 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Sentiment-Controlled Feedback For Multimodal Text and Image Data
Feb 12, 2024The ability to generate sentiment-controlled feedback in response to multimodal inputs, comprising both text and images, addresses a critical gap in human-computer interaction by enabling systems to provide empathetic, accurate, and engaging responses. This capability has profound applications in healthcare, marketing, and education. To this end, we construct a large-scale Controllable Multimodal Feedback Synthesis (CMFeed) dataset and propose a controllable feedback synthesis system. The proposed system includes an encoder, decoder, and controllability block for textual and visual inputs. It extracts textual and visual features using a transformer and Faster R-CNN networks and combines them to generate feedback. The CMFeed dataset encompasses images, text, reactions to the post, human comments with relevance scores, and reactions to the comments. The reactions to the post and comments are utilized to train the proposed model to produce feedback with a particular (positive or negative) sentiment. A sentiment classification accuracy of 77.23% has been achieved, 18.82% higher than the accuracy without using the controllability. Moreover, the system incorporates a similarity module for assessing feedback relevance through rank-based metrics. It implements an interpretability technique to analyze the contribution of textual and visual features during the generation of uncontrolled and controlled feedback.
Interpretable Multimodal Emotion Recognition using Hybrid Fusion of Speech and Image Data
Aug 25, 2022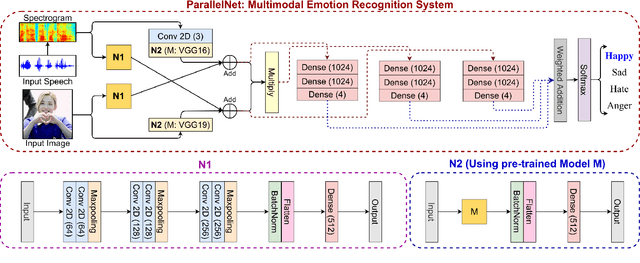
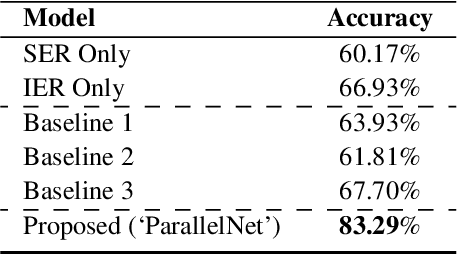
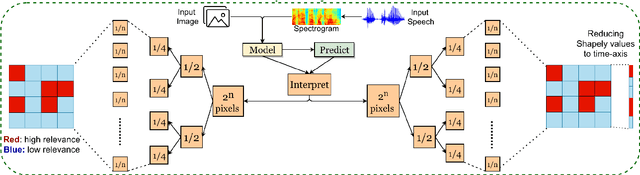

This paper proposes a multimodal emotion recognition system based on hybrid fusion that classifies the emotions depicted by speech utterances and corresponding images into discrete classes. A new interpretability technique has been developed to identify the important speech & image features leading to the prediction of particular emotion classes. The proposed system's architecture has been determined through intensive ablation studies. It fuses the speech & image features and then combines speech, image, and intermediate fusion outputs. The proposed interpretability technique incorporates the divide & conquer approach to compute shapely values denoting each speech & image feature's importance. We have also constructed a large-scale dataset (IIT-R SIER dataset), consisting of speech utterances, corresponding images, and class labels, i.e., 'anger,' 'happy,' 'hate,' and 'sad.' The proposed system has achieved 83.29% accuracy for emotion recognition. The enhanced performance of the proposed system advocates the importance of utilizing complementary information from multiple modalities for emotion recognition.
Hybrid Fusion Based Interpretable Multimodal Emotion Recognition with Insufficient Labelled Data
Aug 24, 2022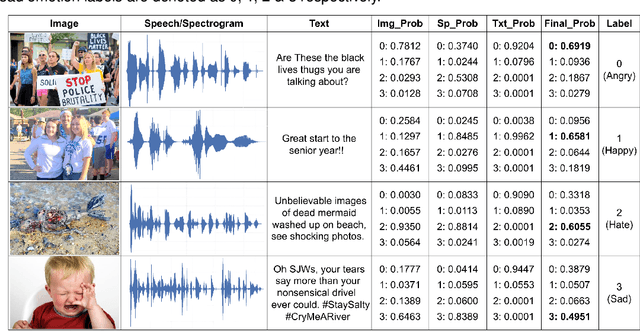
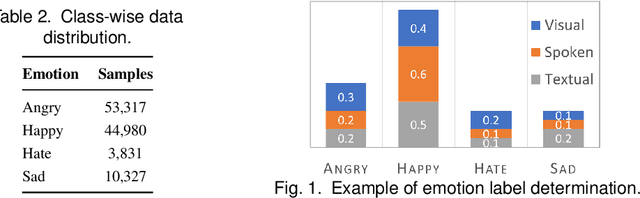
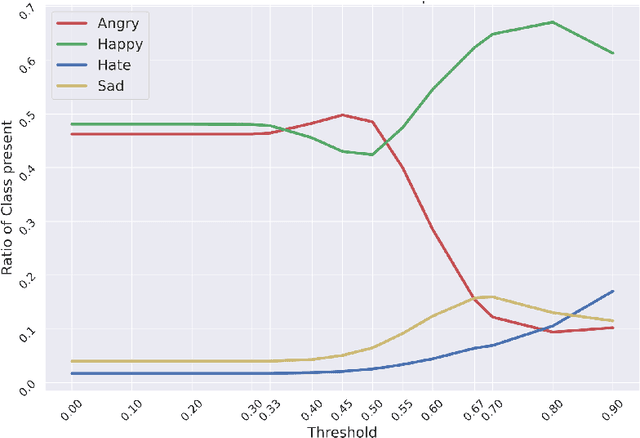
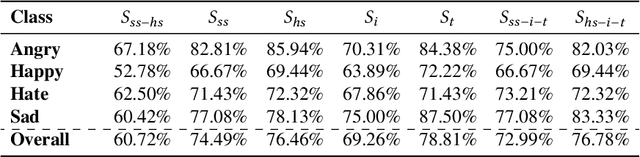
This paper proposes a multimodal emotion recognition system, VIsual Spoken Textual Additive Net (VISTA Net), to classify the emotions reflected by a multimodal input containing image, speech, and text into discrete classes. A new interpretability technique, K-Average Additive exPlanation (KAAP), has also been developed to identify the important visual, spoken, and textual features leading to predicting a particular emotion class. The VISTA Net fuses the information from image, speech & text modalities using a hybrid of early and late fusion. It automatically adjusts the weights of their intermediate outputs while computing the weighted average without human intervention. The KAAP technique computes the contribution of each modality and corresponding features toward predicting a particular emotion class. To mitigate the insufficiency of multimodal emotion datasets labeled with discrete emotion classes, we have constructed a large-scale IIT-R MMEmoRec dataset consisting of real-life images, corresponding speech & text, and emotion labels ('angry,' 'happy,' 'hate,' and 'sad.'). The VISTA Net has resulted in 95.99% emotion recognition accuracy on considering image, speech, and text modalities, which is better than the performance on considering the inputs of any one or two modalities.