 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Models as Zero-Annotation Oracles in Histopathology
Jun 15, 2026Foreground segmentation is the critical first step of every computational pathology pipeline, yet existing methods rely on hand-tuned heuristics or supervised models that overfit to narrow stain and scanner distributions, failing silently on specialised stains such as Jones silver or Elastica van Gieson. We propose a coarse-to-fine approach that recasts foreground segmentation as a visual perception task and leverages general-purpose vision-language models (VLMs) as zero-annotation oracles. Our key insight is that tissue-versus-background discrimination is a natural-image recognition problem, not a histopathological one, so VLMs trained on internet-scale corpora generalise where domain-specific models cannot. We introduce Leica-75, a benchmark of 75 renal transplant whole-slide images spanning three stain families. On Leica-75, our method achieves the highest segmentation quality on out-of-distribution stains (Dice 0.858 +/- 0.027 on Jones, 0.853 +/- 0.041 on EVG) with 7x lower cross-stain variance than the best supervised baseline, while remaining competitive on in-distribution H&E. Few-shot prompting with automatically curated exemplars (Auto-context) rescues hard cases on Stress-32 (n=32), a curated stress-test subset (Dice 0.470 to 0.819 for the 2B model). VLM-based annotation review matches human expert consensus (kappa=0.989 for blur detection; mean precision/recall grading accuracy 0.708 vs. human 0.646 for segmentation mask review). The resulting pseudo-labels are used to distil lightweight student models that are as performant as the teacher model while running for a fraction of the cost. Our framework provides a principled, scalable solution to a persistent infrastructure bottleneck in digital pathology.
Learning to Infer Unobserved Behaviors: Estimating User's Preference for a Site over Other Sites
Dec 15, 2023A site's recommendation system relies on knowledge of its users' preferences to offer relevant recommendations to them. These preferences are for attributes that comprise items and content shown on the site, and are estimated from the data of users' interactions with the site. Another form of users' preferences is material too, namely, users' preferences for the site over other sites, since that shows users' base level propensities to engage with the site. Estimating users' preferences for the site, however, faces major obstacles because (a) the focal site usually has no data of its users' interactions with other sites; these interactions are users' unobserved behaviors for the focal site; and (b) the Machine Learning literature in recommendation does not offer a model of this situation. Even if (b) is resolved, the problem in (a) persists since without access to data of its users' interactions with other sites, there is no ground truth for evaluation. Moreover, it is most useful when (c) users' preferences for the site can be estimated at the individual level, since the site can then personalize recommendations to individual users. We offer a method to estimate individual user's preference for a focal site, under this premise. In particular, we compute the focal site's share of a user's online engagements without any data from other sites. We show an evaluation framework for the model using only the focal site's data, allowing the site to test the model. We rely upon a Hierarchical Bayes Method and perform estimation in two different ways - Markov Chain Monte Carlo and Stochastic Gradient with Langevin Dynamics. Our results find good support for the approach to computing personalized share of engagement and for its evaluation.
A Comprehensive Review on Digital Image Watermarking
Jul 07, 2022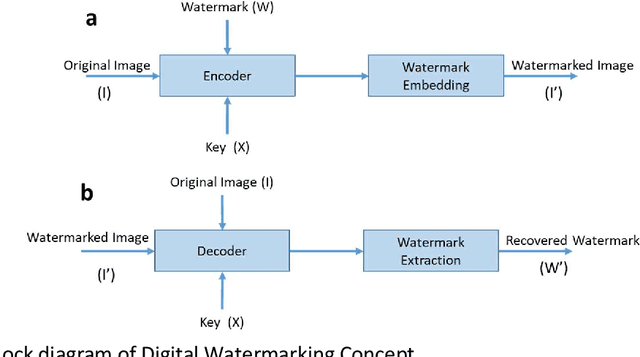
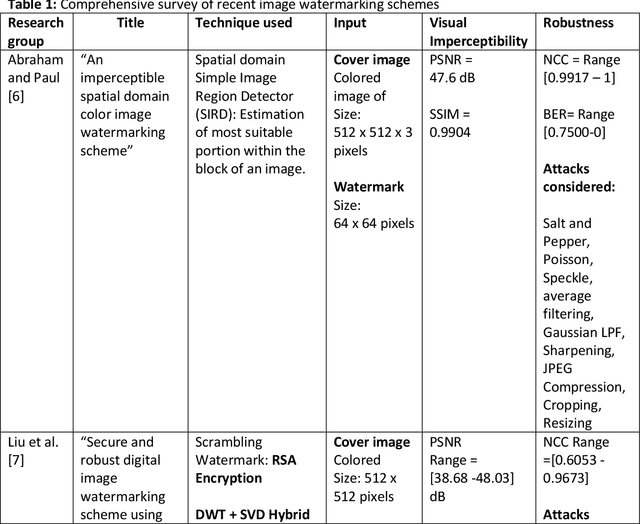
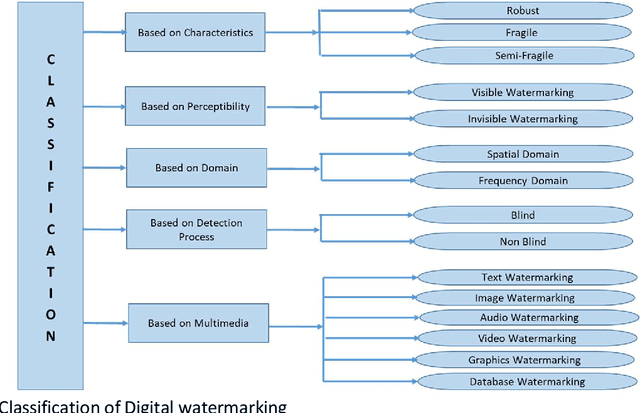
The advent of the Internet led to the easy availability of digital data like images, audio, and video. Easy access to multimedia gives rise to the issues such as content authentication, security, copyright protection, and ownership identification. Here, we discuss the concept of digital image watermarking with a focus on the technique used in image watermark embedding and extraction of the watermark. The detailed classification along with the basic characteristics, namely visual imperceptibility, robustness, capacity, security of digital watermarking is also presented in this work. Further, we have also discussed the recent application areas of digital watermarking such as healthcare, remote education, electronic voting systems, and the military. The robustness is evaluated by examining the effect of image processing attacks on the signed content and the watermark recoverability. The authors believe that the comprehensive survey presented in this paper will help the new researchers to gather knowledge in this domain. Further, the comparative analysis can enkindle ideas to improve upon the already mentioned techniques.
Algorithmic Improvements for Deep Reinforcement Learning applied to Interactive Fiction
Nov 28, 2019

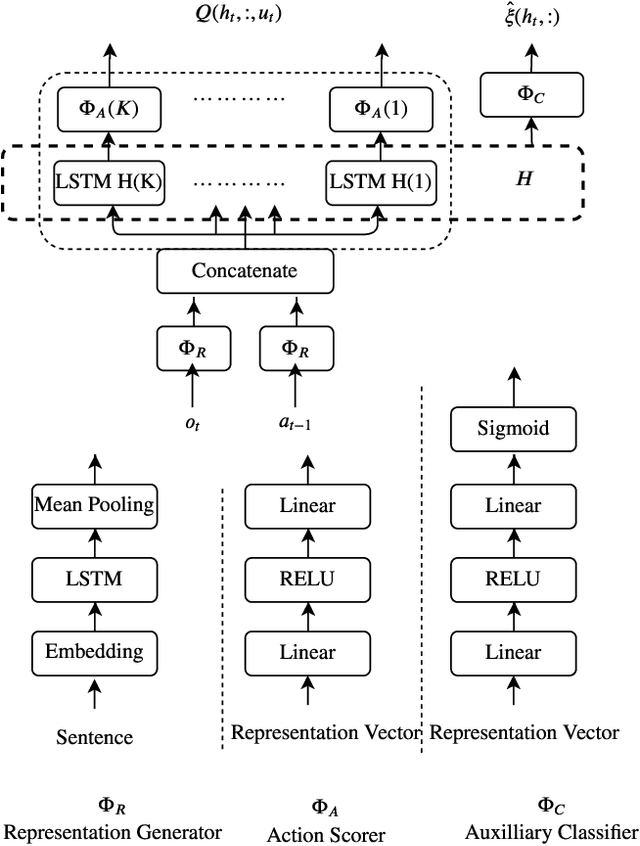

Text-based games are a natural challenge domain for deep reinforcement learning algorithms. Their state and action spaces are combinatorially large, their reward function is sparse, and they are partially observable: the agent is informed of the consequences of its actions through textual feedback. In this paper we emphasize this latter point and consider the design of a deep reinforcement learning agent that can play from feedback alone. Our design recognizes and takes advantage of the structural characteristics of text-based games. We first propose a contextualisation mechanism, based on accumulated reward, which simplifies the learning problem and mitigates partial observability. We then study different methods that rely on the notion that most actions are ineffectual in any given situation, following Zahavy et al.'s idea of an admissible action. We evaluate these techniques in a series of text-based games of increasing difficulty based on the TextWorld framework, as well as the iconic game Zork. Empirically, we find that these techniques improve the performance of a baseline deep reinforcement learning agent applied to text-based games.
Contextual Bandits Evolving Over Finite Time
Nov 14, 2019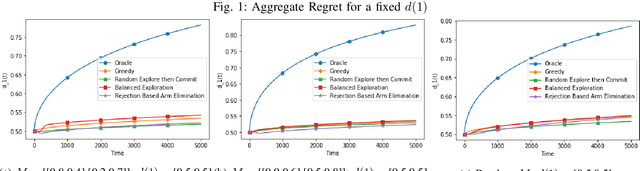

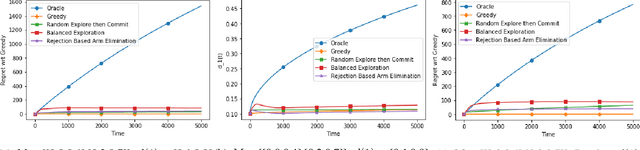
Contextual bandits have the same exploration-exploitation trade-off as standard multi-armed bandits. On adding positive externalities that decay with time, this problem becomes much more difficult as wrong decisions at the start are hard to recover from. We explore existing policies in this setting and highlight their biases towards the inherent reward matrix. We propose a rejection based policy that achieves a low regret irrespective of the structure of the reward probability matrix.
Ontology Based Pivoted normalization using Vector Based Approach for information Retrieval
Mar 21, 2017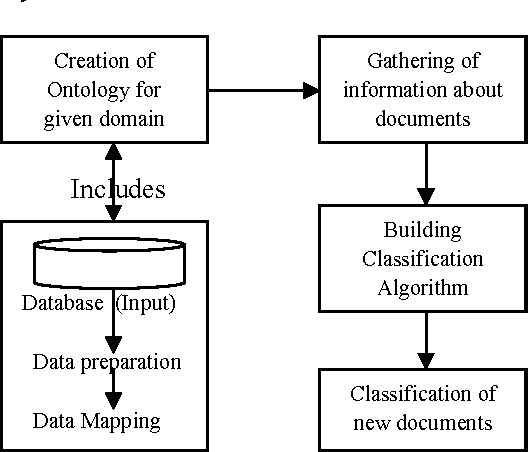
The proposed methodology is procedural i.e. it follows finite number of steps that extracts relevant documents according to users query. It is based on principles of Data Mining for analyzing web data. Data Mining first adapts integration of data to generate warehouse. Then, it extracts useful information with the help of algorithm. The task of representing extracted documents is done by using Vector Based Statistical Approach that represents each document in set of Terms.
Improving Statistical Multimedia Information Retrieval Model by using Ontology
Mar 21, 2017A typical IR system that delivers and stores information is affected by problem of matching between user query and available content on web. Use of Ontology represents the extracted terms in form of network graph consisting of nodes, edges, index terms etc. The above mentioned IR approaches provide relevance thus satisfying users query. The paper also emphasis on analyzing multimedia documents and performs calculation for extracted terms using different statistical formulas. The proposed model developed reduces semantic gap and satisfies user needs efficiently.