 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransform the Set: Memory Attentive Generation of Guided and Unguided Image Collages
Paper and Code
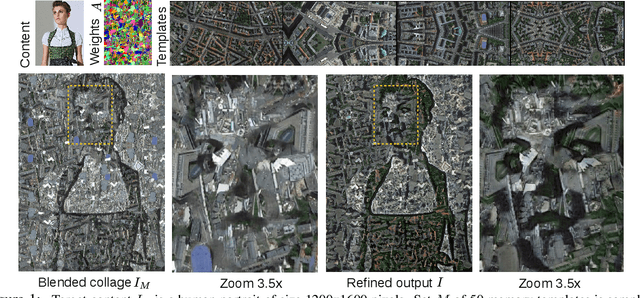

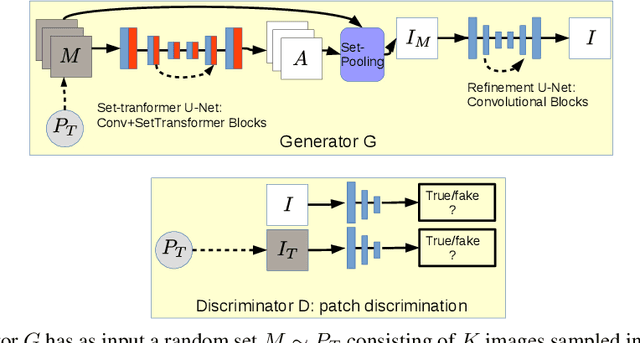
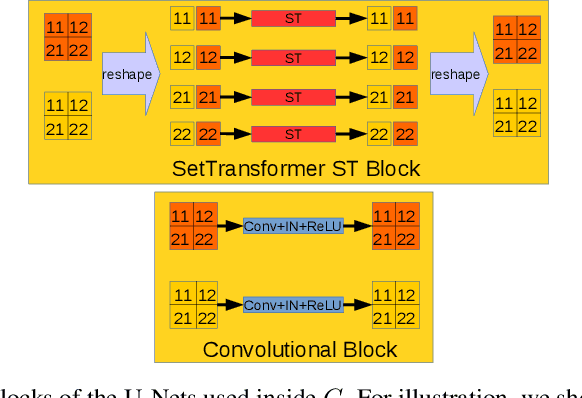
Cutting and pasting image segments feels intuitive: the choice of source templates gives artists flexibility in recombining existing source material. Formally, this process takes an image set as input and outputs a collage of the set elements. Such selection from sets of source templates does not fit easily in classical convolutional neural models requiring inputs of fixed size. Inspired by advances in attention and set-input machine learning, we present a novel architecture that can generate in one forward pass image collages of source templates using set-structured representations. This paper has the following contributions: (i) a novel framework for image generation called Memory Attentive Generation of Image Collages (MAGIC) which gives artists new ways to create digital collages; (ii) from the machine-learning perspective, we show a novel Generative Adversarial Networks (GAN) architecture that uses Set-Transformer layers and set-pooling to blend sets of random image samples - a hybrid non-parametric approach.