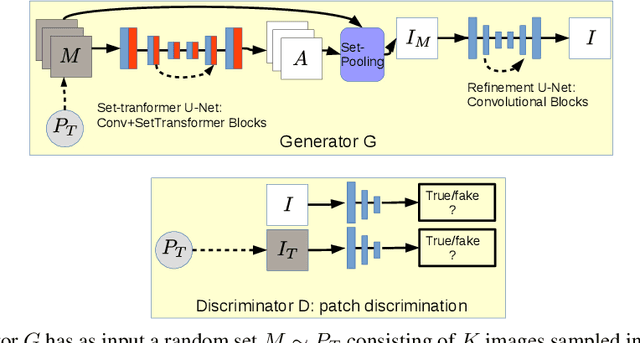
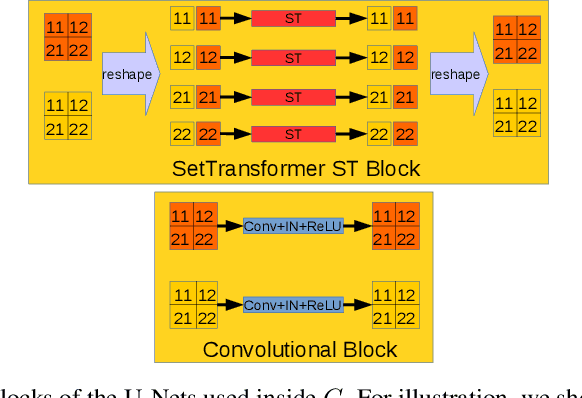
Cutting and pasting image segments feels intuitive: the choice of source templates gives artists flexibility in recombining existing source material. Formally, this process takes an image set as input and outputs a collage of the set elements. Such selection from sets of source templates does not fit easily in classical convolutional neural models requiring inputs of fixed size. Inspired by advances in attention and set-input machine learning, we present a novel architecture that can generate in one forward pass image collages of source templates using set-structured representations. This paper has the following contributions: (i) a novel framework for image generation called Memory Attentive Generation of Image Collages (MAGIC) which gives artists new ways to create digital collages; (ii) from the machine-learning perspective, we show a novel Generative Adversarial Networks (GAN) architecture that uses Set-Transformer layers and set-pooling to blend sets of random image samples - a hybrid non-parametric approach.
Generating High-Resolution Fashion Model Images Wearing Custom Outfits
Aug 23, 2019

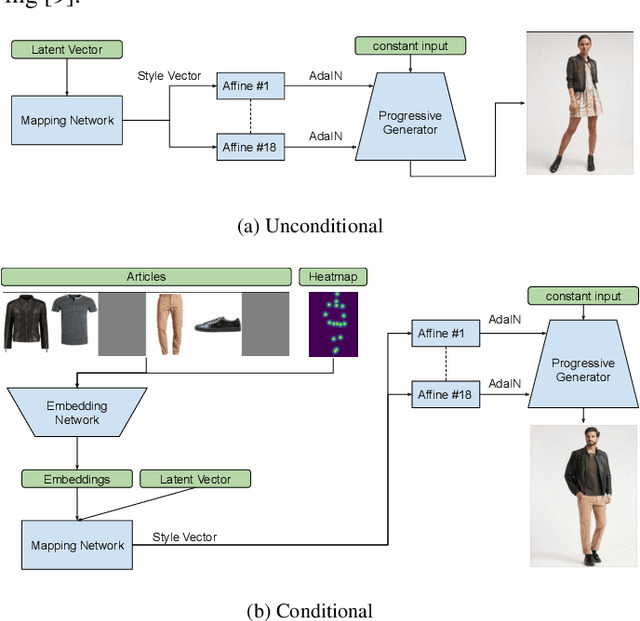

Visualizing an outfit is an essential part of shopping for clothes. Due to the combinatorial aspect of combining fashion articles, the available images are limited to a pre-determined set of outfits. In this paper, we broaden these visualizations by generating high-resolution images of fashion models wearing a custom outfit under an input body pose. We show that our approach can not only transfer the style and the pose of one generated outfit to another, but also create realistic images of human bodies and garments.
Disentangling Multiple Conditional Inputs in GANs
Jun 20, 2018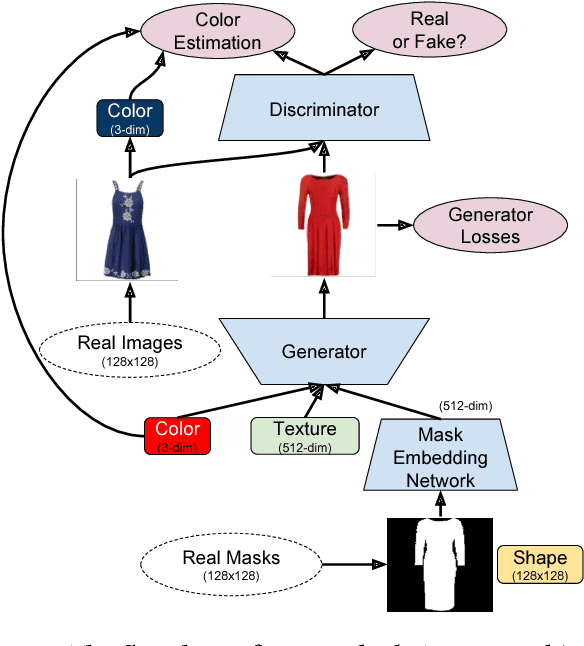



In this paper, we propose a method that disentangles the effects of multiple input conditions in Generative Adversarial Networks (GANs). In particular, we demonstrate our method in controlling color, texture, and shape of a generated garment image for computer-aided fashion design. To disentangle the effect of input attributes, we customize conditional GANs with consistency loss functions. In our experiments, we tune one input at a time and show that we can guide our network to generate novel and realistic images of clothing articles. In addition, we present a fashion design process that estimates the input attributes of an existing garment and modifies them using our generator.