 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Large Language Models Are Good Noise Handlers in Engagement Analysis
Nov 18, 2025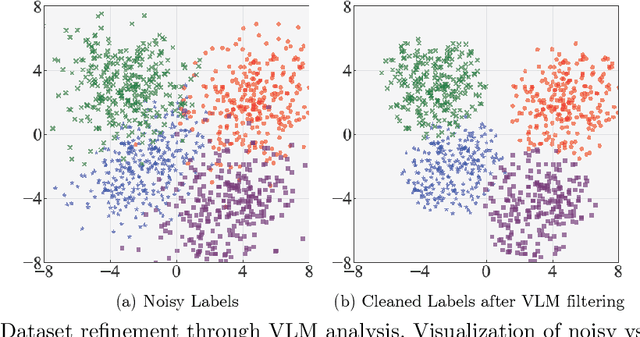
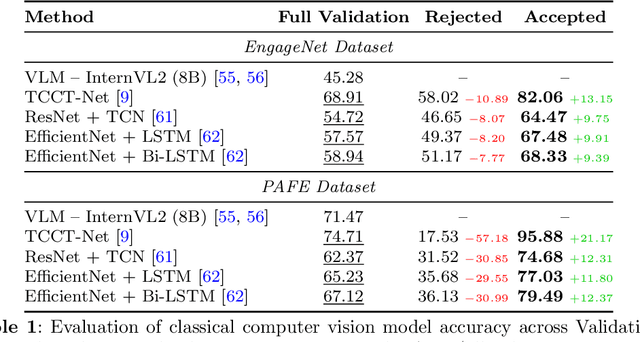
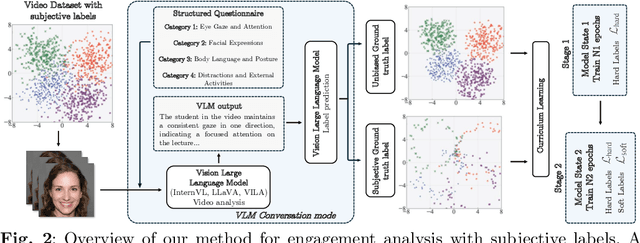
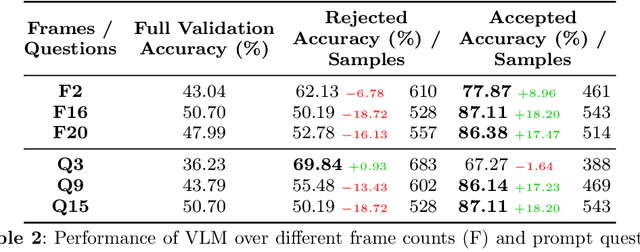
Engagement recognition in video datasets, unlike traditional image classification tasks, is particularly challenged by subjective labels and noise limiting model performance. To overcome the challenges of subjective and noisy engagement labels, we propose a framework leveraging Vision Large Language Models (VLMs) to refine annotations and guide the training process. Our framework uses a questionnaire to extract behavioral cues and split data into high- and low-reliability subsets. We also introduce a training strategy combining curriculum learning with soft label refinement, gradually incorporating ambiguous samples while adjusting supervision to reflect uncertainty. We demonstrate that classical computer vision models trained on refined high-reliability subsets and enhanced with our curriculum strategy show improvements, highlighting benefits of addressing label subjectivity with VLMs. This method surpasses prior state of the art across engagement benchmarks such as EngageNet (three of six feature settings, maximum improvement of +1.21%), and DREAMS / PAFE with F1 gains of +0.22 / +0.06.
VisioPhysioENet: Multimodal Engagement Detection using Visual and Physiological Signals
Sep 24, 2024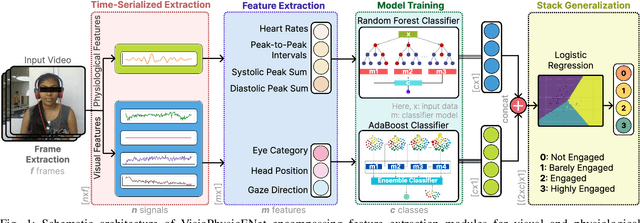
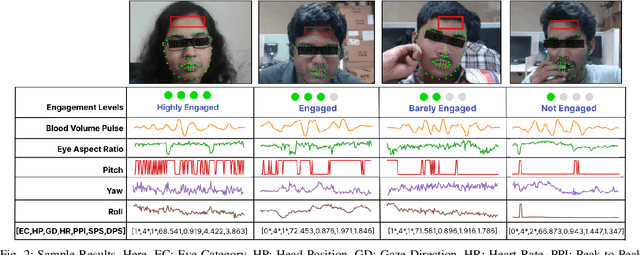


This paper presents VisioPhysioENet, a novel multimodal system that leverages visual cues and physiological signals to detect learner engagement. It employs a two-level approach for visual feature extraction using the Dlib library for facial landmark extraction and the OpenCV library for further estimations. This is complemented by extracting physiological signals using the plane-orthogonal-to-skin method to assess cardiovascular activity. These features are integrated using advanced machine learning classifiers, enhancing the detection of various engagement levels. We rigorously evaluate VisioPhysioENet on the DAiSEE dataset, where it achieves an accuracy of 63.09%, demonstrating a superior ability to discern various levels of engagement compared to existing methodologies. The proposed system's code can be accessed at https://github.com/MIntelligence-Group/VisioPhysioENet.
TCCT-Net: Two-Stream Network Architecture for Fast and Efficient Engagement Estimation via Behavioral Feature Signals
Apr 15, 2024Engagement analysis finds various applications in healthcare, education, advertisement, services. Deep Neural Networks, used for analysis, possess complex architecture and need large amounts of input data, computational power, inference time. These constraints challenge embedding systems into devices for real-time use. To address these limitations, we present a novel two-stream feature fusion "Tensor-Convolution and Convolution-Transformer Network" (TCCT-Net) architecture. To better learn the meaningful patterns in the temporal-spatial domain, we design a "CT" stream that integrates a hybrid convolutional-transformer. In parallel, to efficiently extract rich patterns from the temporal-frequency domain and boost processing speed, we introduce a "TC" stream that uses Continuous Wavelet Transform (CWT) to represent information in a 2D tensor form. Evaluated on the EngageNet dataset, the proposed method outperforms existing baselines, utilizing only two behavioral features (head pose rotations) compared to the 98 used in baseline models. Furthermore, comparative analysis shows TCCT-Net's architecture offers an order-of-magnitude improvement in inference speed compared to state-of-the-art image-based Recurrent Neural Network (RNN) methods. The code will be released at https://github.com/vedernikovphoto/TCCT_Net.
Measuring Non-Typical Emotions for Mental Health: A Survey of Computational Approaches
Mar 09, 2024
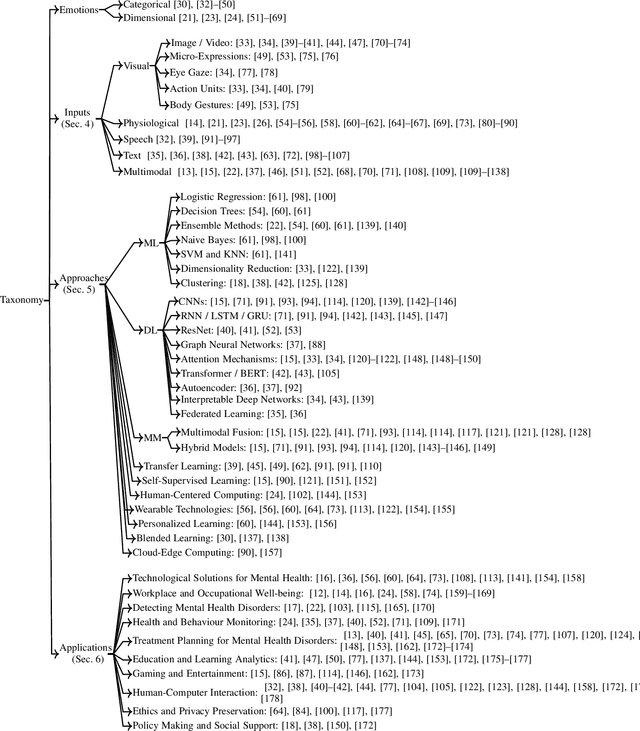
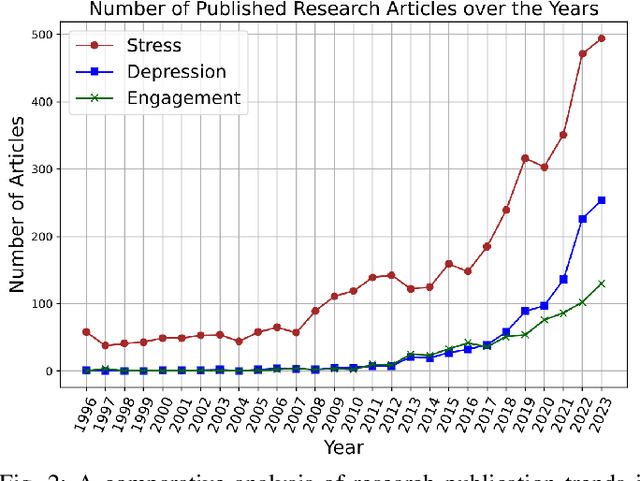
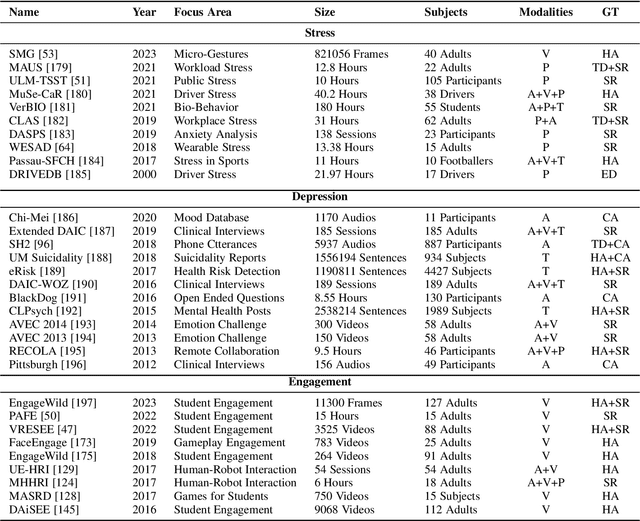
Analysis of non-typical emotions, such as stress, depression and engagement is less common and more complex compared to that of frequently discussed emotions like happiness, sadness, fear, and anger. The importance of these non-typical emotions has been increasingly recognized due to their implications on mental health and well-being. Stress and depression impact the engagement in daily tasks, highlighting the need to understand their interplay. This survey is the first to simultaneously explore computational methods for analyzing stress, depression, and engagement. We discuss the most commonly used datasets, input modalities, data processing techniques, and information fusion methods used for the computational analysis of stress, depression and engagement. A timeline and taxonomy of non-typical emotion analysis approaches along with their generic pipeline and categories are presented. Subsequently, we describe state-of-the-art computational approaches for non-typical emotion analysis, including a performance summary on the most commonly used datasets. Following this, we explore the applications, along with the associated challenges, limitations, and future research directions.
Synthesizing Sentiment-Controlled Feedback For Multimodal Text and Image Data
Feb 12, 2024The ability to generate sentiment-controlled feedback in response to multimodal inputs, comprising both text and images, addresses a critical gap in human-computer interaction by enabling systems to provide empathetic, accurate, and engaging responses. This capability has profound applications in healthcare, marketing, and education. To this end, we construct a large-scale Controllable Multimodal Feedback Synthesis (CMFeed) dataset and propose a controllable feedback synthesis system. The proposed system includes an encoder, decoder, and controllability block for textual and visual inputs. It extracts textual and visual features using a transformer and Faster R-CNN networks and combines them to generate feedback. The CMFeed dataset encompasses images, text, reactions to the post, human comments with relevance scores, and reactions to the comments. The reactions to the post and comments are utilized to train the proposed model to produce feedback with a particular (positive or negative) sentiment. A sentiment classification accuracy of 77.23% has been achieved, 18.82% higher than the accuracy without using the controllability. Moreover, the system incorporates a similarity module for assessing feedback relevance through rank-based metrics. It implements an interpretability technique to analyze the contribution of textual and visual features during the generation of uncontrolled and controlled feedback.
Interpretable Multimodal Emotion Recognition using Facial Features and Physiological Signals
Jun 05, 2023


This paper aims to demonstrate the importance and feasibility of fusing multimodal information for emotion recognition. It introduces a multimodal framework for emotion understanding by fusing the information from visual facial features and rPPG signals extracted from the input videos. An interpretability technique based on permutation feature importance analysis has also been implemented to compute the contributions of rPPG and visual modalities toward classifying a given input video into a particular emotion class. The experiments on IEMOCAP dataset demonstrate that the emotion classification performance improves by combining the complementary information from multiple modalities.
Interpretable Multimodal Emotion Recognition using Hybrid Fusion of Speech and Image Data
Aug 25, 2022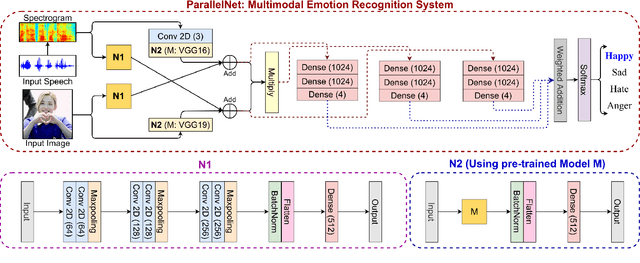
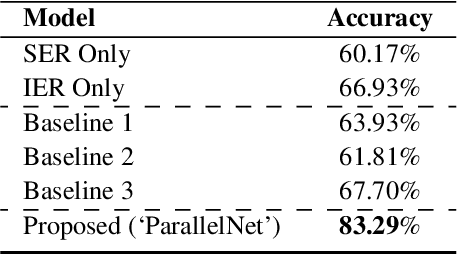
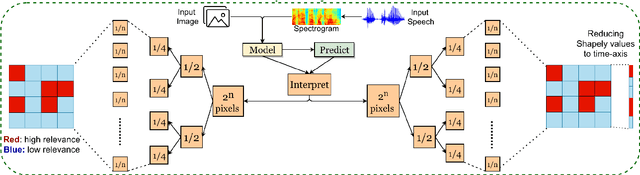

This paper proposes a multimodal emotion recognition system based on hybrid fusion that classifies the emotions depicted by speech utterances and corresponding images into discrete classes. A new interpretability technique has been developed to identify the important speech & image features leading to the prediction of particular emotion classes. The proposed system's architecture has been determined through intensive ablation studies. It fuses the speech & image features and then combines speech, image, and intermediate fusion outputs. The proposed interpretability technique incorporates the divide & conquer approach to compute shapely values denoting each speech & image feature's importance. We have also constructed a large-scale dataset (IIT-R SIER dataset), consisting of speech utterances, corresponding images, and class labels, i.e., 'anger,' 'happy,' 'hate,' and 'sad.' The proposed system has achieved 83.29% accuracy for emotion recognition. The enhanced performance of the proposed system advocates the importance of utilizing complementary information from multiple modalities for emotion recognition.
Hybrid Fusion Based Interpretable Multimodal Emotion Recognition with Insufficient Labelled Data
Aug 24, 2022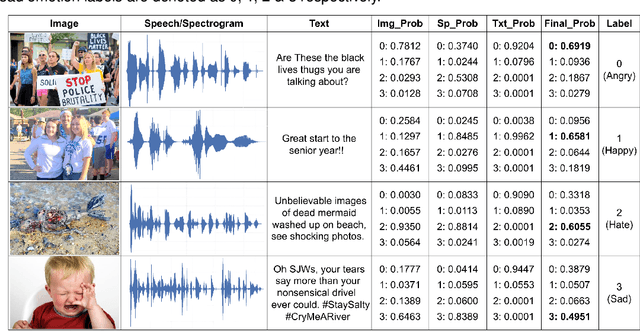
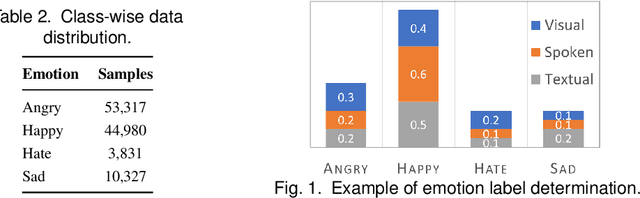
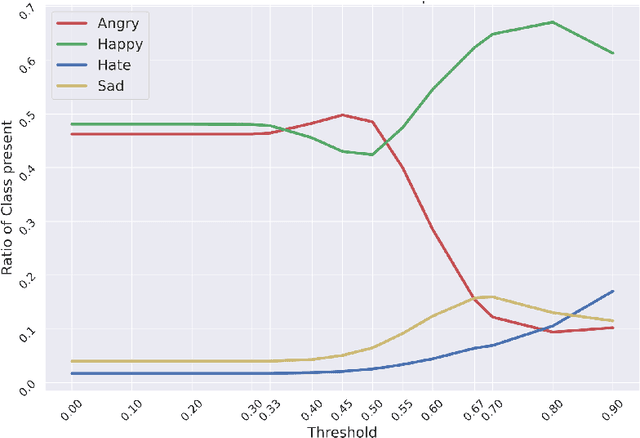
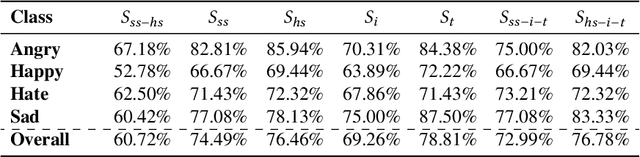
This paper proposes a multimodal emotion recognition system, VIsual Spoken Textual Additive Net (VISTA Net), to classify the emotions reflected by a multimodal input containing image, speech, and text into discrete classes. A new interpretability technique, K-Average Additive exPlanation (KAAP), has also been developed to identify the important visual, spoken, and textual features leading to predicting a particular emotion class. The VISTA Net fuses the information from image, speech & text modalities using a hybrid of early and late fusion. It automatically adjusts the weights of their intermediate outputs while computing the weighted average without human intervention. The KAAP technique computes the contribution of each modality and corresponding features toward predicting a particular emotion class. To mitigate the insufficiency of multimodal emotion datasets labeled with discrete emotion classes, we have constructed a large-scale IIT-R MMEmoRec dataset consisting of real-life images, corresponding speech & text, and emotion labels ('angry,' 'happy,' 'hate,' and 'sad.'). The VISTA Net has resulted in 95.99% emotion recognition accuracy on considering image, speech, and text modalities, which is better than the performance on considering the inputs of any one or two modalities.
Affective Feedback Synthesis Towards Multimodal Text and Image Data
Mar 31, 2022

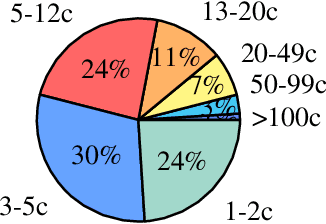
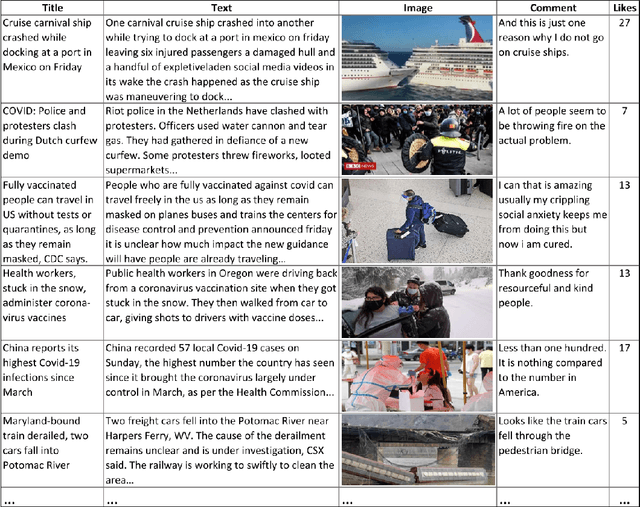
In this paper, we have defined a novel task of affective feedback synthesis that deals with generating feedback for input text & corresponding image in a similar way as humans respond towards the multimodal data. A feedback synthesis system has been proposed and trained using ground-truth human comments along with image-text input. We have also constructed a large-scale dataset consisting of image, text, Twitter user comments, and the number of likes for the comments by crawling the news articles through Twitter feeds. The proposed system extracts textual features using a transformer-based textual encoder while the visual features have been extracted using a Faster region-based convolutional neural networks model. The textual and visual features have been concatenated to construct the multimodal features using which the decoder synthesizes the feedback. We have compared the results of the proposed system with the baseline models using quantitative and qualitative measures. The generated feedbacks have been analyzed using automatic and human evaluation. They have been found to be semantically similar to the ground-truth comments and relevant to the given text-image input.
Region extraction based approach for cigarette usage classification using deep learning
Mar 23, 2021


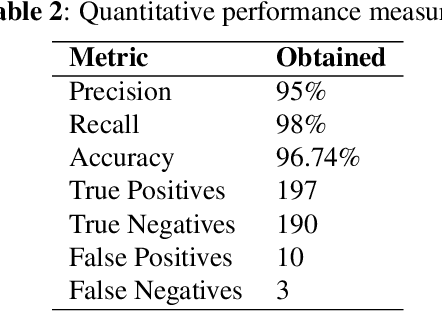
This paper has proposed a novel approach to classify the subjects' smoking behavior by extracting relevant regions from a given image using deep learning. After the classification, we have proposed a conditional detection module based on Yolo-v3, which improves model's performance and reduces its complexity. As per the best of our knowledge, we are the first to work on this dataset. This dataset contains a total of 2,400 images that include smokers and non-smokers equally in various environmental settings. We have evaluated the proposed approach's performance using quantitative and qualitative measures, which confirms its effectiveness in challenging situations. The proposed approach has achieved a classification accuracy of 96.74% on this dataset.