 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight-Field Dataset for Disparity Based Depth Estimation
Nov 08, 2025A Light Field (LF) camera consists of an additional two-dimensional array of micro-lenses placed between the main lens and sensor, compared to a conventional camera. The sensor pixels under each micro-lens receive light from a sub-aperture of the main lens. This enables the image sensor to capture both spatial information and the angular resolution of a scene point. This additional angular information is used to estimate the depth of a 3-D scene. The continuum of virtual viewpoints in light field data enables efficient depth estimation using Epipolar Line Images (EPIs) with robust occlusion handling. However, the trade-off between angular information and spatial information is very critical and depends on the focal position of the camera. To design, develop, implement, and test novel disparity-based light field depth estimation algorithms, the availability of suitable light field image datasets is essential. In this paper, a publicly available light field image dataset is introduced and thoroughly described. We have also demonstrated the effect of focal position on the disparity of a 3-D point as well as the shortcomings of the currently available light field dataset. The proposed dataset contains 285 light field images captured using a Lytro Illum LF camera and 13 synthetic LF images. The proposed dataset also comprises a synthetic dataset with similar disparity characteristics to those of a real light field camera. A real and synthetic stereo light field dataset is also created by using a mechanical gantry system and Blender. The dataset is available at https://github.com/aupendu/light-field-dataset.
Sharing the Learned Knowledge-base to Estimate Convolutional Filter Parameters for Continual Image Restoration
Nov 07, 2025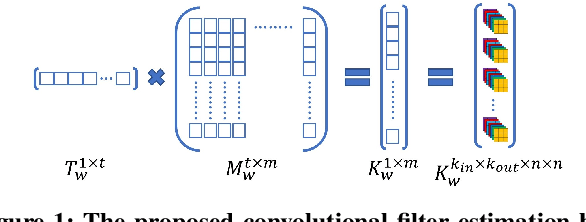
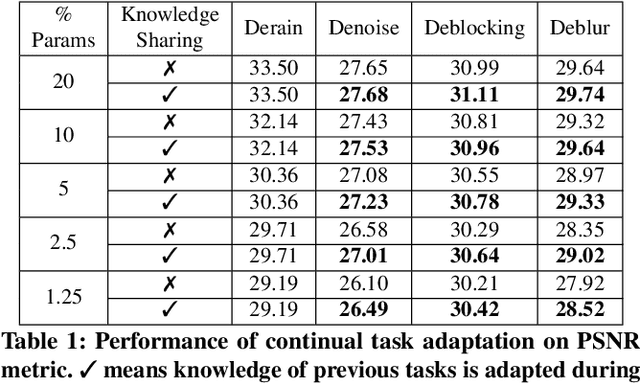
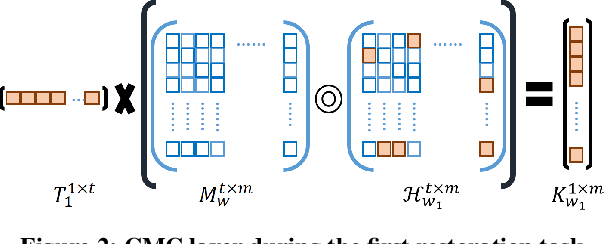
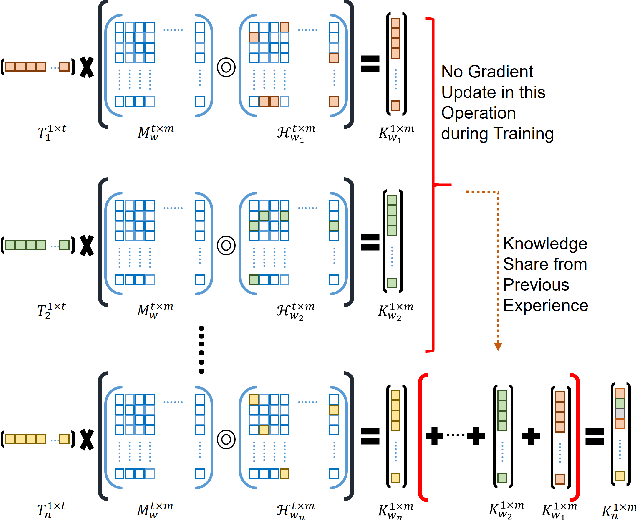
Continual learning is an emerging topic in the field of deep learning, where a model is expected to learn continuously for new upcoming tasks without forgetting previous experiences. This field has witnessed numerous advancements, but few works have been attempted in the direction of image restoration. Handling large image sizes and the divergent nature of various degradation poses a unique challenge in the restoration domain. However, existing works require heavily engineered architectural modifications for new task adaptation, resulting in significant computational overhead. Regularization-based methods are unsuitable for restoration, as different restoration challenges require different kinds of feature processing. In this direction, we propose a simple modification of the convolution layer to adapt the knowledge from previous restoration tasks without touching the main backbone architecture. Therefore, it can be seamlessly applied to any deep architecture without any structural modifications. Unlike other approaches, we demonstrate that our model can increase the number of trainable parameters without significantly increasing computational overhead or inference time. Experimental validation demonstrates that new restoration tasks can be introduced without compromising the performance of existing tasks. We also show that performance on new restoration tasks improves by adapting the knowledge from the knowledge base created by previous restoration tasks. The code is available at https://github.com/aupendu/continual-restore.
Sub-Aperture Feature Adaptation in Single Image Super-resolution Model for Light Field Imaging
Jul 26, 2022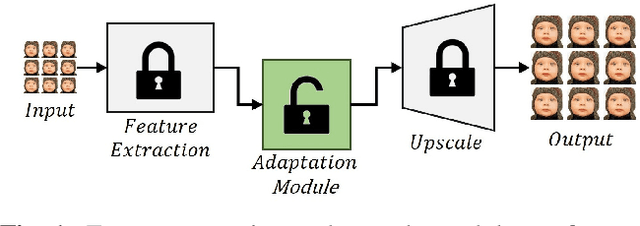
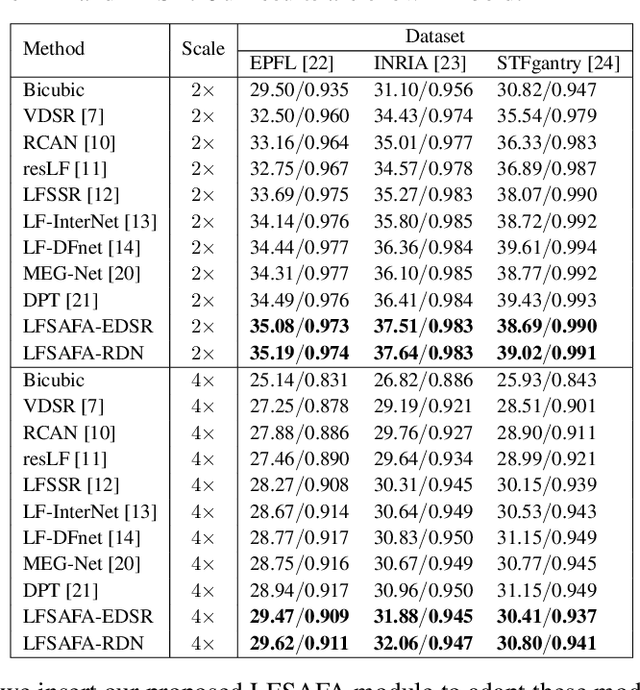
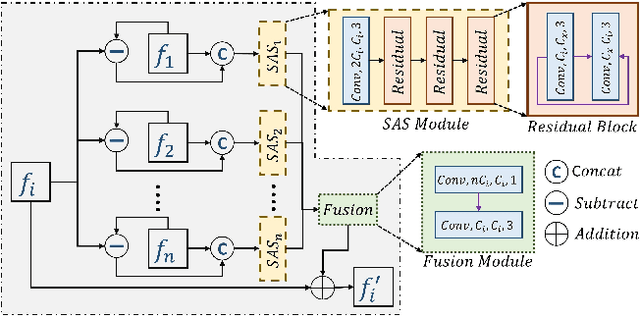
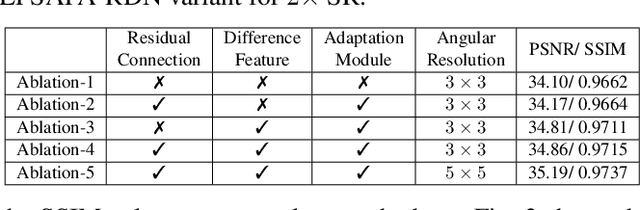
With the availability of commercial Light Field (LF) cameras, LF imaging has emerged as an up and coming technology in computational photography. However, the spatial resolution is significantly constrained in commercial microlens based LF cameras because of the inherent multiplexing of spatial and angular information. Therefore, it becomes the main bottleneck for other applications of light field cameras. This paper proposes an adaptation module in a pretrained Single Image Super Resolution (SISR) network to leverage the powerful SISR model instead of using highly engineered light field imaging domain specific Super Resolution models. The adaption module consists of a Sub aperture Shift block and a fusion block. It is an adaptation in the SISR network to further exploit the spatial and angular information in LF images to improve the super resolution performance. Experimental validation shows that the proposed method outperforms existing light field super resolution algorithms. It also achieves PSNR gains of more than 1 dB across all the datasets as compared to the same pretrained SISR models for scale factor 2, and PSNR gains 0.6 to 1 dB for scale factor 4.
Transmission Map and Atmospheric Light Guided Iterative Updater Network for Single Image Dehazing
Aug 04, 2020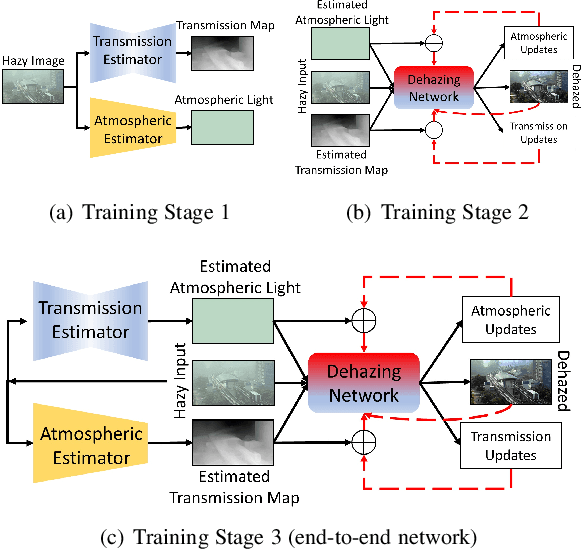



Hazy images obscure content visibility and hinder several subsequent computer vision tasks. For dehazing in a wide variety of hazy conditions, an end-to-end deep network jointly estimating the dehazed image along with suitable transmission map and atmospheric light for guidance could prove effective. To this end, we propose an Iterative Prior Updated Dehazing Network (IPUDN) based on a novel iterative update framework. We present a novel convolutional architecture to estimate channel-wise atmospheric light, which along with an estimated transmission map are used as priors for the dehazing network. Use of channel-wise atmospheric light allows our network to handle color casts in hazy images. In our IPUDN, the transmission map and atmospheric light estimates are updated iteratively using corresponding novel updater networks. The iterative mechanism is leveraged to gradually modify the estimates toward those appropriately representing the hazy condition. These updates occur jointly with the iterative estimation of the dehazed image using a convolutional neural network with LSTM driven recurrence, which introduces inter-iteration dependencies. Our approach is qualitatively and quantitatively found effective for synthetic and real-world hazy images depicting varied hazy conditions, and it outperforms the state-of-the-art. Thorough analyses of IPUDN through additional experiments and detailed ablation studies are also presented.
Fast Bayesian Uncertainty Estimation of Batch Normalized Single Image Super-Resolution Network
Mar 22, 2019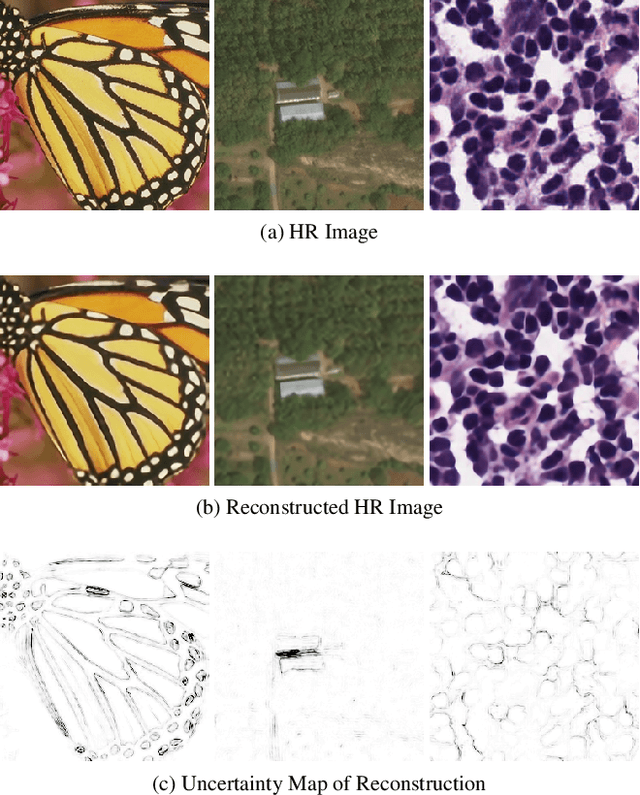

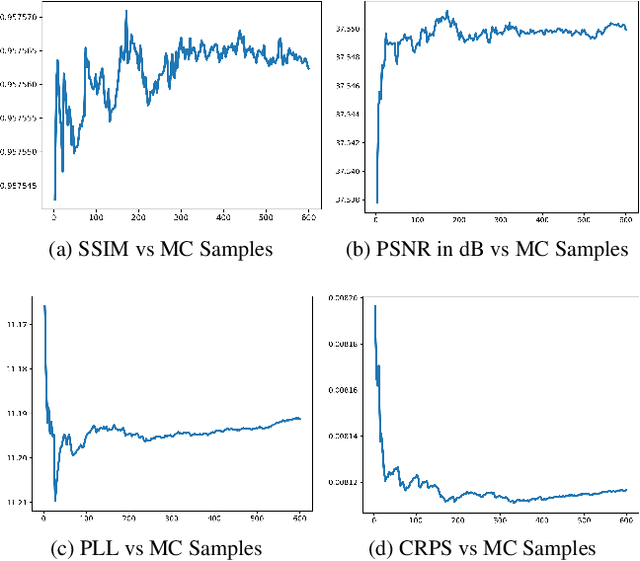
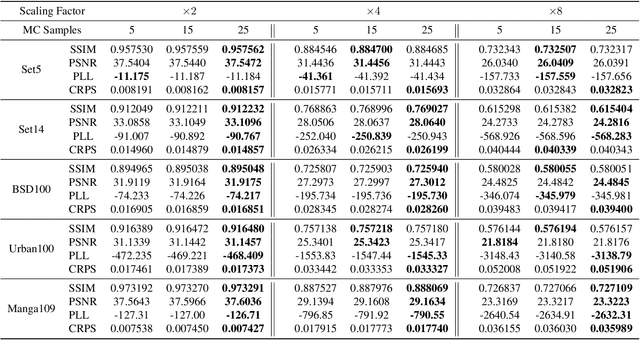
In recent years, deep convolutional neural network (CNN) has achieved unprecedented success in image super-resolution (SR) task. But the black-box nature of the neural network and due to its lack of transparency, it is hard to trust the outcome. In this regards, we introduce a Bayesian approach for uncertainty estimation in super-resolution network. We generate Monte Carlo (MC) samples from a posterior distribution by using batch mean and variance as a stochastic parameter in the batch-normalization layer during test time. Those MC samples not only reconstruct the image from its low-resolution counterpart but also provides a confidence map of reconstruction which will be very impactful for practical use. We also introduce a faster approach for estimating the uncertainty, and it can be useful for real-time applications. We validate our results using standard datasets for performance analysis and also for different domain-specific super-resolution task. We also estimate uncertainty quality using standard statistical metrics and also provides a qualitative evaluation of uncertainty for SR applications.
UltraCompression: Framework for High Density Compression of Ultrasound Volumes using Physics Modeling Deep Neural Networks
Jan 17, 2019



Ultrasound image compression by preserving speckle-based key information is a challenging task. In this paper, we introduce an ultrasound image compression framework with the ability to retain realism of speckle appearance despite achieving very high-density compression factors. The compressor employs a tissue segmentation method, transmitting segments along with transducer frequency, number of samples and image size as essential information required for decompression. The decompressor is based on a convolutional network trained to generate patho-realistic ultrasound images which convey essential information pertinent to tissue pathology visible in the images. We demonstrate generalizability of the building blocks using two variants to build the compressor. We have evaluated the quality of decompressed images using distortion losses as well as perception loss and compared it with other off the shelf solutions. The proposed method achieves a compression ratio of $725:1$ while preserving the statistical distribution of speckles. This enables image segmentation on decompressed images to achieve dice score of $0.89 \pm 0.11$, which evidently is not so accurately achievable when images are compressed with current standards like JPEG, JPEG 2000, WebP and BPG. We envision this frame work to serve as a roadmap for speckle image compression standards.
Fully Convolutional Model for Variable Bit Length and Lossy High Density Compression of Mammograms
May 17, 2018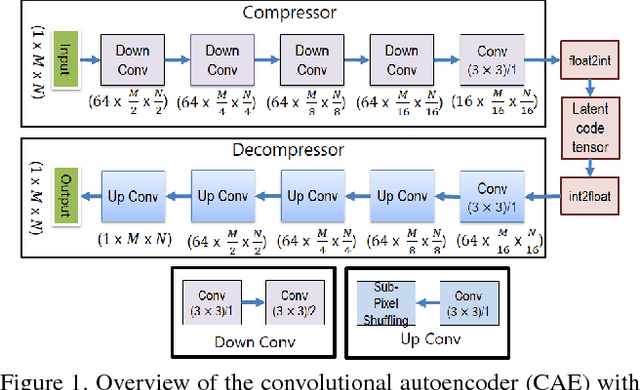
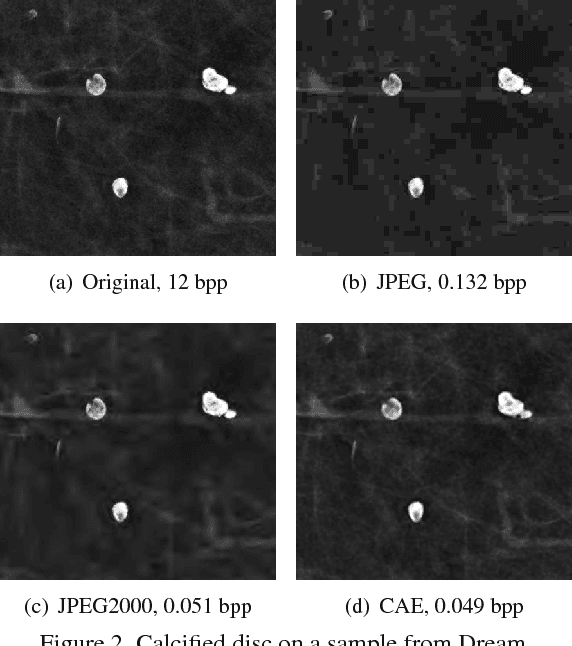
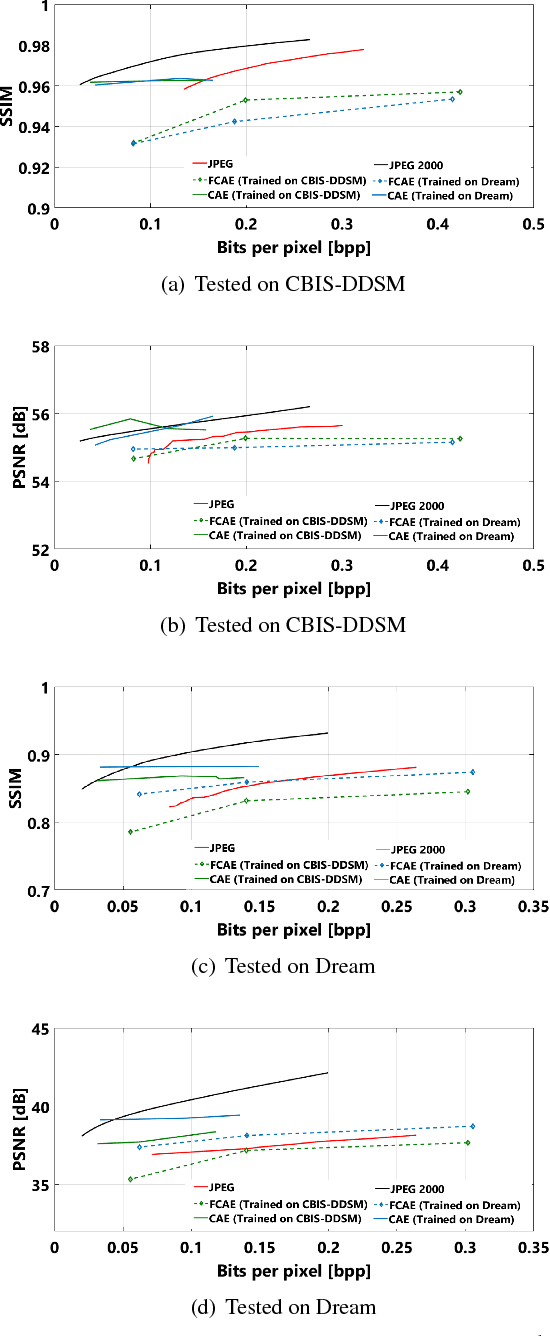
Early works on medical image compression date to the 1980's with the impetus on deployment of teleradiology systems for high-resolution digital X-ray detectors. Commercially deployed systems during the period could compress 4,096 x 4,096 sized images at 12 bpp to 2 bpp using lossless arithmetic coding, and over the years JPEG and JPEG2000 were imbibed reaching upto 0.1 bpp. Inspired by the reprise of deep learning based compression for natural images over the last two years, we propose a fully convolutional autoencoder for diagnostically relevant feature preserving lossy compression. This is followed by leveraging arithmetic coding for encapsulating high redundancy of features for further high-density code packing leading to variable bit length. We demonstrate performance on two different publicly available digital mammography datasets using peak signal-to-noise ratio (pSNR), structural similarity (SSIM) index and domain adaptability tests between datasets. At high density compression factors of >300x (~0.04 bpp), our approach rivals JPEG and JPEG2000 as evaluated through a Radiologist's visual Turing test.