 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-FEDSOFIM: Differentially Private Federated Stochastic Optimization using Regularized Fisher Information Matrix
Jan 14, 2026Differentially private federated learning (DP-FL) suffers from slow convergence under tight privacy budgets due to the overwhelming noise introduced to preserve privacy. While adaptive optimizers can accelerate convergence, existing second-order methods such as DP-FedNew require O(d^2) memory at each client to maintain local feature covariance matrices, making them impractical for high-dimensional models. We propose DP-FedSOFIM, a server-side second-order optimization framework that leverages the Fisher Information Matrix (FIM) as a natural gradient preconditioner while requiring only O(d) memory per client. By employing the Sherman-Morrison formula for efficient matrix inversion, DP-FedSOFIM achieves O(d) computational complexity per round while maintaining the convergence benefits of second-order methods. Our analysis proves that the server-side preconditioning preserves (epsilon, delta)-differential privacy through the post-processing theorem. Empirical evaluation on CIFAR-10 demonstrates that DP-FedSOFIM achieves superior test accuracy compared to first-order baselines across multiple privacy regimes.
FedDPC : Handling Data Heterogeneity and Partial Client Participation in Federated Learning
Dec 23, 2025Data heterogeneity is a significant challenge in modern federated learning (FL) as it creates variance in local model updates, causing the aggregated global model to shift away from the true global optimum. Partial client participation in FL further exacerbates this issue by skewing the aggregation of local models towards the data distribution of participating clients. This creates additional variance in the global model updates, causing the global model to converge away from the optima of the global objective. These variances lead to instability in FL training, which degrades global model performance and slows down FL training. While existing literature primarily focuses on addressing data heterogeneity, the impact of partial client participation has received less attention. In this paper, we propose FedDPC, a novel FL method, designed to improve FL training and global model performance by mitigating both data heterogeneity and partial client participation. FedDPC addresses these issues by projecting each local update onto the previous global update, thereby controlling variance in both local and global updates. To further accelerate FL training, FedDPC employs adaptive scaling for each local update before aggregation. Extensive experiments on image classification tasks with multiple heterogeneously partitioned datasets validate the effectiveness of FedDPC. The results demonstrate that FedDPC outperforms state-of-the-art FL algorithms by achieving faster reduction in training loss and improved test accuracy across communication rounds.
pFedSOP : Accelerating Training Of Personalized Federated Learning Using Second-Order Optimization
Jun 08, 2025Personalized Federated Learning (PFL) enables clients to collaboratively train personalized models tailored to their individual objectives, addressing the challenge of model generalization in traditional Federated Learning (FL) due to high data heterogeneity. However, existing PFL methods often require increased communication rounds to achieve the desired performance, primarily due to slow training caused by the use of first-order optimization, which has linear convergence. Additionally, many of these methods increase local computation because of the additional data fed into the model during the search for personalized local models. One promising solution to this slow training is second-order optimization, known for its quadratic convergence. However, employing it in PFL is challenging due to the Hessian matrix and its inverse. In this paper, we propose pFedSOP, which efficiently utilizes second-order optimization in PFL to accelerate the training of personalized models and enhance performance with fewer communication rounds. Our approach first computes a personalized local gradient update using the Gompertz function-based normalized angle between local and global gradient updates, incorporating client-specific global information. We then use a regularized Fisher Information Matrix (FIM), computed from this personalized gradient update, as an approximation of the Hessian to update the personalized models. This FIM-based second-order optimization speeds up training with fewer communication rounds by tackling the challenges with exact Hessian and avoids additional data being fed into the model during the search for personalized local models. Extensive experiments on heterogeneously partitioned image classification datasets with partial client participation demonstrate that pFedSOP outperforms state-of-the-art FL and PFL algorithms.
Accelerated Training of Federated Learning via Second-Order Methods
May 29, 2025

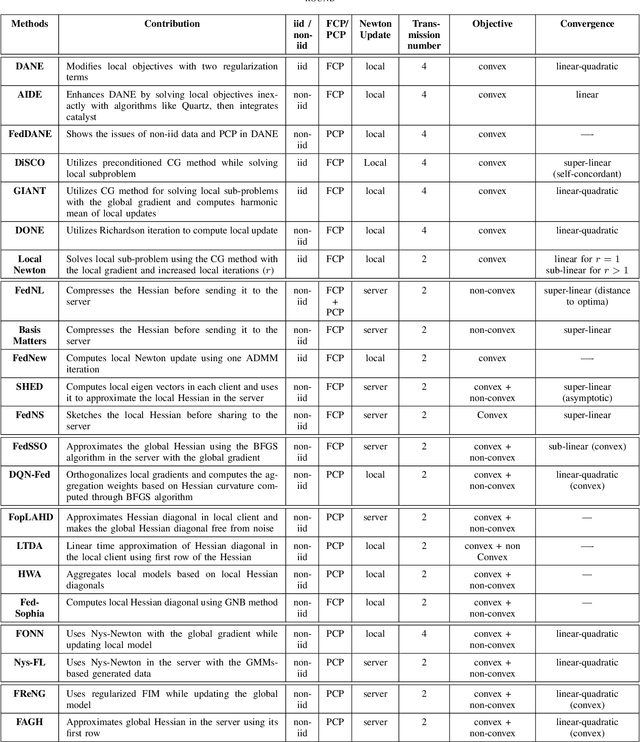

This paper explores second-order optimization methods in Federated Learning (FL), addressing the critical challenges of slow convergence and the excessive communication rounds required to achieve optimal performance from the global model. While existing surveys in FL primarily focus on challenges related to statistical and device label heterogeneity, as well as privacy and security concerns in first-order FL methods, less attention has been given to the issue of slow model training. This slow training often leads to the need for excessive communication rounds or increased communication costs, particularly when data across clients are highly heterogeneous. In this paper, we examine various FL methods that leverage second-order optimization to accelerate the training process. We provide a comprehensive categorization of state-of-the-art second-order FL methods and compare their performance based on convergence speed, computational cost, memory usage, transmission overhead, and generalization of the global model. Our findings show the potential of incorporating Hessian curvature through second-order optimization into FL and highlight key challenges, such as the efficient utilization of Hessian and its inverse in FL. This work lays the groundwork for future research aimed at developing scalable and efficient federated optimization methods for improving the training of the global model in FL.
HateTinyLLM : Hate Speech Detection Using Tiny Large Language Models
Apr 26, 2024



Hate speech encompasses verbal, written, or behavioral communication that targets derogatory or discriminatory language against individuals or groups based on sensitive characteristics. Automated hate speech detection plays a crucial role in curbing its propagation, especially across social media platforms. Various methods, including recent advancements in deep learning, have been devised to address this challenge. In this study, we introduce HateTinyLLM, a novel framework based on fine-tuned decoder-only tiny large language models (tinyLLMs) for efficient hate speech detection. Our experimental findings demonstrate that the fine-tuned HateTinyLLM outperforms the pretrained mixtral-7b model by a significant margin. We explored various tiny LLMs, including PY007/TinyLlama-1.1B-step-50K-105b, Microsoft/phi-2, and facebook/opt-1.3b, and fine-tuned them using LoRA and adapter methods. Our observations indicate that all LoRA-based fine-tuned models achieved over 80\% accuracy.
FAGH: Accelerating Federated Learning with Approximated Global Hessian
Mar 16, 2024



In federated learning (FL), the significant communication overhead due to the slow convergence speed of training the global model poses a great challenge. Specifically, a large number of communication rounds are required to achieve the convergence in FL. One potential solution is to employ the Newton-based optimization method for training, known for its quadratic convergence rate. However, the existing Newton-based FL training methods suffer from either memory inefficiency or high computational costs for local clients or the server. To address this issue, we propose an FL with approximated global Hessian (FAGH) method to accelerate FL training. FAGH leverages the first moment of the approximated global Hessian and the first moment of the global gradient to train the global model. By harnessing the approximated global Hessian curvature, FAGH accelerates the convergence of global model training, leading to the reduced number of communication rounds and thus the shortened training time. Experimental results verify FAGH's effectiveness in decreasing the number of communication rounds and the time required to achieve the pre-specified objectives of the global model performance in terms of training and test losses as well as test accuracy. Notably, FAGH outperforms several state-of-the-art FL training methods.
SOFIM: Stochastic Optimization Using Regularized Fisher Information Matrix
Mar 05, 2024



This paper introduces a new stochastic optimization method based on the regularized Fisher information matrix (FIM), named SOFIM, which can efficiently utilize the FIM to approximate the Hessian matrix for finding Newton's gradient update in large-scale stochastic optimization of machine learning models. It can be viewed as a variant of natural gradient descent (NGD), where the challenge of storing and calculating the full FIM is addressed through making use of the regularized FIM and directly finding the gradient update direction via Sherman-Morrison matrix inversion. Additionally, like the popular Adam method, SOFIM uses the first moment of the gradient to address the issue of non-stationary objectives across mini-batches due to heterogeneous data. The utilization of the regularized FIM and Sherman-Morrison matrix inversion leads to the improved convergence rate with the same space and time complexities as stochastic gradient descent (SGD) with momentum. The extensive experiments on training deep learning models on several benchmark image classification datasets demonstrate that the proposed SOFIM outperforms SGD with momentum and several state-of-the-art Newton optimization methods, such as Nystrom-SGD, L-BFGS, and AdaHessian, in term of the convergence speed for achieving the pre-specified objectives of training and test losses as well as test accuracy.