 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Universe Learning Itself: On the Evolution of Dynamics from the Big Bang to Machine Intelligence
Dec 21, 2025We develop a unified, dynamical-systems narrative of the universe that traces a continuous chain of structure formation from the Big Bang to contemporary human societies and their artificial learning systems. Rather than treating cosmology, astrophysics, geophysics, biology, cognition, and machine intelligence as disjoint domains, we view each as successive regimes of dynamics on ever-richer state spaces, stitched together by phase transitions, symmetry-breaking events, and emergent attractors. Starting from inflationary field dynamics and the growth of primordial perturbations, we describe how gravitational instability sculpts the cosmic web, how dissipative collapse in baryonic matter yields stars and planets, and how planetary-scale geochemical cycles define long-lived nonequilibrium attractors. Within these attractors, we frame the origin of life as the emergence of self-maintaining reaction networks, evolutionary biology as flow on high-dimensional genotype-phenotype-environment manifolds, and brains as adaptive dynamical systems operating near critical surfaces. Human culture and technology-including modern machine learning and artificial intelligence-are then interpreted as symbolic and institutional dynamics that implement and refine engineered learning flows which recursively reshape their own phase space. Throughout, we emphasize recurring mathematical motifs-instability, bifurcation, multiscale coupling, and constrained flows on measure-zero subsets of the accessible state space. Our aim is not to present any new cosmological or biological model, but a cross-scale, theoretical perspective: a way of reading the universe's history as the evolution of dynamics itself, culminating (so far) in biological and artificial systems capable of modeling, predicting, and deliberately perturbing their own future trajectories.
Echo State Networks as State-Space Models: A Systems Perspective
Sep 04, 2025Echo State Networks (ESNs) are typically presented as efficient, readout-trained recurrent models, yet their dynamics and design are often guided by heuristics rather than first principles. We recast ESNs explicitly as state-space models (SSMs), providing a unified systems-theoretic account that links reservoir computing with classical identification and modern kernelized SSMs. First, we show that the echo-state property is an instance of input-to-state stability for a contractive nonlinear SSM and derive verifiable conditions in terms of leak, spectral scaling, and activation Lipschitz constants. Second, we develop two complementary mappings: (i) small-signal linearizations that yield locally valid LTI SSMs with interpretable poles and memory horizons; and (ii) lifted/Koopman random-feature expansions that render the ESN a linear SSM in an augmented state, enabling transfer-function and convolutional-kernel analyses. This perspective yields frequency-domain characterizations of memory spectra and clarifies when ESNs emulate structured SSM kernels. Third, we cast teacher forcing as state estimation and propose Kalman/EKF-assisted readout learning, together with EM for hyperparameters (leak, spectral radius, process/measurement noise) and a hybrid subspace procedure for spectral shaping under contraction constraints.
HypER: Hyperbolic Echo State Networks for Capturing Stretch-and-Fold Dynamics in Chaotic Flows
Aug 25, 2025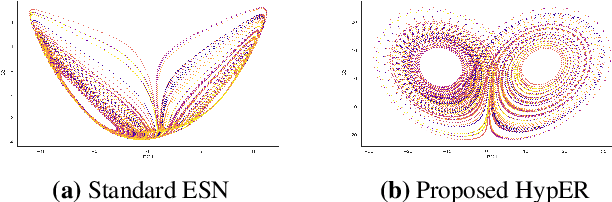
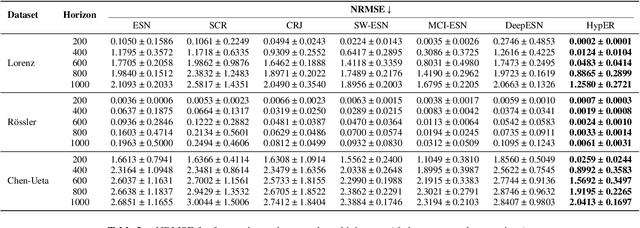
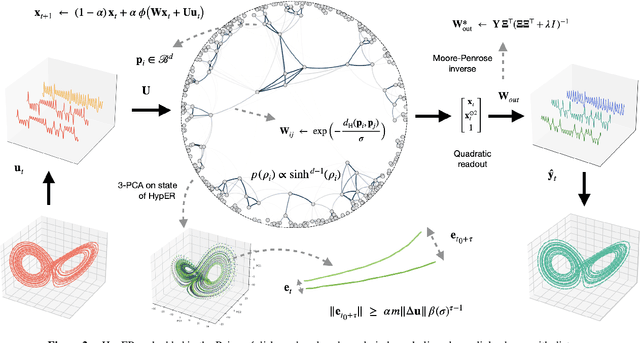
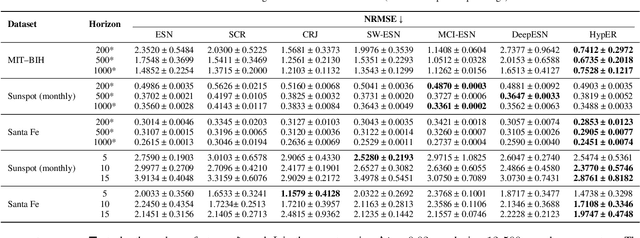
Forecasting chaotic dynamics beyond a few Lyapunov times is difficult because infinitesimal errors grow exponentially. Existing Echo State Networks (ESNs) mitigate this growth but employ reservoirs whose Euclidean geometry is mismatched to the stretch-and-fold structure of chaos. We introduce the Hyperbolic Embedding Reservoir (HypER), an ESN whose neurons are sampled in the Poincare ball and whose connections decay exponentially with hyperbolic distance. This negative-curvature construction embeds an exponential metric directly into the latent space, aligning the reservoir's local expansion-contraction spectrum with the system's Lyapunov directions while preserving standard ESN features such as sparsity, leaky integration, and spectral-radius control. Training is limited to a Tikhonov-regularized readout. On the chaotic Lorenz-63 and Roessler systems, and the hyperchaotic Chen-Ueta attractor, HypER consistently lengthens the mean valid-prediction horizon beyond Euclidean and graph-structured ESN baselines, with statistically significant gains confirmed over 30 independent runs; parallel results on real-world benchmarks, including heart-rate variability from the Santa Fe and MIT-BIH datasets and international sunspot numbers, corroborate its advantage. We further establish a lower bound on the rate of state divergence for HypER, mirroring Lyapunov growth.
Frozen in Time: Parameter-Efficient Time Series Transformers via Reservoir-Induced Feature Expansion and Fixed Random Dynamics
Aug 25, 2025Transformers are the de-facto choice for sequence modelling, yet their quadratic self-attention and weak temporal bias can make long-range forecasting both expensive and brittle. We introduce FreezeTST, a lightweight hybrid that interleaves frozen random-feature (reservoir) blocks with standard trainable Transformer layers. The frozen blocks endow the network with rich nonlinear memory at no optimisation cost; the trainable layers learn to query this memory through self-attention. The design cuts trainable parameters and also lowers wall-clock training time, while leaving inference complexity unchanged. On seven standard long-term forecasting benchmarks, FreezeTST consistently matches or surpasses specialised variants such as Informer, Autoformer, and PatchTST; with substantially lower compute. Our results show that embedding reservoir principles within Transformers offers a simple, principled route to efficient long-term time-series prediction.
Dynamics and Computational Principles of Echo State Networks: A Mathematical Perspective
Apr 16, 2025Reservoir computing (RC) represents a class of state-space models (SSMs) characterized by a fixed state transition mechanism (the reservoir) and a flexible readout layer that maps from the state space. It is a paradigm of computational dynamical systems that harnesses the transient dynamics of high-dimensional state spaces for efficient processing of temporal data. Rooted in concepts from recurrent neural networks, RC achieves exceptional computational power by decoupling the training of the dynamic reservoir from the linear readout layer, thereby circumventing the complexities of gradient-based optimization. This work presents a systematic exploration of RC, addressing its foundational properties such as the echo state property, fading memory, and reservoir capacity through the lens of dynamical systems theory. We formalize the interplay between input signals and reservoir states, demonstrating the conditions under which reservoirs exhibit stability and expressive power. Further, we delve into the computational trade-offs and robustness characteristics of RC architectures, extending the discussion to their applications in signal processing, time-series prediction, and control systems. The analysis is complemented by theoretical insights into optimization, training methodologies, and scalability, highlighting open challenges and potential directions for advancing the theoretical underpinnings of RC.
Capsule Vision 2024 Challenge: Multi-Class Abnormality Classification for Video Capsule Endoscopy
Aug 09, 2024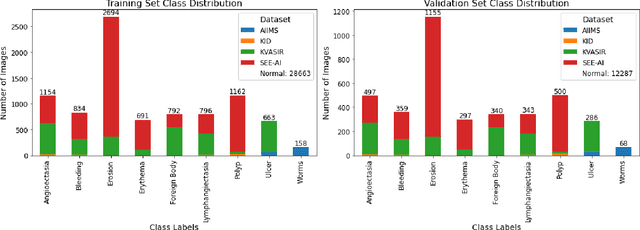
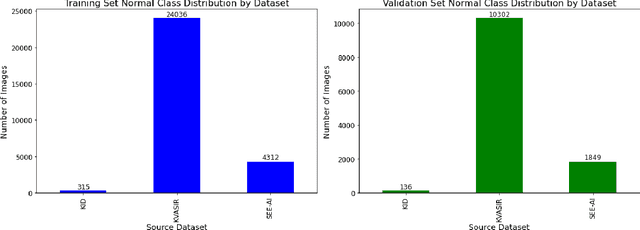
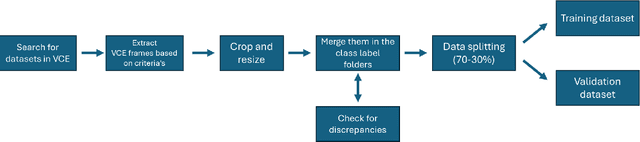

We present the Capsule Vision 2024 Challenge: Multi-Class Abnormality Classification for Video Capsule Endoscopy. It is being virtually organized by the Research Center for Medical Image Analysis and Artificial Intelligence (MIAAI), Department of Medicine, Danube Private University, Krems, Austria and Medical Imaging and Signal Analysis Hub (MISAHUB) in collaboration with the 9th International Conference on Computer Vision & Image Processing (CVIP 2024) being organized by the Indian Institute of Information Technology, Design and Manufacturing (IIITDM) Kancheepuram, Chennai, India. This document describes the overview of the challenge, its registration and rules, submission format, and the description of the utilized datasets.
Biasing & Debiasing based Approach Towards Fair Knowledge Transfer for Equitable Skin Analysis
May 16, 2024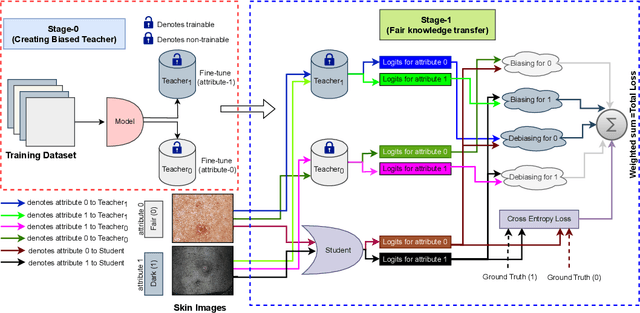
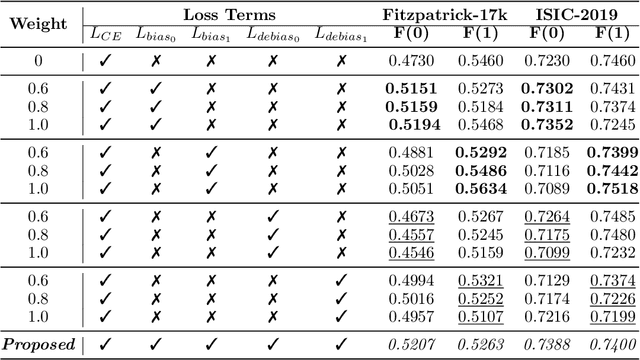
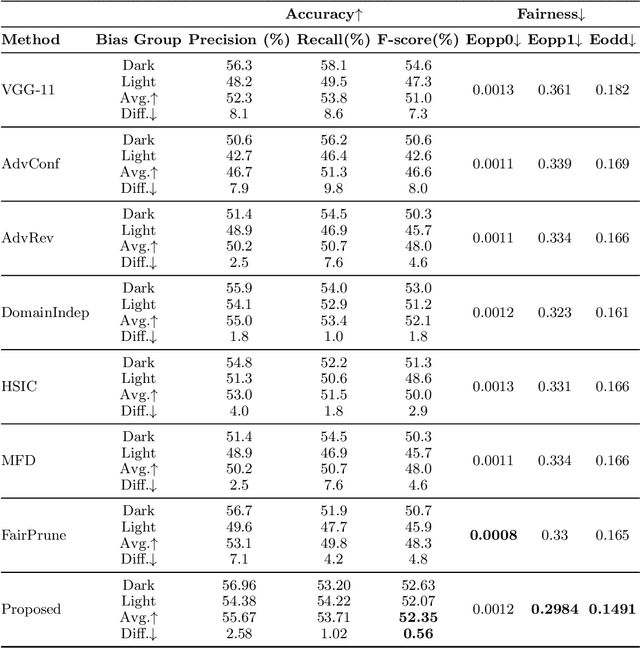
Deep learning models, particularly Convolutional Neural Networks (CNNs), have demonstrated exceptional performance in diagnosing skin diseases, often outperforming dermatologists. However, they have also unveiled biases linked to specific demographic traits, notably concerning diverse skin tones or gender, prompting concerns regarding fairness and limiting their widespread deployment. Researchers are actively working to ensure fairness in AI-based solutions, but existing methods incur an accuracy loss when striving for fairness. To solve this issue, we propose a `two-biased teachers' (i.e., biased on different sensitive attributes) based approach to transfer fair knowledge into the student network. Our approach mitigates biases present in the student network without harming its predictive accuracy. In fact, in most cases, our approach improves the accuracy of the baseline model. To achieve this goal, we developed a weighted loss function comprising biasing and debiasing loss terms. We surpassed available state-of-the-art approaches to attain fairness and also improved the accuracy at the same time. The proposed approach has been evaluated and validated on two dermatology datasets using standard accuracy and fairness evaluation measures. We will make source code publicly available to foster reproducibility and future research.
SOFIM: Stochastic Optimization Using Regularized Fisher Information Matrix
Mar 05, 2024



This paper introduces a new stochastic optimization method based on the regularized Fisher information matrix (FIM), named SOFIM, which can efficiently utilize the FIM to approximate the Hessian matrix for finding Newton's gradient update in large-scale stochastic optimization of machine learning models. It can be viewed as a variant of natural gradient descent (NGD), where the challenge of storing and calculating the full FIM is addressed through making use of the regularized FIM and directly finding the gradient update direction via Sherman-Morrison matrix inversion. Additionally, like the popular Adam method, SOFIM uses the first moment of the gradient to address the issue of non-stationary objectives across mini-batches due to heterogeneous data. The utilization of the regularized FIM and Sherman-Morrison matrix inversion leads to the improved convergence rate with the same space and time complexities as stochastic gradient descent (SGD) with momentum. The extensive experiments on training deep learning models on several benchmark image classification datasets demonstrate that the proposed SOFIM outperforms SGD with momentum and several state-of-the-art Newton optimization methods, such as Nystrom-SGD, L-BFGS, and AdaHessian, in term of the convergence speed for achieving the pre-specified objectives of training and test losses as well as test accuracy.
Synthesizing Sentiment-Controlled Feedback For Multimodal Text and Image Data
Feb 12, 2024The ability to generate sentiment-controlled feedback in response to multimodal inputs, comprising both text and images, addresses a critical gap in human-computer interaction by enabling systems to provide empathetic, accurate, and engaging responses. This capability has profound applications in healthcare, marketing, and education. To this end, we construct a large-scale Controllable Multimodal Feedback Synthesis (CMFeed) dataset and propose a controllable feedback synthesis system. The proposed system includes an encoder, decoder, and controllability block for textual and visual inputs. It extracts textual and visual features using a transformer and Faster R-CNN networks and combines them to generate feedback. The CMFeed dataset encompasses images, text, reactions to the post, human comments with relevance scores, and reactions to the comments. The reactions to the post and comments are utilized to train the proposed model to produce feedback with a particular (positive or negative) sentiment. A sentiment classification accuracy of 77.23% has been achieved, 18.82% higher than the accuracy without using the controllability. Moreover, the system incorporates a similarity module for assessing feedback relevance through rank-based metrics. It implements an interpretability technique to analyze the contribution of textual and visual features during the generation of uncontrolled and controlled feedback.
DeepMediX: A Deep Learning-Driven Resource-Efficient Medical Diagnosis Across the Spectrum
Jul 01, 2023



In the rapidly evolving landscape of medical imaging diagnostics, achieving high accuracy while preserving computational efficiency remains a formidable challenge. This work presents \texttt{DeepMediX}, a groundbreaking, resource-efficient model that significantly addresses this challenge. Built on top of the MobileNetV2 architecture, DeepMediX excels in classifying brain MRI scans and skin cancer images, with superior performance demonstrated on both binary and multiclass skin cancer datasets. It provides a solution to labor-intensive manual processes, the need for large datasets, and complexities related to image properties. DeepMediX's design also includes the concept of Federated Learning, enabling a collaborative learning approach without compromising data privacy. This approach allows diverse healthcare institutions to benefit from shared learning experiences without the necessity of direct data access, enhancing the model's predictive power while preserving the privacy and integrity of sensitive patient data. Its low computational footprint makes DeepMediX suitable for deployment on handheld devices, offering potential for real-time diagnostic support. Through rigorous testing on standard datasets, including the ISIC2018 for dermatological research, DeepMediX demonstrates exceptional diagnostic capabilities, matching the performance of existing models on almost all tasks and even outperforming them in some cases. The findings of this study underline significant implications for the development and deployment of AI-based tools in medical imaging and their integration into point-of-care settings. The source code and models generated would be released at https://github.com/kishorebabun/DeepMediX.