 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClipMatrix: Text-controlled Creation of 3D Textured Meshes
Sep 27, 2021
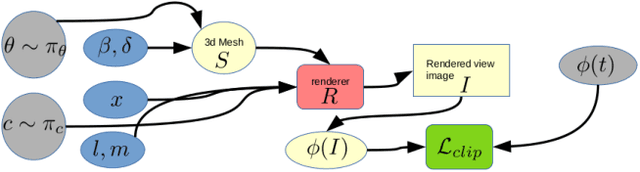


If a picture is worth thousand words, a moving 3d shape must be worth a million. We build upon the success of recent generative methods that create images fitting the semantics of a text prompt, and extend it to the controlled generation of 3d objects. We present a novel algorithm for the creation of textured 3d meshes, controlled by text prompts. Our method creates aesthetically pleasing high resolution articulated 3d meshes, and opens new possibilities for automation and AI control of 3d assets. We call it "ClipMatrix" because it leverages CLIP text embeddings to breed new digital 3d creatures, a nod to the Latin meaning of the word "matrix" - "mother". See the online gallery for a full impression of our method's capability.
Grid Partitioned Attention: Efficient TransformerApproximation with Inductive Bias for High Resolution Detail Generation
Jul 08, 2021


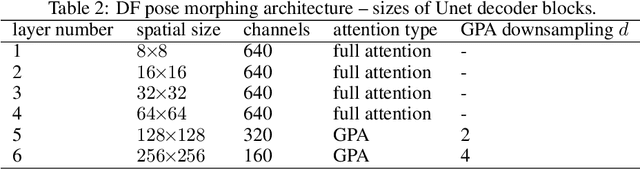
Attention is a general reasoning mechanism than can flexibly deal with image information, but its memory requirements had made it so far impractical for high resolution image generation. We present Grid Partitioned Attention (GPA), a new approximate attention algorithm that leverages a sparse inductive bias for higher computational and memory efficiency in image domains: queries attend only to few keys, spatially close queries attend to close keys due to correlations. Our paper introduces the new attention layer, analyzes its complexity and how the trade-off between memory usage and model power can be tuned by the hyper-parameters.We will show how such attention enables novel deep learning architectures with copying modules that are especially useful for conditional image generation tasks like pose morphing. Our contributions are (i) algorithm and code1of the novel GPA layer, (ii) a novel deep attention-copying architecture, and (iii) new state-of-the art experimental results in human pose morphing generation benchmarks.
Transform the Set: Memory Attentive Generation of Guided and Unguided Image Collages
Oct 16, 2019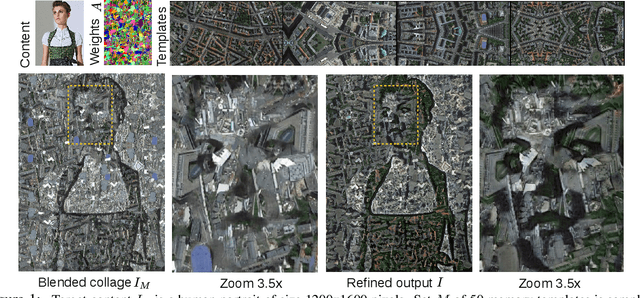

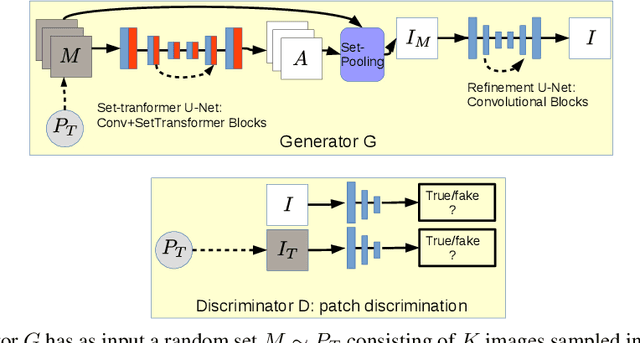
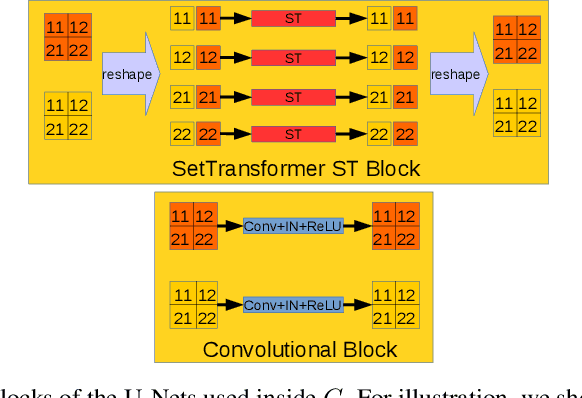
Cutting and pasting image segments feels intuitive: the choice of source templates gives artists flexibility in recombining existing source material. Formally, this process takes an image set as input and outputs a collage of the set elements. Such selection from sets of source templates does not fit easily in classical convolutional neural models requiring inputs of fixed size. Inspired by advances in attention and set-input machine learning, we present a novel architecture that can generate in one forward pass image collages of source templates using set-structured representations. This paper has the following contributions: (i) a novel framework for image generation called Memory Attentive Generation of Image Collages (MAGIC) which gives artists new ways to create digital collages; (ii) from the machine-learning perspective, we show a novel Generative Adversarial Networks (GAN) architecture that uses Set-Transformer layers and set-pooling to blend sets of random image samples - a hybrid non-parametric approach.
Generating High-Resolution Fashion Model Images Wearing Custom Outfits
Aug 23, 2019

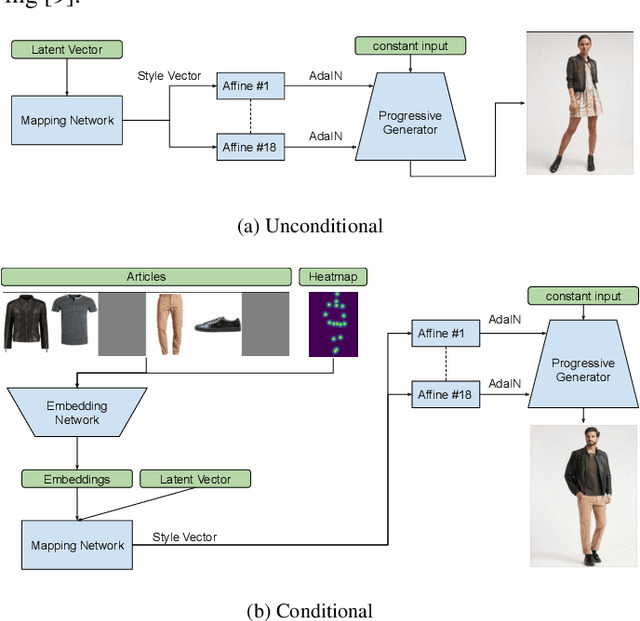

Visualizing an outfit is an essential part of shopping for clothes. Due to the combinatorial aspect of combining fashion articles, the available images are limited to a pre-determined set of outfits. In this paper, we broaden these visualizations by generating high-resolution images of fashion models wearing a custom outfit under an input body pose. We show that our approach can not only transfer the style and the pose of one generated outfit to another, but also create realistic images of human bodies and garments.
Copy the Old or Paint Anew? An Adversarial Framework for Parametric Image Stylization
Nov 22, 2018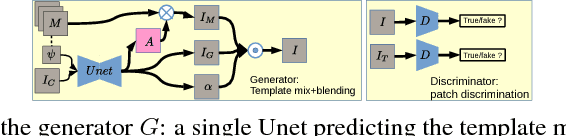



Parametric generative deep models are state-of-the-art for photo and non-photo realistic image stylization. However, learning complicated image representations requires compute-intense models parametrized by a huge number of weights, which in turn requires large datasets to make learning successful. Non-parametric exemplar-based generation is a technique that works well to reproduce style from small datasets, but is also compute-intensive. These aspects are a drawback for the practice of digital AI artists: typically one wants to use a small set of stylization images, and needs a fast flexible model in order to experiment with it. With this motivation, our work has these contributions: (i) a novel stylization method called Fully Adversarial Mosaics (FAMOS) that combines the strengths of both parametric and non-parametric approaches; (ii) multiple ablations and image examples that analyze the method and show its capabilities; (iii) source code that will empower artists and machine learning researchers to use and modify FAMOS.
First Order Generative Adversarial Networks
Jun 07, 2018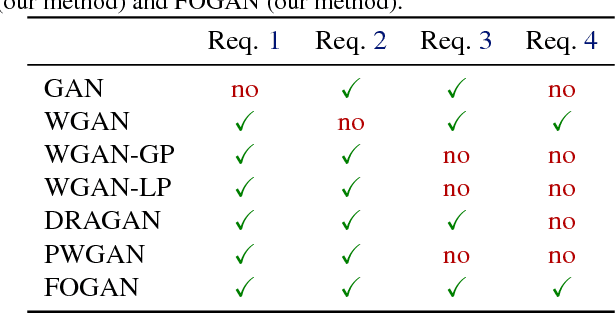


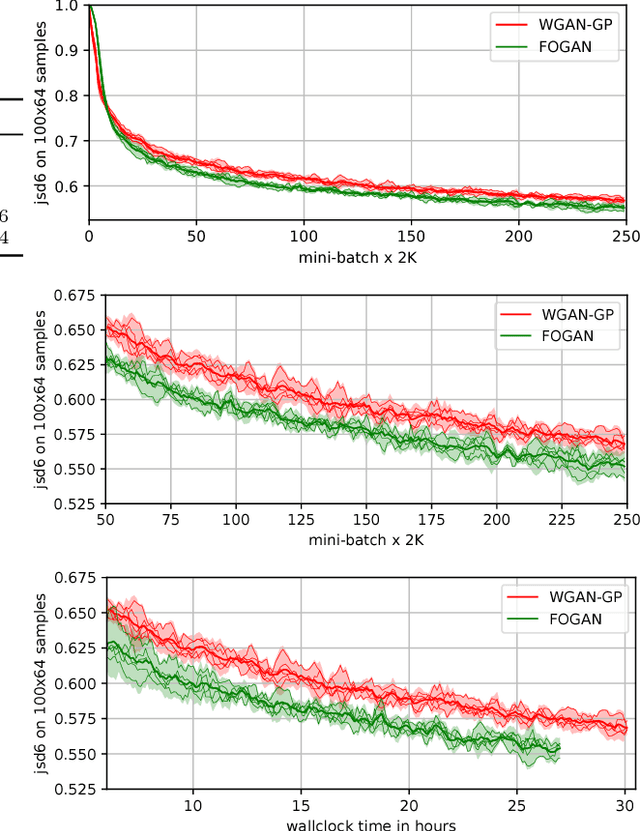
GANs excel at learning high dimensional distributions, but they can update generator parameters in directions that do not correspond to the steepest descent direction of the objective. Prominent examples of problematic update directions include those used in both Goodfellow's original GAN and the WGAN-GP. To formally describe an optimal update direction, we introduce a theoretical framework which allows the derivation of requirements on both the divergence and corresponding method for determining an update direction, with these requirements guaranteeing unbiased mini-batch updates in the direction of steepest descent. We propose a novel divergence which approximates the Wasserstein distance while regularizing the critic's first order information. Together with an accompanying update direction, this divergence fulfills the requirements for unbiased steepest descent updates. We verify our method, the First Order GAN, with image generation on CelebA, LSUN and CIFAR-10 and set a new state of the art on the One Billion Word language generation task. Code to reproduce experiments is available.
GANosaic: Mosaic Creation with Generative Texture Manifolds
Dec 01, 2017
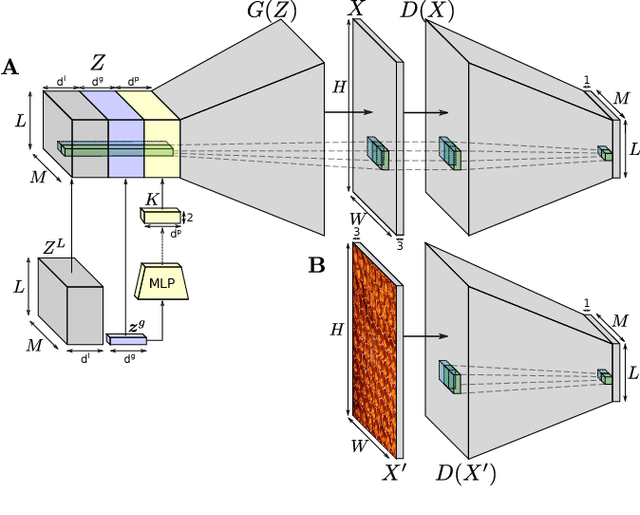

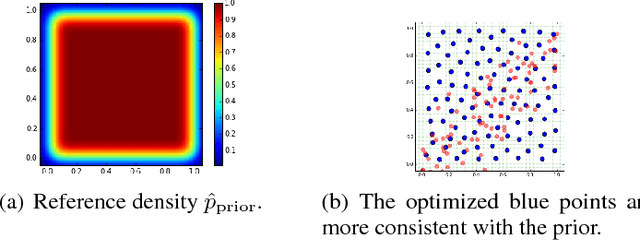
This paper presents a novel framework for generating texture mosaics with convolutional neural networks. Our method is called GANosaic and performs optimization in the latent noise space of a generative texture model, which allows the transformation of a content image into a mosaic exhibiting the visual properties of the underlying texture manifold. To represent that manifold, we use a state-of-the-art generative adversarial method for texture synthesis, which can learn expressive texture representations from data and produce mosaic images with very high resolution. This fully convolutional model generates smooth (without any visible borders) mosaic images which morph and blend different textures locally. In addition, we develop a new type of differentiable statistical regularization appropriate for optimization over the prior noise space of the PSGAN model.
The Conditional Analogy GAN: Swapping Fashion Articles on People Images
Sep 14, 2017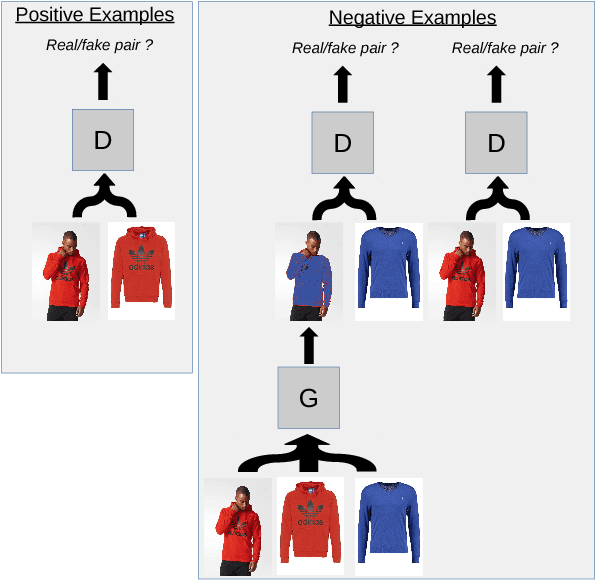
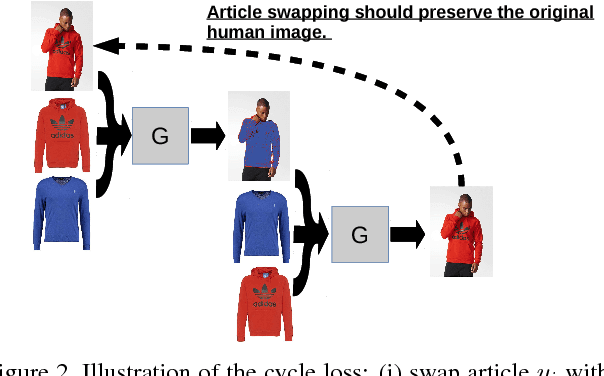

We present a novel method to solve image analogy problems : it allows to learn the relation between paired images present in training data, and then generalize and generate images that correspond to the relation, but were never seen in the training set. Therefore, we call the method Conditional Analogy Generative Adversarial Network (CAGAN), as it is based on adversarial training and employs deep convolutional neural networks. An especially interesting application of that technique is automatic swapping of clothing on fashion model photos. Our work has the following contributions. First, the definition of the end-to-end trainable CAGAN architecture, which implicitly learns segmentation masks without expensive supervised labeling data. Second, experimental results show plausible segmentation masks and often convincing swapped images, given the target article. Finally, we discuss the next steps for that technique: neural network architecture improvements and more advanced applications.
Learning Texture Manifolds with the Periodic Spatial GAN
Sep 08, 2017
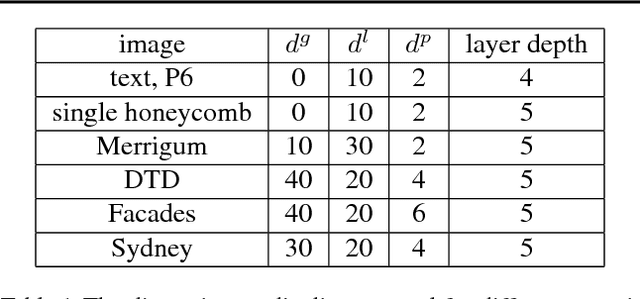
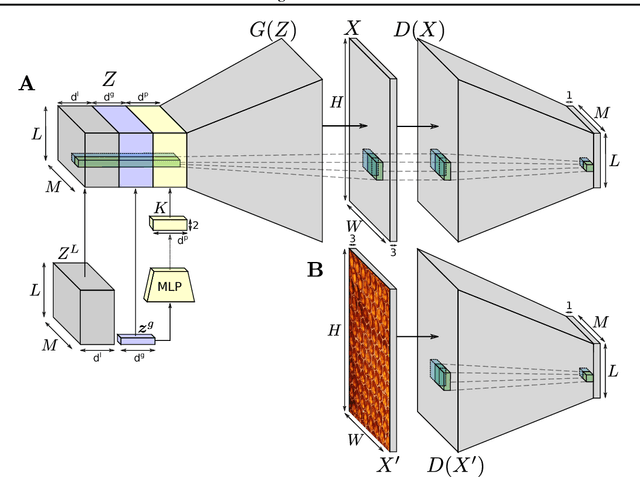
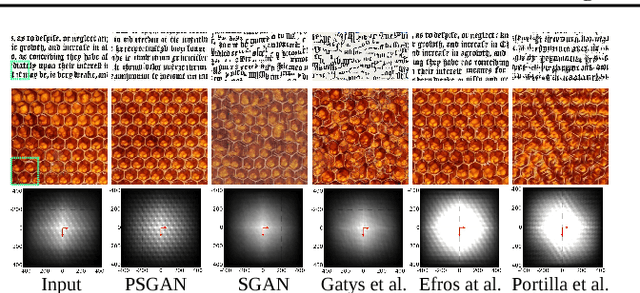
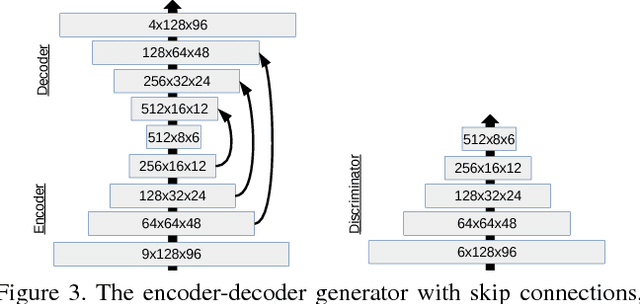
This paper introduces a novel approach to texture synthesis based on generative adversarial networks (GAN) (Goodfellow et al., 2014). We extend the structure of the input noise distribution by constructing tensors with different types of dimensions. We call this technique Periodic Spatial GAN (PSGAN). The PSGAN has several novel abilities which surpass the current state of the art in texture synthesis. First, we can learn multiple textures from datasets of one or more complex large images. Second, we show that the image generation with PSGANs has properties of a texture manifold: we can smoothly interpolate between samples in the structured noise space and generate novel samples, which lie perceptually between the textures of the original dataset. In addition, we can also accurately learn periodical textures. We make multiple experiments which show that PSGANs can flexibly handle diverse texture and image data sources. Our method is highly scalable and it can generate output images of arbitrary large size.
Texture Synthesis with Spatial Generative Adversarial Networks
Sep 08, 2017
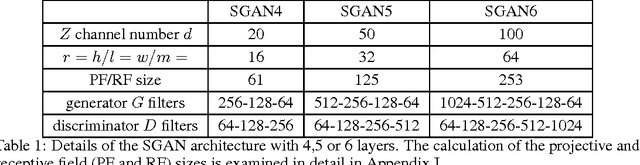
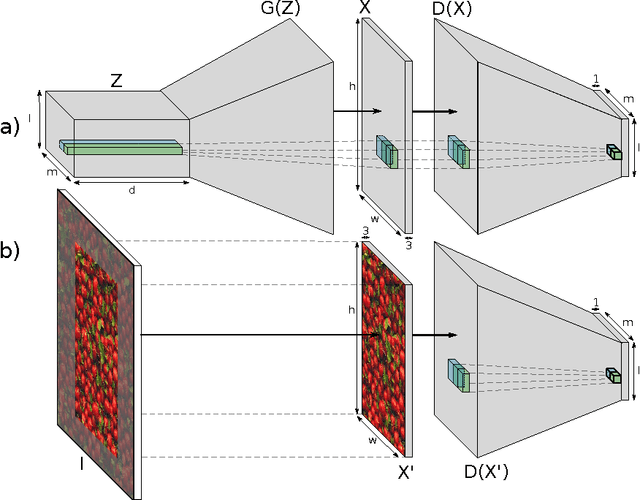
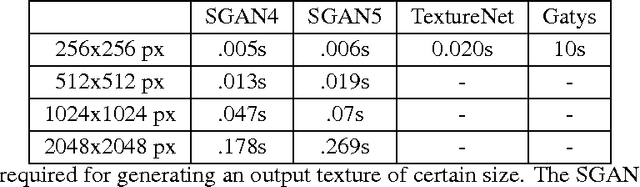
Generative adversarial networks (GANs) are a recent approach to train generative models of data, which have been shown to work particularly well on image data. In the current paper we introduce a new model for texture synthesis based on GAN learning. By extending the input noise distribution space from a single vector to a whole spatial tensor, we create an architecture with properties well suited to the task of texture synthesis, which we call spatial GAN (SGAN). To our knowledge, this is the first successful completely data-driven texture synthesis method based on GANs. Our method has the following features which make it a state of the art algorithm for texture synthesis: high image quality of the generated textures, very high scalability w.r.t. the output texture size, fast real-time forward generation, the ability to fuse multiple diverse source images in complex textures. To illustrate these capabilities we present multiple experiments with different classes of texture images and use cases. We also discuss some limitations of our method with respect to the types of texture images it can synthesize, and compare it to other neural techniques for texture generation.