 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing 3D Abstractions by Inverting Procedural Buildings with Transformers
Jan 29, 2025We generate abstractions of buildings, reflecting the essential aspects of their geometry and structure, by learning to invert procedural models. We first build a dataset of abstract procedural building models paired with simulated point clouds and then learn the inverse mapping through a transformer. Given a point cloud, the trained transformer then infers the corresponding abstracted building in terms of a programmatic language description. This approach leverages expressive procedural models developed for gaming and animation, and thereby retains desirable properties such as efficient rendering of the inferred abstractions and strong priors for regularity and symmetry. Our approach achieves good reconstruction accuracy in terms of geometry and structure, as well as structurally consistent inpainting.
Scene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations
Nov 29, 2021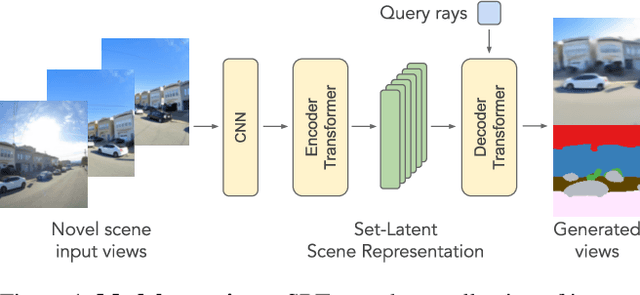

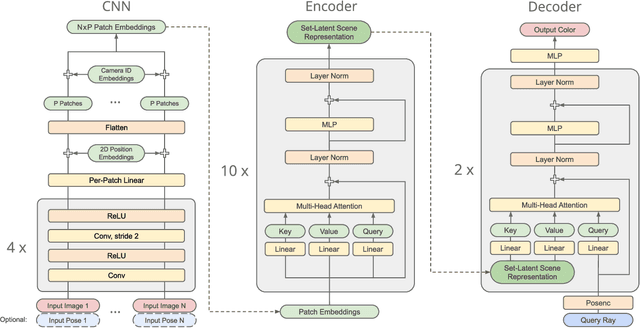
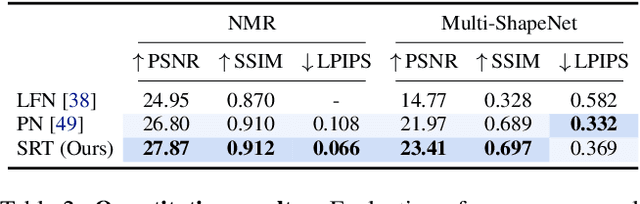
A classical problem in computer vision is to infer a 3D scene representation from few images that can be used to render novel views at interactive rates. Previous work focuses on reconstructing pre-defined 3D representations, e.g. textured meshes, or implicit representations, e.g. radiance fields, and often requires input images with precise camera poses and long processing times for each novel scene. In this work, we propose the Scene Representation Transformer (SRT), a method which processes posed or unposed RGB images of a new area, infers a "set-latent scene representation", and synthesises novel views, all in a single feed-forward pass. To calculate the scene representation, we propose a generalization of the Vision Transformer to sets of images, enabling global information integration, and hence 3D reasoning. An efficient decoder transformer parameterizes the light field by attending into the scene representation to render novel views. Learning is supervised end-to-end by minimizing a novel-view reconstruction error. We show that this method outperforms recent baselines in terms of PSNR and speed on synthetic datasets, including a new dataset created for the paper. Further, we demonstrate that SRT scales to support interactive visualization and semantic segmentation of real-world outdoor environments using Street View imagery.
Multi-variate Probabilistic Time Series Forecasting via Conditioned Normalizing Flows
Feb 14, 2020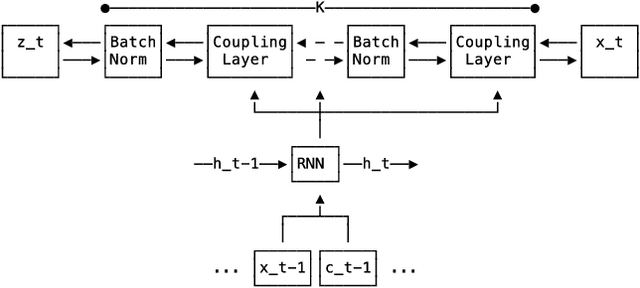

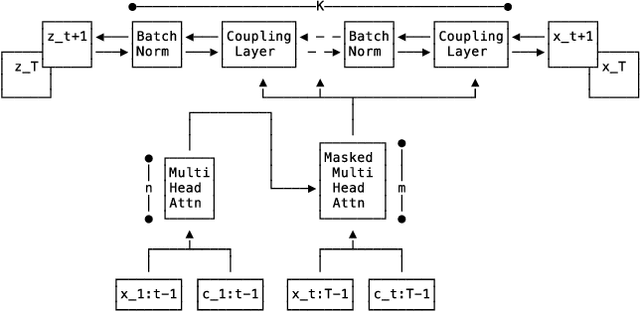
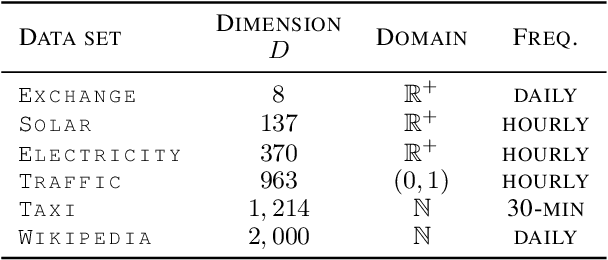
Time series forecasting is often fundamental to scientific and engineering problems and enables decision making. With ever increasing data set sizes, a trivial solution to scale up predictions is to assume independence between interacting time series. However, modeling statistical dependencies can improve accuracy and enable analysis of interaction effects. Deep learning methods are well suited for this problem, but multi-variate models often assume a simple parametric distribution and do not scale to high dimensions. In this work we model the multi-variate temporal dynamics of time series via an autoregressive deep learning model, where the data distribution is represented by a conditioned normalizing flow. This combination retains the power of autoregressive models, such as good performance in extrapolation into the future, with the flexibility of flows as a general purpose high-dimensional distribution model, while remaining computationally tractable. We show that it improves over the state-of-the-art for standard metrics on many real-world data sets with several thousand interacting time-series.
Transform the Set: Memory Attentive Generation of Guided and Unguided Image Collages
Oct 16, 2019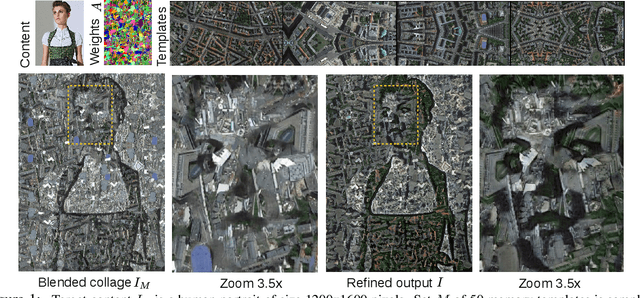

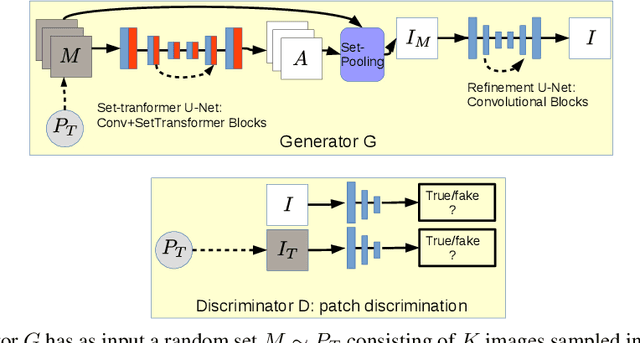
Cutting and pasting image segments feels intuitive: the choice of source templates gives artists flexibility in recombining existing source material. Formally, this process takes an image set as input and outputs a collage of the set elements. Such selection from sets of source templates does not fit easily in classical convolutional neural models requiring inputs of fixed size. Inspired by advances in attention and set-input machine learning, we present a novel architecture that can generate in one forward pass image collages of source templates using set-structured representations. This paper has the following contributions: (i) a novel framework for image generation called Memory Attentive Generation of Image Collages (MAGIC) which gives artists new ways to create digital collages; (ii) from the machine-learning perspective, we show a novel Generative Adversarial Networks (GAN) architecture that uses Set-Transformer layers and set-pooling to blend sets of random image samples - a hybrid non-parametric approach.
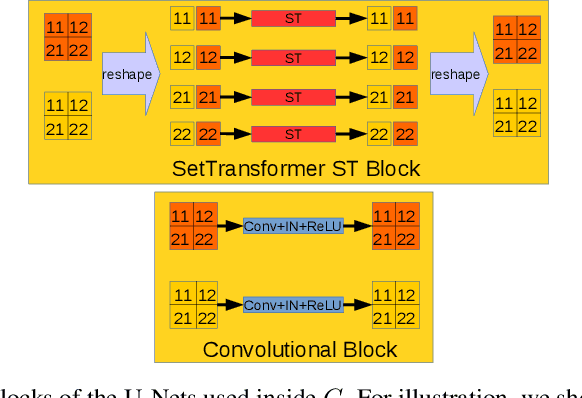
Set Flow: A Permutation Invariant Normalizing Flow
Sep 06, 2019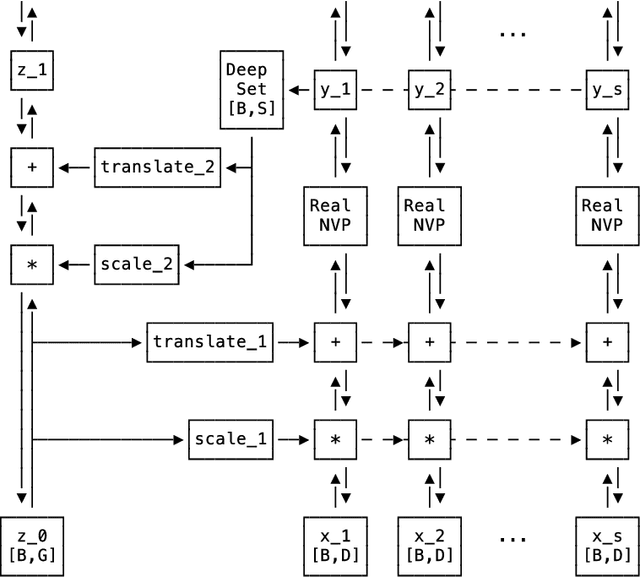
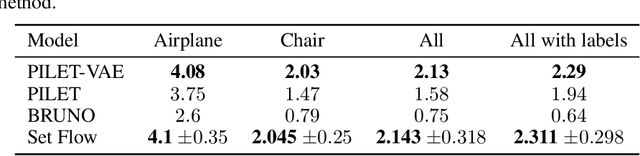
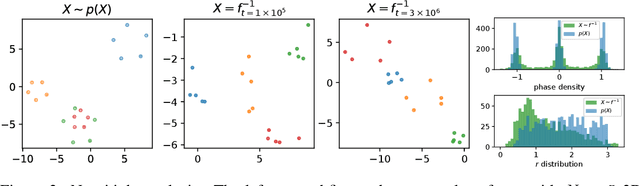
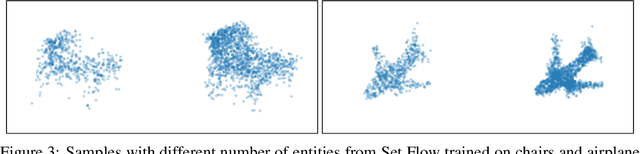
We present a generative model that is defined on finite sets of exchangeable, potentially high dimensional, data. As the architecture is an extension of RealNVPs, it inherits all its favorable properties, such as being invertible and allowing for exact log-likelihood evaluation. We show that this architecture is able to learn finite non-i.i.d. set data distributions, learn statistical dependencies between entities of the set and is able to train and sample with variable set sizes in a computationally efficient manner. Experiments on 3D point clouds show state-of-the art likelihoods.
Generating High-Resolution Fashion Model Images Wearing Custom Outfits
Aug 23, 2019

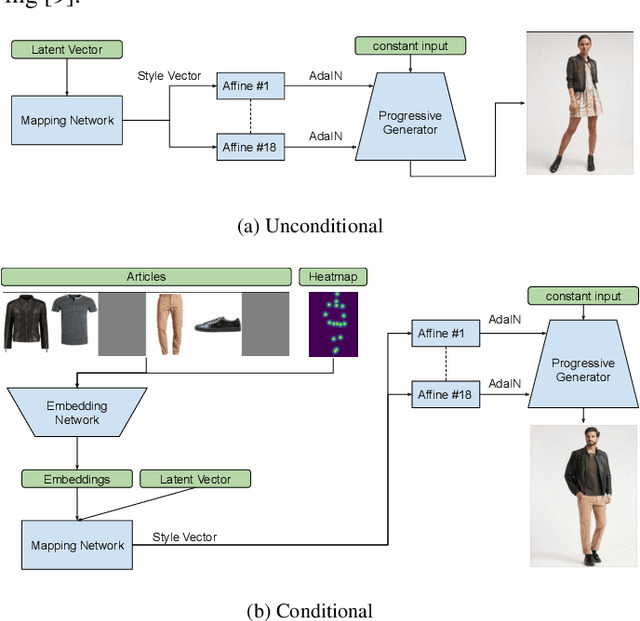

Visualizing an outfit is an essential part of shopping for clothes. Due to the combinatorial aspect of combining fashion articles, the available images are limited to a pre-determined set of outfits. In this paper, we broaden these visualizations by generating high-resolution images of fashion models wearing a custom outfit under an input body pose. We show that our approach can not only transfer the style and the pose of one generated outfit to another, but also create realistic images of human bodies and garments.
A Hierarchical Bayesian Model for Size Recommendation in Fashion
Aug 02, 2019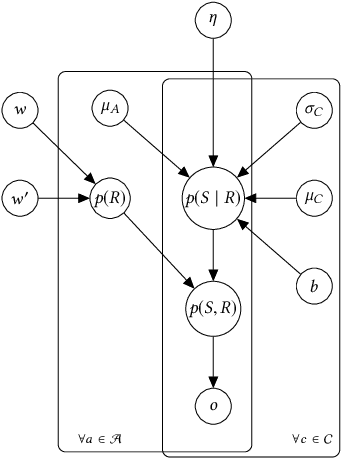

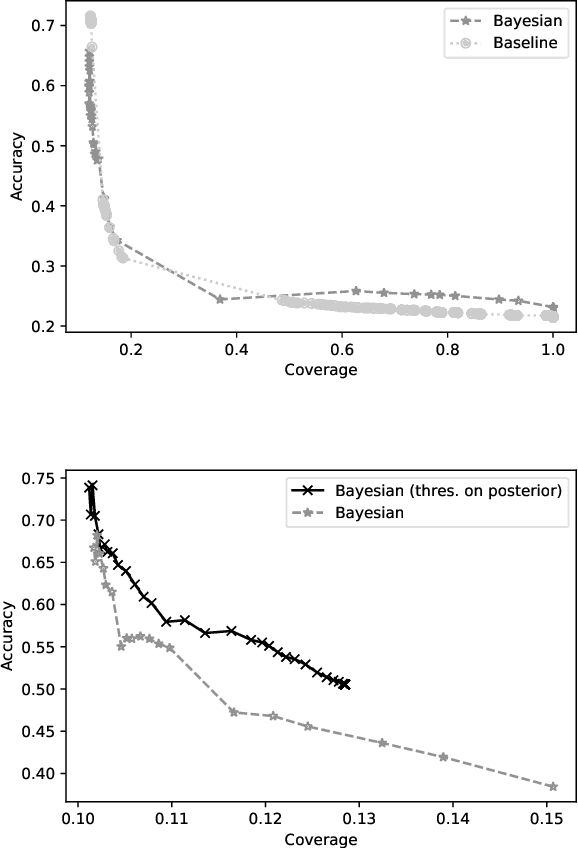
We introduce a hierarchical Bayesian approach to tackle the challenging problem of size recommendation in e-commerce fashion. Our approach jointly models a size purchased by a customer, and its possible return event: 1. no return, 2. returned too small 3. returned too big. Those events are drawn following a multinomial distribution parameterized on the joint probability of each event, built following a hierarchy combining priors. Such a model allows us to incorporate extended domain expertise and article characteristics as prior knowledge, which in turn makes it possible for the underlying parameters to emerge thanks to sufficient data. Experiments are presented on real (anonymized) data from millions of customers along with a detailed discussion on the efficiency of such an approach within a large scale production system.
A Deep Learning System for Predicting Size and Fit in Fashion E-Commerce
Jul 23, 2019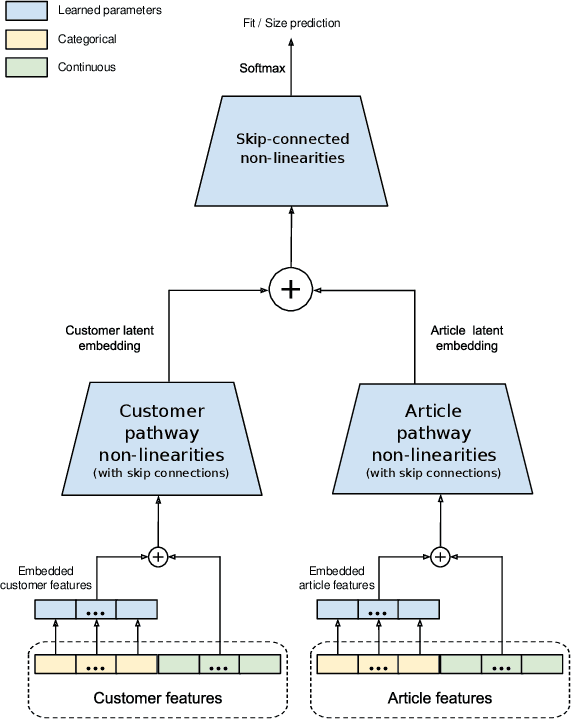
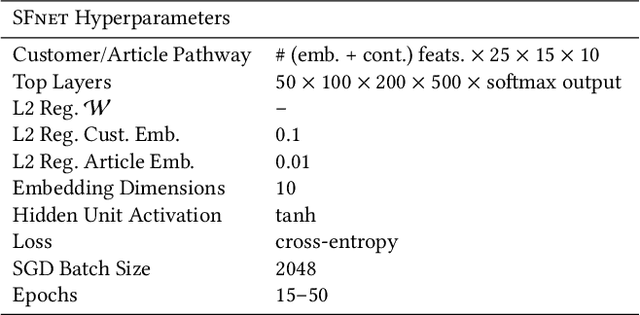
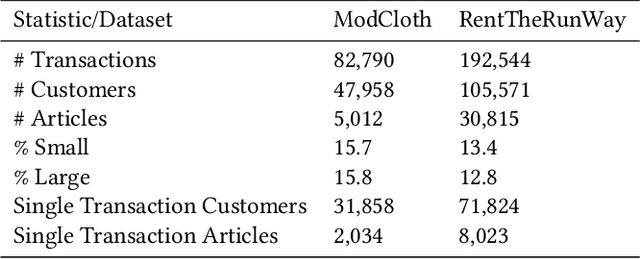
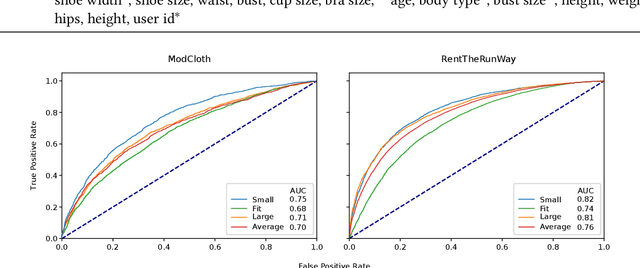
Personalized size and fit recommendations bear crucial significance for any fashion e-commerce platform. Predicting the correct fit drives customer satisfaction and benefits the business by reducing costs incurred due to size-related returns. Traditional collaborative filtering algorithms seek to model customer preferences based on their previous orders. A typical challenge for such methods stems from extreme sparsity of customer-article orders. To alleviate this problem, we propose a deep learning based content-collaborative methodology for personalized size and fit recommendation. Our proposed method can ingest arbitrary customer and article data and can model multiple individuals or intents behind a single account. The method optimizes a global set of parameters to learn population-level abstractions of size and fit relevant information from observed customer-article interactions. It further employs customer and article specific embedding variables to learn their properties. Together with learned entity embeddings, the method maps additional customer and article attributes into a latent space to derive personalized recommendations. Application of our method to two publicly available datasets demonstrate an improvement over the state-of-the-art published results. On two proprietary datasets, one containing fit feedback from fashion experts and the other involving customer purchases, we further outperform comparable methodologies, including a recent Bayesian approach for size recommendation.
A Bandit Framework for Optimal Selection of Reinforcement Learning Agents
Feb 10, 2019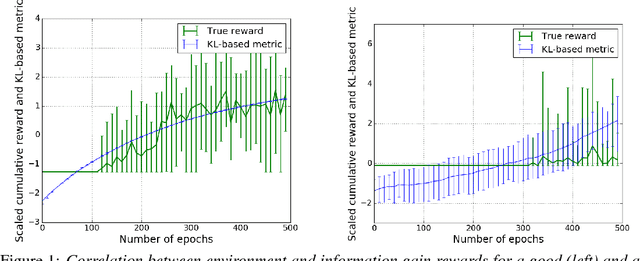
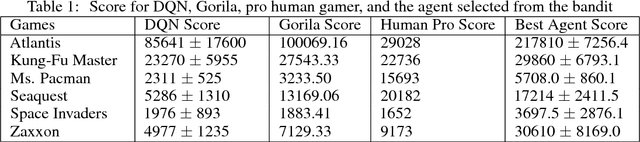
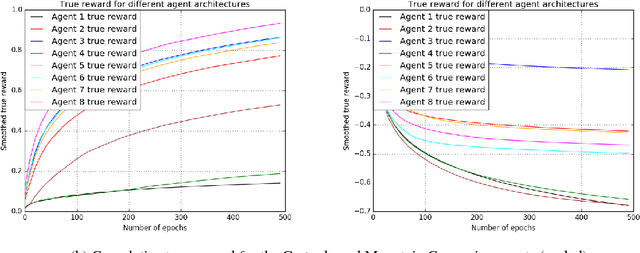
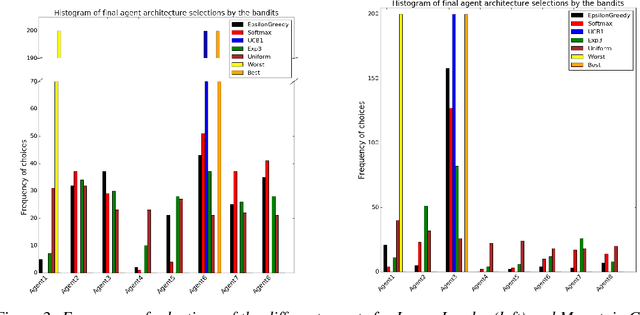
Deep Reinforcement Learning has been shown to be very successful in complex games, e.g. Atari or Go. These games have clearly defined rules, and hence allow simulation. In many practical applications, however, interactions with the environment are costly and a good simulator of the environment is not available. Further, as environments differ by application, the optimal inductive bias (architecture, hyperparameters, etc.) of a reinforcement agent depends on the application. In this work, we propose a multi-arm bandit framework that selects from a set of different reinforcement learning agents to choose the one with the best inductive bias. To alleviate the problem of sparse rewards, the reinforcement learning agents are augmented with surrogate rewards. This helps the bandit framework to select the best agents early, since these rewards are smoother and less sparse than the environment reward. The bandit has the double objective of maximizing the reward while the agents are learning and selecting the best agent after a finite number of learning steps. Our experimental results on standard environments show that the proposed framework is able to consistently select the optimal agent after a finite number of steps, while collecting more cumulative reward compared to selecting a sub-optimal architecture or uniformly alternating between different agents.
Copy the Old or Paint Anew? An Adversarial Framework for Parametric Image Stylization
Nov 22, 2018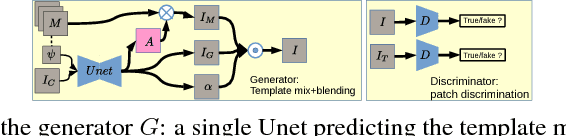



Parametric generative deep models are state-of-the-art for photo and non-photo realistic image stylization. However, learning complicated image representations requires compute-intense models parametrized by a huge number of weights, which in turn requires large datasets to make learning successful. Non-parametric exemplar-based generation is a technique that works well to reproduce style from small datasets, but is also compute-intensive. These aspects are a drawback for the practice of digital AI artists: typically one wants to use a small set of stylization images, and needs a fast flexible model in order to experiment with it. With this motivation, our work has these contributions: (i) a novel stylization method called Fully Adversarial Mosaics (FAMOS) that combines the strengths of both parametric and non-parametric approaches; (ii) multiple ablations and image examples that analyze the method and show its capabilities; (iii) source code that will empower artists and machine learning researchers to use and modify FAMOS.